ICLR 2026, (International Conference on Learning Representations) 国际学习表征会议,是机器学习与深度学习领域的顶级会议,关注有关深度学习各个方面的前沿研究,在人工智能、统计和数据科学领域以及机器视觉、语音识别、文本理解等重要应用领域中发布了众多极其有影响力的论文。会议具有广泛且深远的国际影响力,居谷歌学术人工智能会议影响力排行榜前列,与 NeurIPS、ICML 并称为机器学习领域三大顶会。 ICLR 2026 将于2026年4月23日至4月27日在巴西里约热内卢举办。厦门大学媒体分析与计算实验室共5篇论文被录用。
1. FlashWorld: High-quality 3D Scene Generation within Seconds (Oral)
本文提出了 FlashWorld,这是一种能够在几秒钟内从单张图像或文本提示生成 3D 场景生成模型,比以往的研究快十倍到百倍,同时具有更出色的渲染质量。本文方法从传统的多视图导向范式转变为 3D 导向方法,前者生成多视图图像用于后续的 3D 重建,而后者中模型在多视图生成过程中直接生成 3D 高斯表示。尽管 3D 导向方法能确保 3D 一致性,但它通常存在视觉质量不佳的问题。FlashWorld 包含一个双模式预训练阶段和随后的跨模式后训练阶段,有效地融合了两种范式的优势。具体而言,利用视频扩散模型的先验知识,首先预训练一个双模式多视图扩散模型,该模型同时支持多视图导向和 3D 导向的生成模式。为了弥合 3D 导向生成中的质量差距,进一步提出了一种跨模式后训练蒸馏方法,通过将一致性 3D 导向模式的分布与高质量多视图导向模式的分布进行匹配来实现。这不仅在保持 3D 一致性的同时提升了视觉质量,还减少了推理所需的去噪步骤。此外,本文提出了一种策略,在这一过程中利用大量单视图图像和文本提示,以增强模型对分布外输入的泛化能力。大量实验证明了本文方法的优越性和高效性。本文全部代码已开源。
该论文第一作者是厦门大学信息学院2023级博士生李新阳,通讯作者是曹刘娟教授,由王腾飞(腾讯混元)、顾子潇(复旦大学)、张声传副教授、腾讯混元(复旦大学)郭春超合作完成。

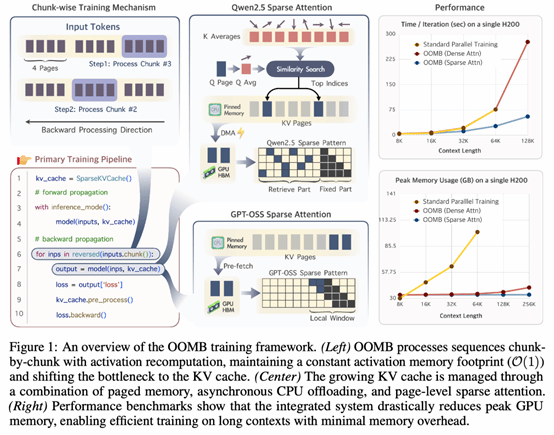
2. Out of the Memory Barrier: A Highly Memory Efficient Training System for LLMs with Million-Token Contexts
本文提出了名为OOMB的训练系统,旨在解决长上下文大语言模型训练中的显存瓶颈问题。它通过分块循环训练和激活重计算技术,将激活显存占用降低为常数级,并结合分页KV缓存管理、异步CPU卸载以及页级稀疏注意力机制,有效解决了随序列长度增长的KV缓存压力。实验表明,OOMB能显著降低显存开销,实现了在单张H200 GPU上训练拥有400万token上下文的Qwen2.5-7B模型,打破了传统方法对庞大GPU集群的依赖。
该论文的第一作者是厦门大学信息学院2023级硕士生李文昊,通讯作者是纪荣嵘教授,由余道海,罗根博士,张玉鑫博士,吴一凡(北京大学),刘家昕(伊利诺伊大学香槟分校),龚子洋(上海交通大学),廖子牧(上海交通大学),晁飞副教授共同合作完成。
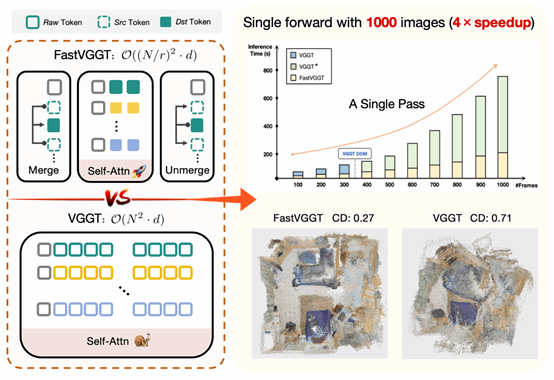
3. FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
本文对前馈视觉几何模型在长序列图像输入下推理效率低、全局注意力计算成本高且易产生误差累积的问题展开研究,通过组件级性能分析确定VGGT的全局注意力模块为核心瓶颈,并发现其注意力图存在高度相似的令牌冗余/坍缩现象;鉴于现有2D视觉的令牌合并技术无法直接适配3D重建的任务特性,论文首次将令牌合并引入3D前馈视觉几何模型,提出了无训练的加速框架FastVGGT,设计了适配3D架构与任务的令牌划分策略,并对原VGGT做显存优化以支持超1000帧的长序列输入。实验表明,FastVGGT在处理1000张输入图像时实现了4倍的推理加速,解决了原VGGT的显存溢出问题,同时在相机位姿估计和点云重建任务中保持了与基线模型相当的精度,还有效缓解了长序列场景中的误差累积;该研究不仅明确了VGGT的推理瓶颈,验证了令牌合并在3D视觉模型中的适用性,也为构建可扩展的3D视觉系统提供了一种合理的解决方案。
该论文的第一作者是厦门大学信息学院2024级博士生沈优,通讯作者是曹刘娟教授,由张志鹏助理教授(上海交通大学)、2023级博士生曲延松、郑侠武副教授、纪家沂副教授、张声传副教授,曹刘娟教授共同合作完成。
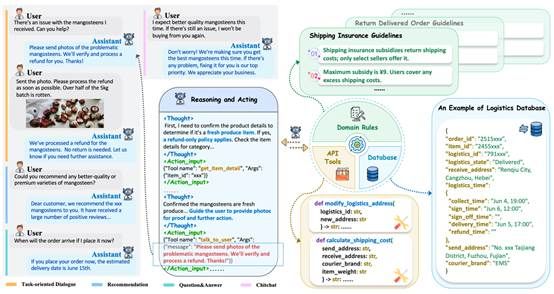
4. Mix-Ecom: Towards Mixed-Type E-Commerce Dialogues with Complex Domain Rules
大语言模型的发展推动了电商智能客服的研发,各类评测Benchmark也相继出现,但现有Benchmark仅能评估模型处理单一对话类型和简单领域规则的能力,无法适配真实电商场景中混合式对话、复杂规则约束的需求,导致模型易产生幻觉、表现不佳。为此,本文构建了 Mix-ECom 混合式电商对话数据集,该数据集基于 7 万条真实客服对话加工而成,含 4799 条高质量样本,覆盖问答、推荐等 4 种对话类型及售前、物流、售后全电商链路,配套 82 项复杂电商领域规则、API 工具集和业务数据库,并经隐私脱敏、添加思维链、人工筛选等多轮处理保障数据质量。同时,本文提出融合Dynamic module的 E-ReAct 和 E-Plan&Solve 电商agent framework,通过动态筛选相关规则、优化推理轨迹,剔除无关信息干扰,缓解模型幻觉问题。基于 Mix-ECom 对 GPT-4o、Gemini-2.5-Pro 等主流闭源及开源模型的评估显示,最优的 Gemini-2.5-Pro 综合得分仅 62.2%,现有电商模型在混合式对话和复杂规则处理上仍有巨大提升空间;而所提动态框架能在各模型上实现性能提升,基于该数据集的微调也让开源模型 Qwen-2.5-VL-7B 性能显著改善,验证了 Mix-ECom 数据集的有效性,也为电商智能Agent的研发提供了高质量Benchmark和技术参考。
该论文第一作者是厦门大学人工智能研究院2023级硕士生周陈昱,通讯作者是郑侠武副教授,由施晓明(华东师范大学)、邱辉(快手科技)、冷海涛(快手科技)、江彦开(华东师范大学)、刘绍国(快手科技)、高婷婷(快手科技)、纪荣嵘教授等共同合作完成。
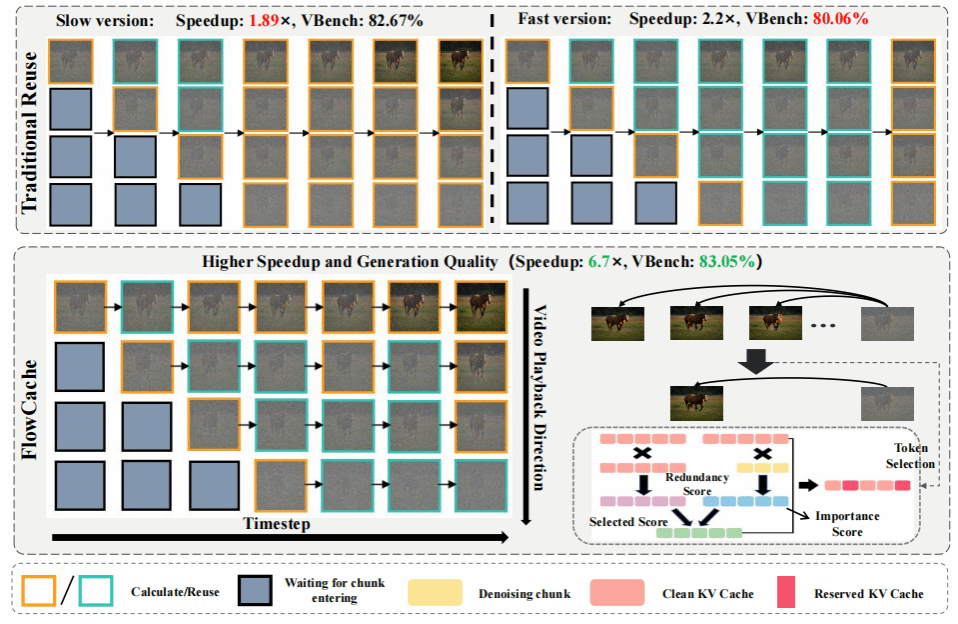
5. Flow caching for autoregressive video generation
针对自回归视频生成中现有缓存复用方法(如TeaCache)因依赖"同步去噪"假设而忽视块间降噪状态异质性、导致质量下降或加速受限的痛点,以及KV Cache快速膨胀引发的显存与计算瓶颈,我们提出了FlowCache——首个专为自回归视频生成设计的缓存加速框架。该框架创新性地引入块级自适应缓存策略,使每个视频块能依据自身降噪状态动态决策是否复用缓存,突破传统"一刀切"策略的局限;同时通过联合建模特征重要性与冗余度,并结合矩阵乘法的线性性质巧妙重组计算顺序,在有限显存预算下实现更高效、高质量的信息保留。实验表明,FlowCache在MAGI-1和SkyReels-V2模型上分别实现2.4倍与6.7倍的推理加速,且生成质量几乎无损,显著推动长视频生成的高效落地。
该论文第一作者是厦门大学人工智能研究院2022级博士生马跃萧和2025级硕士生郑旭哲、2024级硕士生许靖,通讯作者是纪荣嵘教授,由2023级硕士生许希威、凌峰(字节跳动)、郑侠武副教授、匡华峰(字节跳动)、李慧霞(字节跳动)、王星(字节跳动)、肖学锋(字节跳动)、晁飞副教授共同合作完成。