近日,实验室在高效视觉感知与模型压缩、高效视觉内容生成领域取领域取得重要进展。由厦门大学人工智能研究院2021级博士生钟云山、信息学院2022级硕士生胡佳伟、林明宝博士(Rakuten 首席科学家)、2021级硕士生陈锰钊、纪荣嵘教授(通讯作者)等合作完成的论文 "I&S-ViT: An Inclusive & Stable Method for Post-Training ViTs Quantization" (I&S-ViT:面向ViT训练后量化的包容性与稳定性方法) 以及由厦门大学信息学院2024级博士生林志航、林明宝博士(Rakuten 首席科学家)、2025级博士生詹翁怡、纪荣嵘教授(通讯作者)合作完成的论文 “AccDiffusion v2: Towards More Accurate Higher-Resolution Diffusion Extrapolation”(AccDiffusion v2::面向更精确的高分辨率扩散模型外推方法) 被国际学术期刊《IEEE Transactions on Pattern Analysis and Machine Intelligence》(IEEE TPAMI)正式录用。TPAMI是计算机学科领域最顶级的国际期刊,影响因子18.6。
以下是这两篇论文的简要介绍:
1. "I&S-ViT: An Inclusive & Stable Method for Post-Training ViTs Quantization
Vision Transformer(ViT)因其强大的性能被广泛应用,但其计算量大、参数多,难以在资源受限设备上部署。训练后量化(Post-Training Quantization, PTQ)是主流的加速手段,但ViT模型,特别是其SoftMax激活,对量化操作极为敏感,导致PTQ后模型精度急剧下降。论文提出的 I&S-ViT 框架,通过引入“包容性”(Inclusive)和“稳定性”(Stable)两大核心机制,从根本上缓解了ViT的性能退化问题。其技术核心包括两大创新:
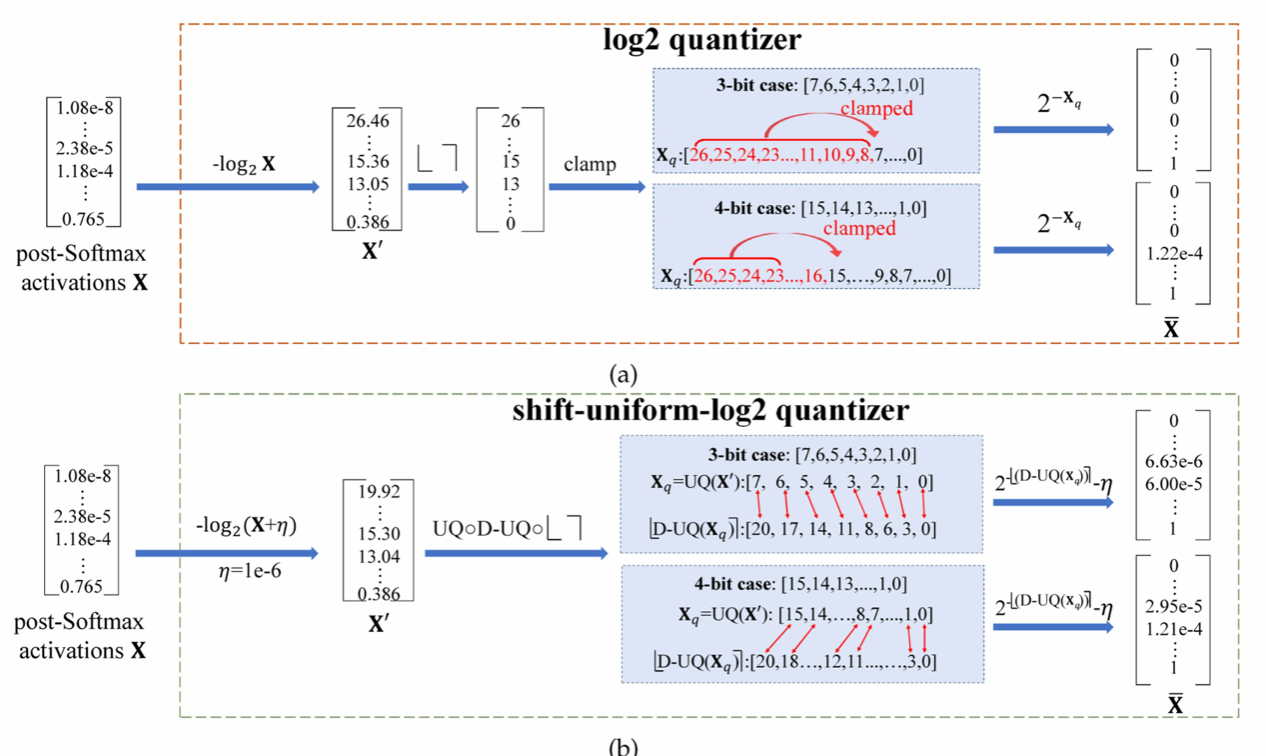
1) 新型移位均匀Log2量化器 (Shift-Uniform-Log2 Quantizer, SULQ)
解决痛点: 解决了现有Log2量化器在处理ViT的Post-Softmax激活时,因数据分布不均匀而导致的量化低效问题。
技术创新: SULQ结合了移位机制和均匀量化,设计了一种包容性的域表示。它能更完整、更均匀地覆盖激活函数的动态范围,确保关键信息的量化精度。
2) 三阶段平滑量化策略 (Three-Stage Smooth Quantization Strategy, SQS)
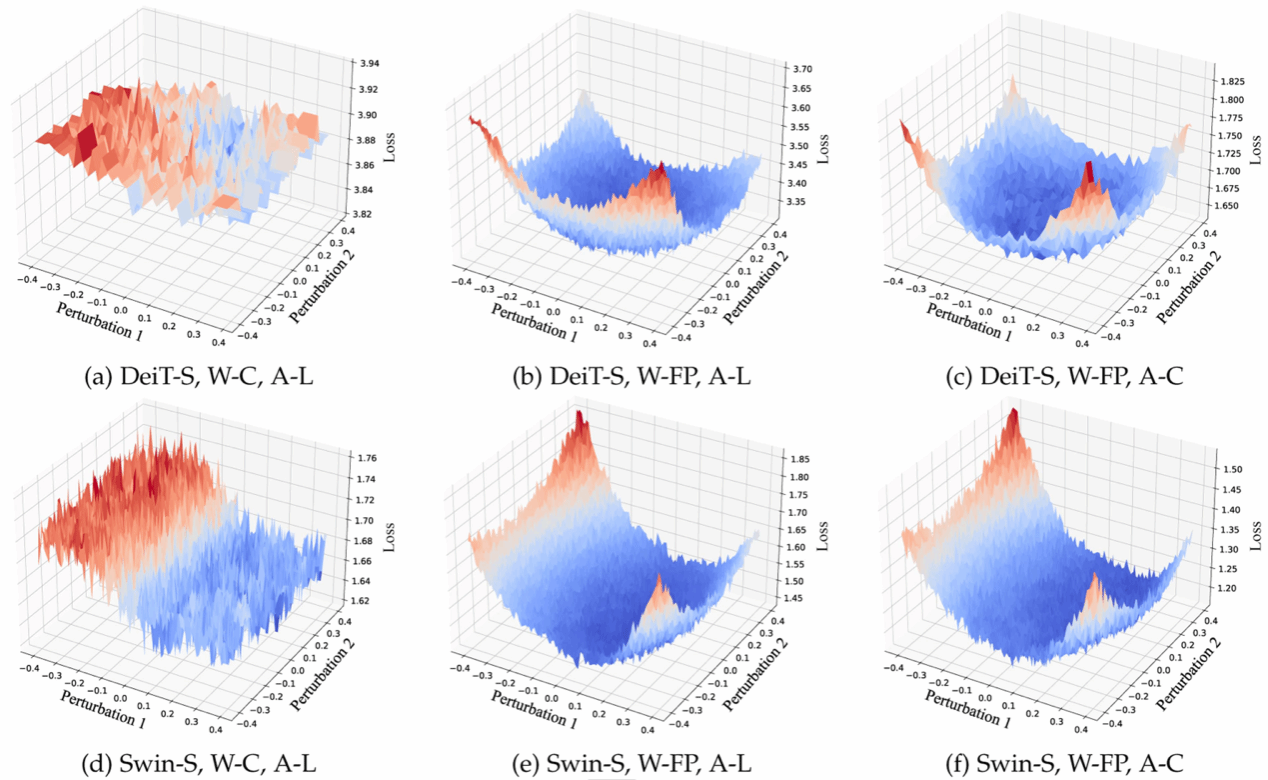
解决痛点: 解决了粗粒度量化带来的损失面崎岖不平(rugged loss landscape)问题,以及由此引起的模型量化敏感性增强。
技术创新: SQS通过分阶段平滑信道级和层级的量化误差强度,有效“驯服”了敏感的量化过程,大幅提升了大型ViT模型在量化过程中的鲁棒性和可靠性。
该研究在多个主流ViT模型和视觉任务数据集上进行了全面验证,结果表明 I&S-ViT 能够成功缓解 ViT 在 PTQ 后的精度下降问题,在不进行重新训练的前提下,实现了与全精度模型相当的性能表现。
本研究为实现 Vision Transformer 模型的高效、可靠部署提供了关键的技术路径和性能保障,对于推动实时高效AI在边缘计算、自动驾驶等领域的应用具有重要意义,体现了研究团队在模型压缩与高效视觉感知领域的前沿研究实力。
2. AccDiffusion v2: Towards More Accurate Higher-Resolution Diffusion Extrapolation
扩散模型(Diffusion Models)在推理分辨率与预训练分辨率不一致时,常会出现严重的目标重复(Object Repetition)与局部结构失真(Local Distortion)问题。此外,扩散模型生成高分辨率图像需要的显存开销随着生成图片分辨率的增加指数增加,阻碍了其在资源有限场景下的应用。本文提出的方法AccDiffusion v2,可以在无需额外训练的情况下,使用消费级显卡实现更加精确的分块式(Patch-wise)高分辨率扩散外推(Diffusion Extrapolation)。其核心技术创新主要体现在以下三方面:
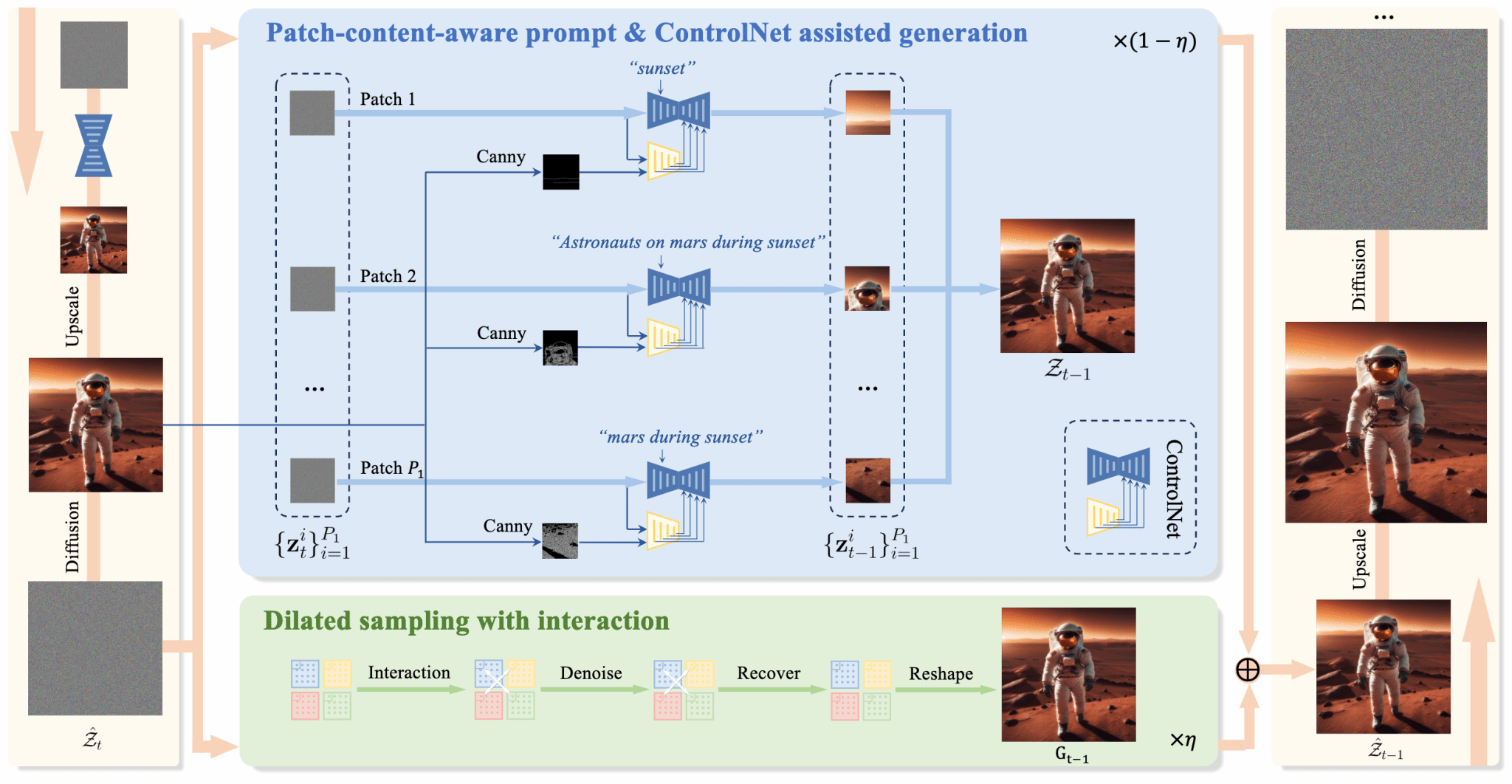
1) 分块内容感知提示机制(Patch-Content-Aware Prompting)
解决痛点:在传统分块式高辨率扩散外推方法中,所有分块共享同一文本提示词,导致模型在不同分块中生成相似或重复内容;若完全去除提示,又会造成分块生成的内容细节缺失和退化。严重影响生成的高分辨率图像的保真度。
技术创新: AccDiffusion v2 将原本“图像级内容感知提示(Image-Content-Aware Prompt)”解耦为多个“块级内容感知提示(Patch-Content-Aware Prompts)”。每个图像分块根据其内容生成更为精确的提示描述,从而在保持局部细节丰富的同时,有效避免重复生成问题。
2) ControlNet 辅助局部结构生成(ControlNet assisted generation)
解决痛点:分块式高辨率扩散外推方法生成的图像会遭受局部结构失真问题,严重影响生成图像的保真度。
技术创新:经过实验分析发现,在分块式高辨率扩散外推方法中,局部失真问题产生的原因是分块提示词中缺乏对局部结构的精确描述。AccDiffusion v2 首次在无训练的高分辨率扩散外推中引入 ControlNet 作为局部结构辅助生成模块,提供局部边缘、轮廓等结构引导信号,从而有效减少局部失真问题。
3) 带有窗口交互的膨胀采样机制(Dilated Sampling with Window Interaction)
解决痛点:传统的膨胀采样机制的不同窗口之间缺乏交互,导致不同窗口提供的全局语义信息不一致,影响生成的高分辨率图像的保真度。
技术创新: AccDiffusion v2使用了具有窗口交互的膨胀采样机制,以在更高分辨率的扩散外推期间,让膨胀采样机制获得更一致的全局语义信息,进一步抑制了重复生成和局部失真问题。
该研究进行了大量定量实验和定性实验,结果表明AccDiffusion v2 可以在无需额外训练的情况下有效缓解分块式高分辨率图像外推中的重复生成和局部失真问题,可以成功生成保真度更高的超高分辨率图像。

本研究为实现扩散模型在资源有限场景下进行高分辨率图像生成提供了关键的技术路径和性能保障,对于推动生成模型在广告、游戏等对高分辨率图像有高要求的应用场景中落地应用奠定了坚实基础,体现了研究团队在高效视觉内容生成领域的前沿研究实力。