IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR)是人工智能领域的顶级国际会议,CCF A类会议。CVPR 2026 将于2026年6月3日-6月7日在美国丹佛举办,共有16,092篇论文进入评审流程,最终4090篇被接收,录取率为25.42%。厦门大学媒体分析与计算实验室共有十篇论文被录用,录用论文简要介绍如下:
1. Grounded Chain-of-Thought for Multimodal Large Language Models
尽管多模态大语言模型取得了显著进展,但在视觉-空间推理方面仍存在明显不足,这严重制约了其在具身AI等场景中的可信应用。本文提出Grounded Chain-of-Thought (GCoT)任务,旨在通过逐步识别和定位相关视觉线索来提升模型的视觉-空间推理能力,每一步推理都以定位坐标作为直观依据。为支撑该任务,本文构建了MM-GCoT基准数据集,并建立了包含答案准确性、定位准确性和答案-定位一致性的综合评估体系。在12个先进MLLMs上的大量实验揭示了三个重要发现:多数模型在一致性评估上表现不佳,显示出明显的视觉幻觉问题;视觉幻觉与模型参数规模和通用多模态性能无直接关联;更大更强的模型并未显著减少视觉幻觉现象。本研究为评估和改进多模态大语言模型的视觉-空间推理能力提供了新的视角和工具,揭示了当前模型在可信度方面的关键缺陷。
该论文第一作者是厦门大学人工智能研究院2022级博士生吴穹,通讯作者是纪荣嵘教授,由2024级硕士生杨祥聪、2025级硕士生方晨鑫、2025级硕士生宋柏杨、周奕毅副教授、孙晓帅教授共同合作完成。

2. MICON-Bench: Benchmarking and Enhancing Multi-Image Context Image Generation in Unified Multimodal Models
在统一多模态模型(UMMs)飞速发展的今天,图像理解与生成能力已取得显著突破。然而,尽管如 Gemini 等模型已展现出对多张相关图像的推理能力,现有的基准测试仍主要局限于文本生成图像(T2I)或单图编辑任务,难以有效评估“多图像上下文生成”这一新兴领域的挑战。本文提出了一种全新的基准测试——MICON-Bench,旨在全面评估和提升模型在多图像语境下的生成能力。MICON-Bench 包含六大核心任务,涵盖了从基础的物体组合、属性迁移,到高阶的视觉故事生成等复杂场景,重点考察模型在跨图像组合、上下文推理及身份保持方面的表现。为了解决评估难题,本文设计了一套由多模态大语言模型(MLLM)驱动的“检查点评估”框架,能够自动且客观地验证生成内容在语义和视觉上的一致性。此外,针对现有模型在处理多图像输入时容易出现的注意力分散和幻觉问题,本文提出了一种名为动态注意力重平衡的创新机制。DAR 是一种无需训练、即插即用的方法,它能在推理过程中动态识别并增强与任务相关的图像区域关注度,同时抑制无关干扰。实验结果表明,MICON-Bench 有效揭示了当前最先进模型在多图像推理中的短板,而 DAR 显著提升了生成的连贯性与质量。这项工作不仅为多图像上下文生成提供了标准化的评估平台,也为未来更灵活、更精准的多模态生成模型指明了方向。
该论文共同第一作者是厦门大学人工智能研究院 2023 级博士生吴明瑞和信息学院本科生刘航,通讯作者是纪荣嵘教授,由孙晓帅教授、纪家沂副教授等共同合作完成。

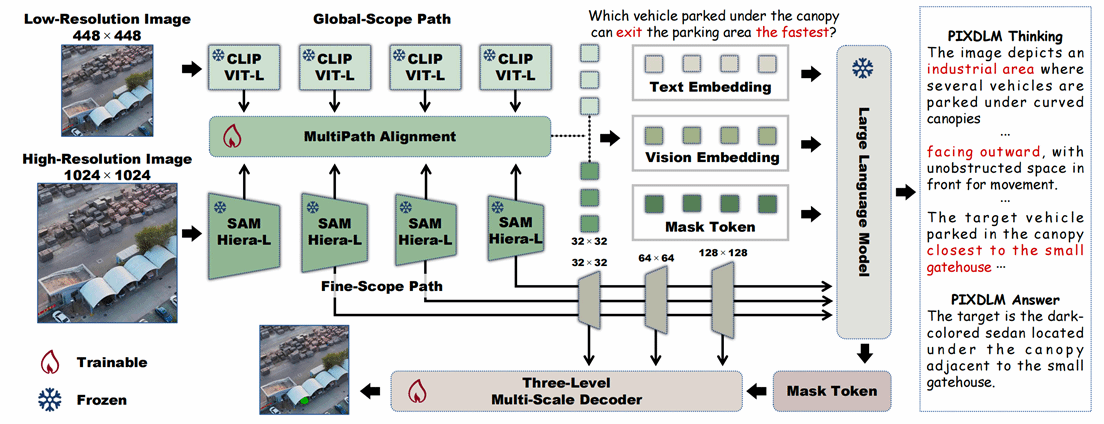
3. PixDLM: A Dual-Path Multimodal Language Model for UAV Reasoning Segmentation
推理分割最近已从地面场景扩展到遥感图像领域,这给无人机影像带来了全新的挑战,如倾斜视角、超高分辨率以及目标极端尺度变化等问题。针对这些无人机数据的特有属性,本文定义了无人机推理分割任务,并将其语义需求归纳为三个层次:空间推理、属性推理与场景级推理。基于这一框架,本文构建了首个大规模无人机推理分割基准DRSeg,其包含了1万张高分辨率航拍图像,并提供了涵盖上述三类推理任务的思维链问答标注。此外,论文进一步提出PixDLM,这是一种像素级多模态大语言模型,配备双路径视觉编码器,能够在保持强大全局语义对齐的同时保留细粒度的高分辨率线索。在DRSeg上的大量实验表明,与现有其他多模态模型相比,PixDLM实现了更优的语义一致性和空间定位精度,为无人机推理分割建立了统一高效的基准。
该论文第一作者是厦门大学人工智能研究院2024级硕士生柯殊言,通讯作者是纪荣嵘教授,由2025级硕士生梅一樊、2024级博士生吴昌鲡、2022级本科生郑永涵、纪家沂副教授、曹刘娟教授共同合作完成。
4. CrackSSM: Reviving SSMs for Crack Segmentation via Dynamic Scanning
本论文针对基础设施与工业场景中裂缝分割任务,提出了名为CrackSSM的新型状态空间模型框架,旨在解决现有Mamba类方法因静态扫描策略破坏空间连续性、难以有效建模不规则裂缝的问题。该工作创新性地引入动态扫描策略,依据高层语义特征的方向响应强度自适应重排token序列,使裂缝区域在序列中保持相邻,从而在保留SSM线性复杂度优势的同时增强其对细粒度裂缝的因果建模能力;同时结合小波引导解码机制,利用图像高频成分指导特征细化与边缘融合,进一步提升分割精度。实验表明,该方法在三个基准数据集上以更少参数量和更快推理速度实现了优于主流模型的精度表现。其现实意义在于:不仅可高效赋能桥梁、隧道、产线设备等场景的自动化巡检与预防性维护,降低人工成本与安全风险,且凭借轻量高效特性易于部署于无人机或嵌入式终端,满足边缘侧实时检测需求;此外,其"结构感知动态序列建模"的设计思路也为其他不规则细长结构分割任务提供了可迁移的技术范式,具有显著的工程应用价值与学术启发意义。
该论文共同第一作者为2023级博士研究生谷雨斌和2022级本科生候博阳,通讯作者为孙晓帅教授。由纪家沂副教授、2024级硕士研究生孟媛,2023级本科生罗文婷共同合作完成。

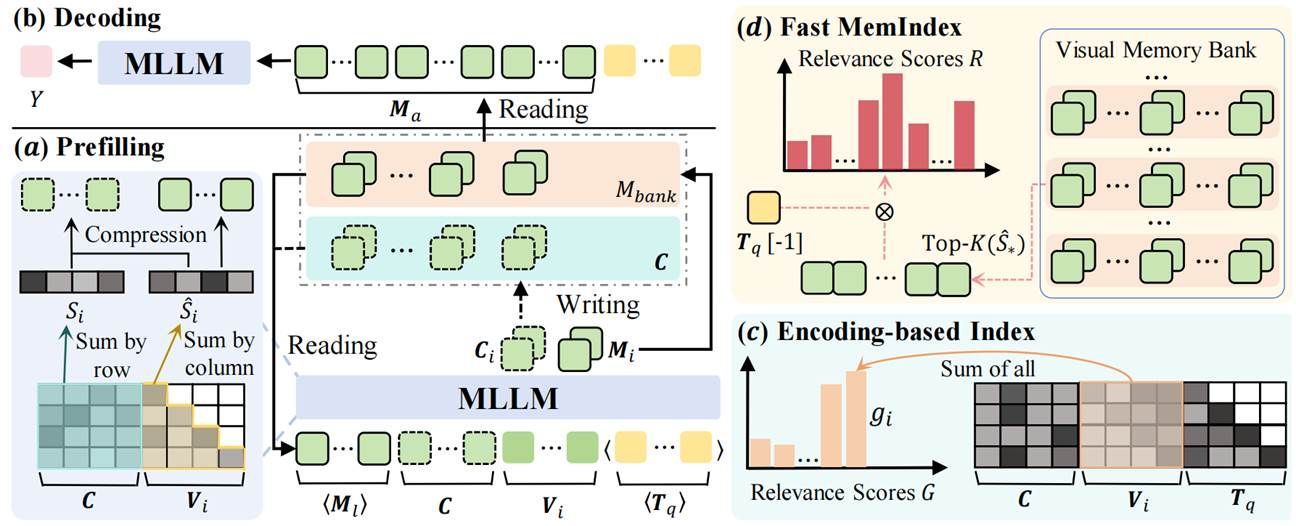
5. Scaling the Long Video Understanding of Multimodal Large Language Models via Visual Memory Mechanism
本文针对多模态大语言模型在长视频理解任务中因输入长度限制和计算开销过大而难以处理海量帧的问题,提出了名为 FlexMem (Flexible Memory) 的新型视觉记忆机制框架。该工作模拟人类看视频时形成连续记忆与回忆关键片段的行为,通过双路径压缩设计将视觉 KVCache转化为传递历史信息的上下文记忆和保留显著特征的局部记忆,实现了在有限显存下对无限长视频序列的迭代处理。同时,针对流式任务中的推理效率瓶颈,论文进一步提出了 MemIndex 快速索引机制,通过自适应选择代表性缓存层与构建轻量化索引,显著降低了从海量信息中检索的计算成本。实验表明,FlexMem实现了使用单张消费级显卡便能处理超过千帧甚至无限长的视频流。其现实意义在于:FlexMem 作为一种无需训练、即插即用的通用组件,不仅极大提升了现有 MLLM 对长达数小时视频的全局理解与细粒度检索能力,且凭借其高效的内存管理特性,证明了通往无限长视频理解的钥匙,不在于无限扩张的上下文窗口,而在于更聪明、更拟人的记忆机制 。
该论文第一作者为厦门大学信息学院人工智能系 2024 级博士研究生陈涛,通讯作者为周奕毅副教授。由2024级硕士研究生章锟、2022级博士研究生吴穹、陈潇博士后研究员和常超讲师(国防科大)共同合作完成。
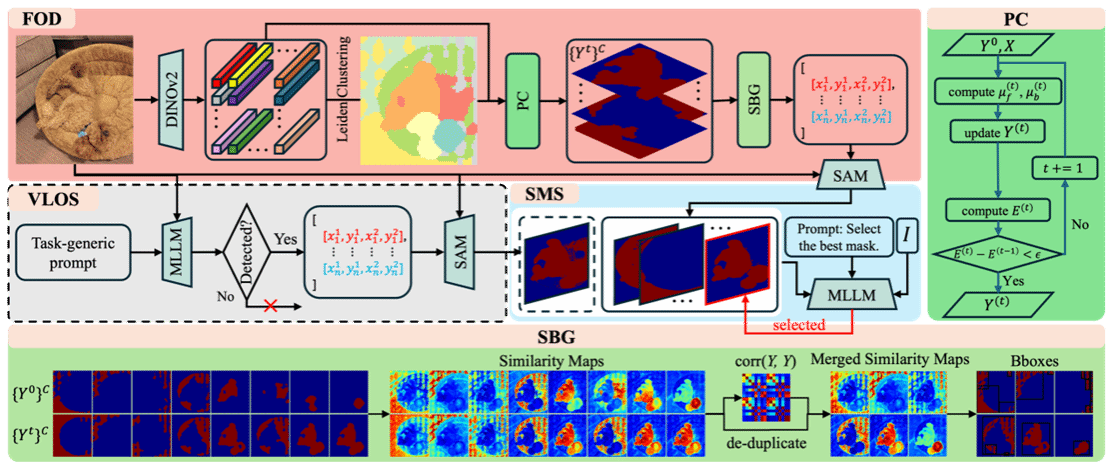
6. Discover, Segment, and Select: A Progressive Mechanism for Zero-shot Camouflaged Object Segmentation
现有的零样本伪装物体分割方法通常采用“先发现后分割”的两阶段流水线:即先利用多模态大语言模型(MLLMs)获取视觉提示,随后进行 SAM(Segment Anything Model)分割。然而,仅依赖 MLLMs 进行伪装物体发现往往会导致定位不准、误报和漏检等问题。为解决这些问题,本文提出了 Discover-Segment-Select (DSS,发现-分割-选择) 机制,这是一种旨在逐步细化分割结果的渐进式框架。该方法包含以下三个核心模块:特征一致性物体发现(FOD)模块:利用视觉特征生成多样化的物体候选提案(proposals);分割模块:通过 SAM 分割对这些提案进行细化;语义驱动掩码选择(SMS)模块:利用 MLLMs 从多个候选掩码中评估并筛选出最佳结果。在无需任何训练或监督的情况下,DSS 在多个 COS 基准测试中均达到了当前最先进的水平,尤其是在多实例场景中表现出色。
该论文第一作者是厦门大学信息学院博士后研究员杨一龙,通讯作者是曹刘娟教授,由2025级硕士生田剑心,张声传副教授共同合作完成。
7. SEA-Vision: A Multilingual Benchmark for Comprehensive Document and Scene Text Understanding in Southeast Asia
本文聚焦多语言文档与场景文本理解在检索、金融和公共服务等应用中的关键作用,指出现有基准多偏向高资源语言,难以在真实多语言环境下评测模型能力。针对东南亚地区语言高度多样、书写系统复杂且文档类型差异显著带来的评测挑战,本文提出了多语言基准 SEA-Vision,面向 11 种东南亚语言,联合评测文档解析(Document Parsing)与以文本为中心的视觉问答(TEC-VQA)。本文构建了两类核心数据:其一为 15,234 页文档解析数据,覆盖 9 类代表性文档,并提供页面级、块级、行级的层次化标注;其二为 7,496 组 TEC-VQA 问答对,系统考察文本识别、数值计算、对比分析、逻辑推理与空间理解等能力。为在多语言、多任务场景下实现可扩展的高质量标注,本文设计了面向文档解析与 TEC-VQA 的混合式标注流水线,结合自动化筛选与评分、基于 MLLM 的辅助标注以及轻量级母语者核验,在显著降低人工成本的同时保证标注质量。进一步的评测结果表明,现有多种主流多模态模型在低资源东南亚语言上的性能明显下降,揭示了多语言文档与场景文本理解的显著差距。本文认为,SEA-Vision 将为推动文档与场景文本理解的全球化研究提供新的视角,促进该领域的持续发展。
该论文共同第一作者是厦门大学人工智能研究院2023级硕士岳鹏飞、赵星然(Shopee)、陈君涛(同济大学),通讯作者是张声传副教授,由2023级博士生林将航、侯鹏(Shopee)、曹刘娟教授等共同合作完成。
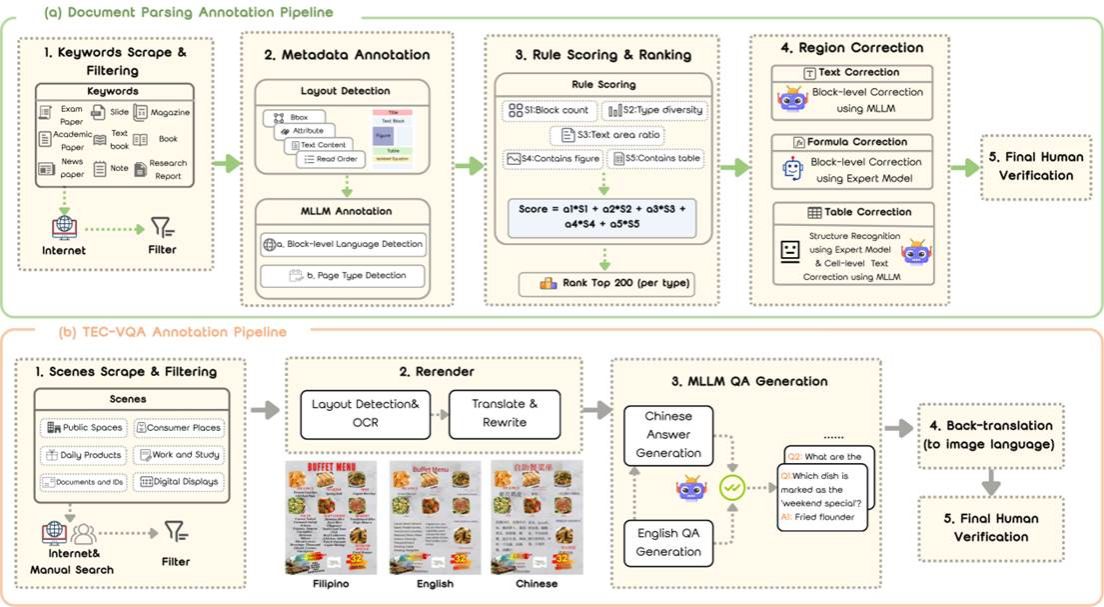
8. CustomTex: High-fidelity Indoor Scene Texturing via Multi-Reference Customization
创建高保真、可定制的3D室内场景纹理仍然是计算机图形学与数字化室内设计领域的一项重大挑战。虽然文本驱动的方法具有灵活性,但缺乏对细粒度实例级控制的精确性,且生成的纹理往往质量不足,存在瑕疵和预渲染阴影。为此,我们推出了CustomTex,这是一个由参考图像驱动的、用于实例级高保真场景纹理生成的新颖框架。CustomTex接收未添加纹理的3D场景以及一组为每个对象实例指定所需外观的参考图像,并生成统一的高分辨率纹理贴图。我们方法的核心是一种双蒸馏方法,可以将语义控制与像素级增强分离。我们采用配备了实例交叉注意力的语义级蒸馏技术,以确保语义合理性以及“参考-实例”对齐,并采用像素级蒸馏技术来确保高视觉保真度。语义控制和像素级增强两种机制被整合到同一个基于变分分数蒸馏的优化过程中。实验表明,CustomTex能够与参考图像实现精确的实例级一致性,并生成具有更高清晰度、更少瑕疵和最少预渲染阴影的纹理。本文工作为高质量、可定制的3D场景外观编辑开辟了一条更直接、更便捷的途径。
该论文第一作者为厦门大学2024级硕士研究生陈伟林,通讯作者为程轩助理教授。由2024级硕士研究生饶家豪、王文昊,2023级博士研究生李新阳,曹刘娟教授共同参与完成。
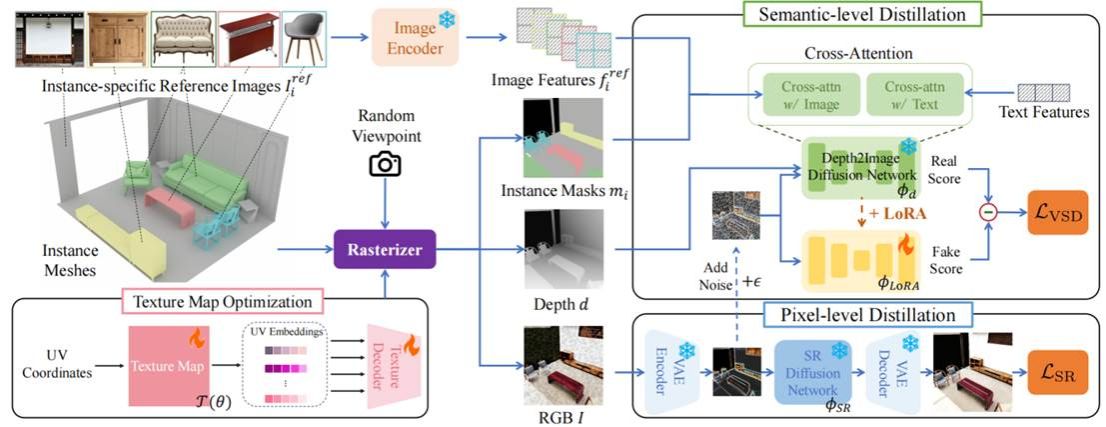
9. MVGGT: Multimodal Visual Geometry Grounded Transformer for Multiview 3D Referring Expression Segmentation
针对机器人等移动设备在稀疏视角下 3D 感知难、延迟高的痛点,研究团队提出了一种全新的多视角 3D 指代对象分割(MV-3DRES)框架——MVGGT。该框架摒弃了传统低效的“先重建再分割”模式,通过端到端的双支路设计将语言深度融入几何推理,并创新性地利用 PVSO 优化算法解决了稀疏信号下的梯度稀释问题;配合同步推出的 MVRefer 标准基准,MVGGT 在实现高精度定位的同时显著提升了推理速度,为复杂真实场景下的多模态空间感知树立了新的性能标杆。该项目已开源,项目主页为:https://mvggt.github.io/
该论文的共同第一作者是厦门大学人工智能研究院2024级博士生吴昌鲡和信息学院2023级本科生王浩东,通讯作者是纪家沂副教授,由曹刘娟教授等共同合作完成。
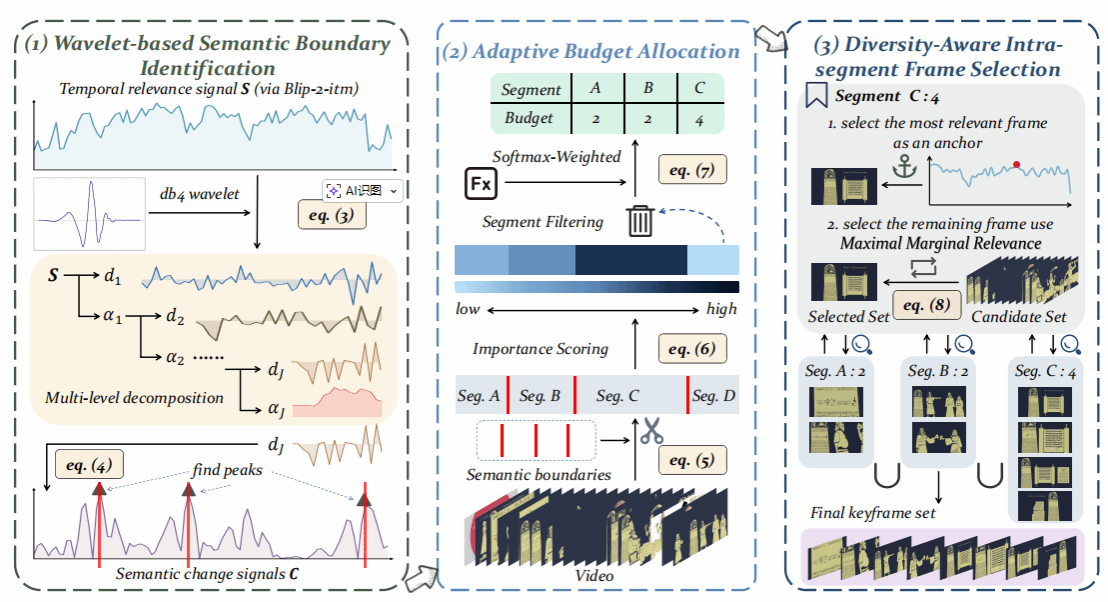
10.Wavelet-based Frame Selection by Detecting Semantic Boundary for Long Video Understanding
在长视频理解任务中,由于视频帧冗余度高且大模型上下文受限,高效的帧选择至关重要。现有方法通常倾向于选取孤立的查询相关帧,忽视了视频整体的叙事连贯性,且极易受到高频噪声的干扰。为此,本文提出了一种全新的无训练帧选择框架 WFS-SB。该方法创新性地引入信号处理视角,利用小波变换过滤查询-帧相似度信号中的噪声,精准识别语义边界,将长视频分割为语义连贯的“章节”片段。随后,通过自适应预算分配与段内多样性采样策略提取关键帧,在保留视频叙事完整性的同时兼顾重要性与多样性。实验表明,WFS-SB 显著提升了主流大模型在 VideoMME、MLVU 等长视频基准测试上的表现,最高提升达 9.5%,为长视频理解提供了一种全新的结构感知型帧选择范式。
该论文第一作者是厦门大学人工智能研究院2024级硕士生陈旺,通讯作者是郑侠武副教授,由2024级硕士生曾宇晖、2023级硕士生罗咏东、2025级硕士生谢天宇、林洛君副教授(福州大学)、纪家沂副教授、张岩工程师共同合作完成。