AAAI Conference on Artificial Intelligence会议是人工智能领域重要的国际会议,是CCF A类推荐会议。AAAI 2026将于2026年1月20日-27日在新加坡举办。今年共有23680篇论文投稿,最终4167篇论文接收,录用率17.6%。厦门大学媒体分析与计算实验室共有9篇论文被录用,录用论文简要介绍如下:
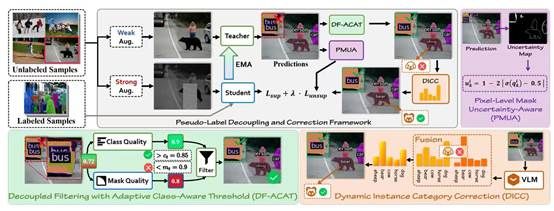
1. Robust Pseudo-Labeling via Decoupled Class-Aware Filtering and Dynamic Category Correction(Oral)
半监督实例分割(SSIS)旨在利用有限的标注数据与大规模未标注数据实现实例级预测,但其性能高度依赖伪标签质量。现有方法通常将类别置信度与掩码质量耦合为单一分数进行过滤,容易造成语义准确性与空间精度之间的冲突,从而引入噪声伪标签并限制模型上限。
为此,本文提出 PL-DC(Pseudo-Label Decoupling and Correction) 框架,从实例、类别与像素三个层面全面提升伪标签的可靠性。首先,设计解耦过滤与自适应类别感知阈值机制,分别评估类别与掩码质量,并通过指数移动平均动态更新类别特定阈值,实现更细粒度的伪标签筛选。其次,提出动态实例类别校正模块,利用语义原型与一致性对齐策略纠正类别模糊的伪标签。最后,引入像素级掩码不确定性感知机制,抑制低置信像素的干扰,提高掩码监督的精确性和鲁棒性。在 COCO 与 Cityscapes 基准上的大规模实验表明,PL-DC 在极低标注比例下依然带来显著提升,在COCO 1% 标注数据上提高 +11.7 mAP,在 Cityscapes 5% 标注下提升 +16.4 mAP,并取得新的 SOTA 结果,充分展示了其在弱标注场景中的强大优势。
该论文为Oral,第一作者是厦门大学信息学院2023级博士生林将航,通讯作者是张声传教授,由2023级硕士生卢轶霖、2025级博士生朱朝阳、腾讯优图沈云航、曹刘娟教授等共同合作完成。
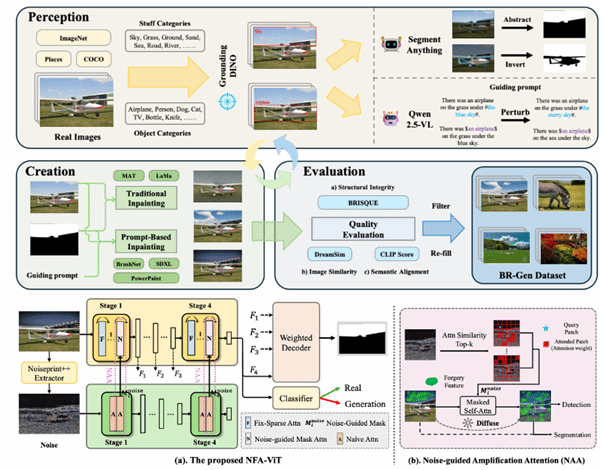
2. Zooming In on Fakes: A Novel Dataset for Localized AI-Generated Image Detection with Forgery Amplification Approach
随着生成式人工智能图像工具的迅速发展,基于AI的图像局部编辑日益逼真,给验证视觉内容完整性带来了新的挑战。目前检测数据集的局限在于过于关注物体(object-centric)伪造,而忽略了天空、地面等场景级元素(stuff and background),导致检测模型泛化能力不足。本文提出 BR-Gen——一个包含 150,000 张AI局部编辑图像的大规模数据集,具有多种场景感知标注。BR-Gen 通过全自动的“感知—生成—评估”流程构建,以确保语义一致性与视觉真实感。本文进一步提出 NFA-ViT——一种噪声引导的伪造增强方法,其能提升局部伪造检测能力。NFA-ViT 利用噪声指纹挖掘图像区域中的差异来源,并强制正常特征与异常特征交互,使伪造痕迹在整幅图像中传播,令细微伪造能够影响更广的上下文,从而提升模型检测的鲁棒性。大量实验表明,BR-Gen 构建了现有方法未覆盖的全新场景;NFA-ViT 在 BR-Gen 上超越现有方法,并在多个现有基准上表现出良好的泛化能力。项目代码可参见:https://github.com/clpbc/BR-Gen。
该论文的共同第一作者是厦门大学信息学院2024级硕士生蔡侣盼和腾讯优图王昊为,共同通讯作者是纪家沂博士后研究员和孙晓帅教授,由周门龑叔、陈燊(腾讯优图)、姚太平(腾讯优图)等共同合作完成。
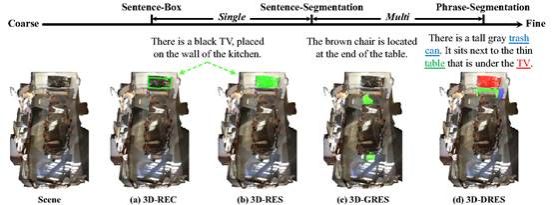
3. 3D-DRES: Detailed 3D Referring Expression Segmentation
当前的三维视觉定位任务仅处理句子级别的检测或分割,这严重忽视了自然语言表达中丰富的组合性上下文推理。为解决这一挑战,本文提出“三维细节指向性分割”(3D-DRES)这一新任务,通过建立短语与三维实例的映射关系,提升精细的三维视觉语言理解能力。为支持3D-DRES,本文构建了包含54,432条文本、涵盖11,054个不同物体的DetailRefer数据集。与传统数据集不同,DetailRefer采用创新的短语-实例标注范式,每个指代名词短语都明确对应其三维元素。此外,本文还推出“DetailBase”架构——这种经过优化的基线模型在句子和短语层面均支持双模式分割。实验结果表明,基于DetailRefer训练的模型不仅在短语级分割中表现优异,更在传统三维指向性分割基准测试中取得显著突破。
该论文共同第一作者是厦门大学信息学院2023级硕士生陈琦和2024级博士生吴昌鲡,通讯作者为博士后研究员纪家沂,由2023级博士生马祎炜以及曹刘娟教授共同合作完成。
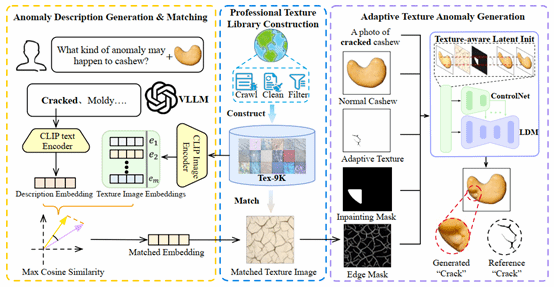
4. AnomalyPainter: Vision-Language-Diffusion Synergy for Realistic and Diverse Unseen Industrial Anomaly Synthesis
视觉异常检测由于缺乏足够的异常数据而受到限制。尽管现有的异常合成方法已经取得了显著进展,但在同时兼顾合成结果的真实感和多样性方面仍面临巨大挑战。为了解决这一问题,本文提出了 AnomalyPainter框架,这一新框架通过协同利用视觉语言大模型、潜在扩散模型以及本文新构建的纹理库 Tex-9K,打破“多样性–真实感”的权衡困境。Tex-9K 是一个专业纹理库,包含 75 个类别、共 8792 个纹理素材,专门为多样化异常合成而设计。借助 VLLM 的通用知识,本文为每一种工业目标自动生成合理的异常文本描述,并与 Tex-9K 中相关且多样的纹理进行匹配;这些纹理随后通过 ControlNet 引导 LDM 在正常图像上进行“绘制”。大量实验表明,AnomalyPainter 在真实感、多样性和泛化能力方面均优于现有方法,并在下游任务中取得了更好的性能。
该论文共同第一作者是厦门大学信息学院2023级硕士生赖章宇和卢轶霖,通讯作者为曹刘娟教授,由2023级博士生李新阳、林将航、曲延松,李明(浪潮)共同合作完成。
5. S2Teacher: Step-by-step Teacher for Sparsely Annotated Oriented Object Detection
虽然全监督的旋转目标检测在遥感图像理解方面取得了显著进展,但其代价是高强度的人工标注。近年来的研究尝试通过弱监督与半监督学习来缓解这一负担但这些方法忽略了复杂遥感场景中密集标注所带来的困难。本文提出了一种新的任务设定——稀疏标注旋转目标检测(SAOOD),其中每幅图像仅标注部分实例,并进一步提出了解决该设定挑战的方法。具体而言,本文关注该设定中的两个关键问题:(1) 稀疏标注导致模型在有限的前景表征上发生过拟合;(2) 未标注目标(即假负例)会干扰特征学习,提出了S2Teacher,这是一种新的角度一致性引导方法,可由易到难逐步挖掘未标注目标的伪标签,从而增强前景表征;同时,它会对未标注目标的损失进行重加权,以减轻其在训练过程中的影响。大量实验表明,S2Teacher在不同稀疏标注比例下均能显著提升检测器性能,并且在仅使用10%标注实例的情况下,在DOTA数据集上取得接近全监督的性能,有效平衡了精度与标注成本。
该论文第一作者为厦门大学2024级博士生林煜,通讯作者为曹刘娟教授,由林将航博士、张声传副教授等共同合作完成。
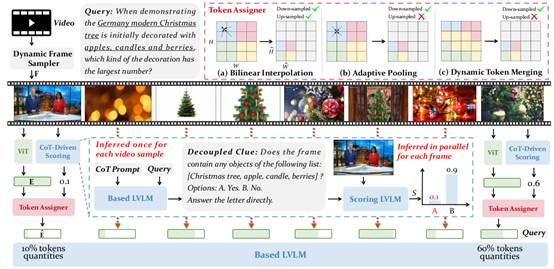
6. QuoTA: Query-oriented Token Assignment via CoT Query Decouple for Long Video Comprehension
QuoTA是一种面向长视频理解任务设计的查询驱动免训练插件,通过“思维链”提示先对大模型进行问题拆解,把复杂指令转化为包含具体实体或事件的关键词列表,再调用轻量级LVLM并行评估每一帧与查询的相关度,生成帧级重要性得分;随后在不改变总视觉token预算的前提下,利用双线性插值、自适应池化或动态token融合三种策略对得分高的帧多分配token、得分低的帧少分配甚至舍弃,并配合依视频长度自适应增加的采样帧数,实现细粒度且高效的视觉冗余压缩。实验表明,将QuoTA直接插入LLaVA-Video-7B或LLaVA-OneVision-7B后,在Video-MME、MLVU、LongVideoBench、VNBench、MVBench与NeXT-QA六项涵盖分钟级到小时级视频的基准上平均性能提升3.2%,其中最长30–60分钟段落的Video-MME提升达4–5个百分点,VNBench“大海捞针”式检索任务提升更高达10.3%,验证了查询感知token分配在缓解信息冗余、增强关键帧表达及提升长视频推理能力方面的显著优势。
该论文共同第一作者为厦门大学信息学院2023级硕士生罗咏东和2024级硕士生陈旺,通讯作者是郑侠武副教授,由纪家沂博士后研究员、黄锦发(罗切斯特大学)等共同合作完成。
7. DeOcc-1-to-3: 3D De-Occlusion from a Single Image via Self-Supervised Multi-View Diffusion
本文提出DeOcc-1-to-3,首个支持从遮挡图像直接进行3D补全与重建的端到端方法。该框架基于预训练多视角扩散模型,通过结构保持的自蒸馏训练策略,联合学习图像补全与多视角合成,无需修改原始架构即可获得高质量、结构一致的新视图,显著提升遮挡场景下的3D重建效果。此外,本文还构建了首个系统性遮挡三维重建评测基准Occ-LVIS,涵盖多类别与多等级遮挡,支持细粒度评估。实验证明,DeOcc-1-to-3在重建完整性与视觉质量方面均优于两阶段方法,同时具备良好的推理效率与泛化能力。
该论文第一作者为厦门大学信息学院2023级博士生曲延松,通讯作者是张声传副教授,由2024级硕士生代绍辉、2023级博士生李新阳、王宇泽(北京航空航天大学)、2024级博士生沈优、曹刘娟教授等共同合作完成。

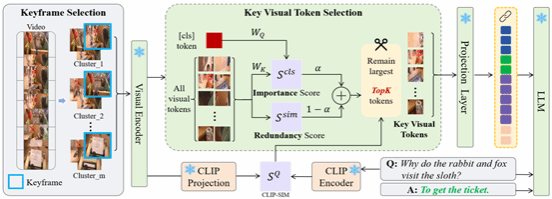
8. KTV: Keyframes and Key Tokens Selection for Efficient Training-Free Video LLMs
本文提出了一个名为 KTV的免训练的视频理解框架,通过“两级筛选”让通用图像-文本大模型更高效地看视频:第一步,它不用问题信息,而是用 DINOv2 提取所有帧的特征并做 K-means 聚类,从中选出能代表整段视频、且内容多样的问题无关关键帧以避免落入“语义陷阱”,从而减少时间上的冗余;第二步,在每个关键帧内,再根据与[CLS] token的重要性得分和与其他视觉token的冗余度共同计算评分,只保留最有信息量、又不过于重复的关键视觉 token,并结合CLIP评估与问题的相关性,为更相关的帧分配更多token,最终将这些精简后的视觉token与文本一起输入LLaVA等VLM进行推理。实验表明,在多项多选视频问答基准上,KTV在仅用极少视觉token(例如60分钟、10800帧的视频只用 504 个视觉 token)的情况下,仍优于现有免训练的视频理解方法,部分设置甚至超过一些需要专门训练的视频大模型,显著降低了推理时长和算力需求。
该论文的共同第一作者是厦门大学信息学院2025级硕士生宋柏杨和鹏城实验室博士后研究员彭军,共同通讯作者是博士后研究员彭军(鹏城实验室)和郭健元助理教授(香港城市大学)。由2022级博士生张玉鑫、陈光耀(北京大学)、杨飞雕(鹏城实验室)共同完成。
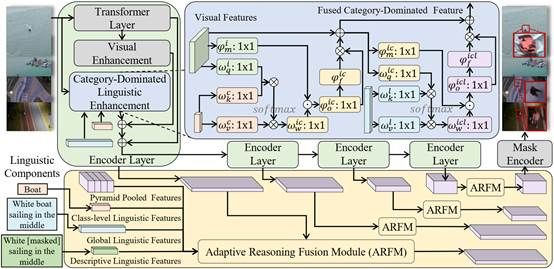
9. RIS-LAD: A Benchmark and Model for Referring Image Segmentation in Low-Altitude Drone Imagery
指代图像分割(Referring Image Segmentation,RIS)是视觉-语言理解中的核心任务,旨在根据自然语言描述分割出图像中的特定目标。尽管该技术在遥感领域已取得长足进步,但低空无人机(Low-Altitude Drone,LAD)场景下的指代分割仍鲜有研究。本文提出了RIS-LAD,这是首个专为低空无人机场景打造的细粒度指代图像分割基准数据集,包含13,871组从真实无人机航拍素材中精心标注的图像-文本-掩码三元组,特别关注小目标、密集杂乱物体以及多视角情况。与此同时,本文提出了一种语义感知自适应推理网络(Semantic-Aware Adaptive Reasoning Network),不再将全部语言特征统一注入网络,而是将语义信息分解并自适应地路由至不同阶段。
该论文第一作者是厦门大学信息学院2024级博士生叶锴,通讯作者是曹刘娟教授,由戴平阳高级工程师、2023级本科生栾英石、2025级硕士生孟广樾、2023级本科生陈朱迪共同合作完成。