The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS 2025)是人工智能与机器学习领域的三大国际会议(NeurIPS、ICML、ICLR)之一,CCF A类会议。NeurIPS 2025分别将于2025年11月30日-12月5日在墨西哥墨西哥城以及2025年12月2日-12月7日在美国圣地亚哥举办,今年 NeurIPS 主赛道共收到 21575 份有效论文投稿,录用5290 篇,录用率为 24.52%。厦门大学媒体分析与计算实验室共有9篇论文被录用,录用论文简要介绍如下:
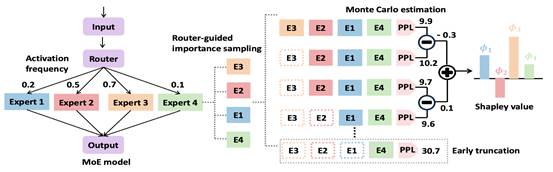
1. Discovering Important Experts for Mixture-of-Experts Models Pruning Through a Theoretical Perspective
简介:混合专家(MoE)架构能够高效扩展大语言模型,但由于参数规模庞大而面临巨大的内存开销。现有的专家剪枝方法依赖启发式指标或对专家子集进行不可行的穷举评估,导致性能欠佳或缺乏可扩展性。本文提出Shapley-MoE方法,该方法是一种受合作博弈论启发的高效MoE剪枝方法。通过利用 Shapley 值量化每个专家的贡献,无需对专家组合进行穷举评估即可识别重要专家。为克服精确计算 Shapley 值的 NP-hard复杂度难题,本文引入了基于蒙特卡罗采样的高效近似策略,将计算复杂度降低至平方级别。然而,朴素的蒙特卡罗采样仍然面临估计精度不足和采样效率低的问题。为此,本文进一步提出两种新方法以提升采样精度与效率:(1)早期截断,针对过小专家子集引发的不稳定采样步骤进行提前终止;(2)路由器引导的重要性采样,利用门控激活概率优先采样重要的专家子集。理论与实验分析均表明,这两种方法能够加速 Shapley 值估计并提升精度。大量实证评估显示,Shapley-MoE方法优于现有的专家剪枝方法。
该论文第一作者为厦门大学人工智能研究院2025级博士生黄伟中,通讯作者是曹刘娟教授,由2022级博士生张玉鑫、郑侠武副教授、晁飞副教授以及纪荣嵘教授等共同合作完成。
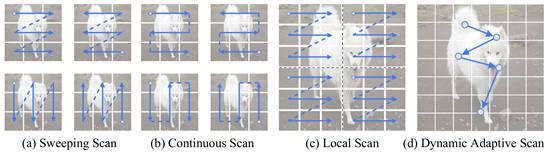
2. DAMamba: Vision State Space Model with Dynamic Adaptive Scan
简介:状态空间模型(SSMs)近年来在计算机视觉领域引起了广泛关注。然而,由于图像数据具有独特特性,将SSMs从自然语言处理领域迁移到计算机视觉中,并未超越当前最先进的卷积神经网络(CNNs)和视觉Transformer(ViTs)。现有的视觉SSMs主要依赖人工设计的扫描方式,将图像块在局部或全局范围内展平为序列。这种方法破坏了图像原本的语义空间邻接关系,缺乏灵活性,难以有效捕获复杂的图像结构。为克服这一局限性,本文提出了动态自适应扫描(DAS),一种数据驱动的方法,可自适应地分配扫描顺序与区域,从而在保持线性计算复杂度和全局建模能力的同时,实现更灵活的建模能力。在此基础上,本文进一步提出了视觉骨干网络 DAMamba,在图像分类、目标检测、实例分割和语义分割等视觉任务中,相比主流的视觉 Mamba 模型取得了显著性能提升。值得注意的是,它还超越了一些最先进的CNNs和ViTs。
该论文的共同第一作者是厦门大学信息学院2024级博士生李谭哲和信息学院2023级硕士生李曹硕,通讯作者是金泰松副教授,由张宝昌教授(北京航空航天大学)、纪荣嵘教授等共同合作完成。
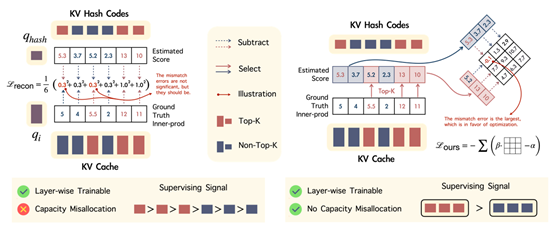
3. Spotlight Attention: Towards Efficient LLM Generation via Non-linear Hashing-based KV Cache Retrieval
简介:为降低大语言模型中键值缓存(KV cache)的负担以加速推理,一种有效策略是在解码过程中动态选取关键缓存。现有方法多采用随机线性哈希来识别重要词元,但由于模型中查询与键的向量正交分布于两个狭窄的锥形区域内,此方法的效率并不高。我们为此引入一种名为“Spotlight Attention”的新方法,它通过非线性哈希函数来优化查询和键的嵌入式分布,进而提升编码效率与稳健性。同时,我们开发了一套基于布拉德利-特里排序损失的轻量级稳定训练框架,仅需8小时即可在单张16GB显存的GPU上完成非线性哈希模块的优化。实验结果表明,与传统线性哈希相比,Spotlight Attention在大幅提升检索精度的同时,将哈希码长度缩短了至少五倍。最后,我们通过实现专门的CUDA核心来利用位运算的计算优势,在单块A100 GPU上实现了对512K词元的哈希检索耗时低于100微秒,端到端吞吐量相较于传统解码方式提升高达三倍。
该论文的第一作者是厦门大学人工智能研究院2023级硕士生李文昊,通讯作者是纪荣嵘教授,由张玉鑫博士、罗根博士、晁飞副教授、万海缘(清华大学),龚子洋(上海交通大学)共同合作完成。
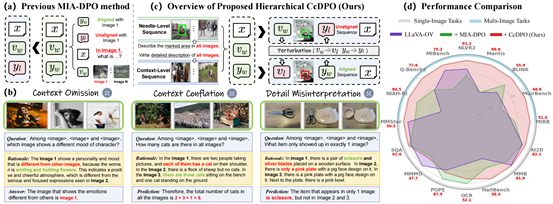
4. Zooming from Context to Cue: Hierarchical Preference Optimization for Multi-Image MLLMs
简介:多模态大语言模型(MLLMs)在单图像任务中表现卓越,但在多图像理解方面因跨模态对齐问题而表现不佳,常导致上下文忽略、混淆与误解等幻觉现象。现有基于直接偏好优化(DPO)的方法通常仅针对输入序列中的单张图像进行优化,缺乏对多图像整体上下文的建模,导致效果受限。为此,我们提出“上下文至线索直接偏好优化”(CcDPO),一种层次化偏好优化框架,通过从序列上下文到局部细节的视觉线索聚焦,增强模型在多图像场景下的感知能力。具体而言,CcDPO包含两个层次:(i)上下文级优化:通过引入低成本构建的全局序列偏好对,校正MLLMs在多图像理解中存在的上下文认知偏差。 (ii)线索级优化:通过融合区域视觉提示与多模态偏好监督,引导模型聚焦于关键视觉细节,以抑制其图像感知偏差。此外,为了支持可扩展的优化,我们还构建了自动生成的多层级偏好对数据集MultiScope-42k。实验结果表明,CcDPO 能显著减少MLLM多图像理解中的幻觉现象,同时在各类单图像与多图像任务上均表现出稳定的性能提升。
该论文的共同第一作者是厦门大学信息学院2025级博士生李旭东和张梦丹(腾讯优图),通讯作者是张岩工程师,由陈珮娴(腾讯优图)、郑侠武副教授、孙星(腾讯优图)、纪荣嵘教授等共同合作完成。
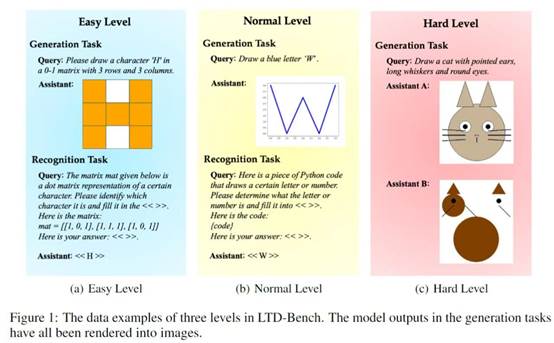
5. LTD-Bench: Evaluating Large Language Models by Letting Them Draw
简介:当前大型语言模型(LLMs)的评估范式是人工智能研究中的一个关键盲区,这类范式依赖不透明的数值指标,既掩盖了模型在空间推理方面的根本性局限,也无法让人直观理解模型的实际能力。这种缺陷导致模型报告的性能与实际能力之间出现危险的脱节,在需要理解物理世界的应用场景中,这一问题尤为突出。为此,本文提出了LTD-Bench:该基准通过要求模型借助点阵或可执行代码生成指定图形,将 LLM 评估从抽象分数转变为可直接观察的视觉输出。这种方法能让非专业人士也能立刻发现模型在空间推理上的局限,从而弥合统计性能与直观评估之间的根本性差距。
LTD-Bench 采用了全面的评估方法,包含互补的生成任务(测试空间想象力)与识别任务(评估空间感知能力),并将两项任务划分为三个难度逐步提升的等级,系统地评估 “语言-空间” 映射的两个方向(即 “语言到空间” 与 “空间到语言”)。本文针对最先进模型开展的实验表明:即便在传统基准测试中取得优异成绩的 LLM,在建立语言与空间概念的双向映射时,仍表现出严重不足,这一根本性局限削弱了它们作为 “真实世界模型” 的潜力。此外,LTD-Bench 的视觉输出支持高效的诊断分析,为研究模型相似性提供了一种可行途径。
该论文共同第一作者为厦门大学信息学院2023级硕士林柳灏和腾讯优图李珂,通讯作者为张岩工程师,由许子涵(腾讯优图)、施俞晨(腾讯优图)、秦玉磊(腾讯优图)、孙星(腾讯优图)、纪荣嵘教授等共同合作完成。
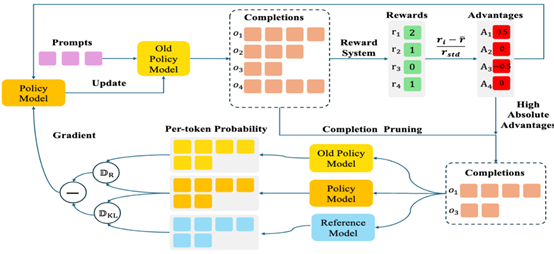
6. CPPO: Accelerating the Training of Group Relative Policy Optimization-Based Reasoning Models
简介:本文提出 Completion Pruning Policy Optimization (CPPO),以加快 DeepSeek 提出 的 Group Relative Policy Optimization (GRPO) 算法的训练速度。本文通过对GRPO的策略目标函数进行理论推导和分析发现并非所有完成(Completion)对策略模型的梯度的贡献都相同,其贡献取决于完成的绝对优势值。基于这个发现,CPPO通过剪枝掉具有低绝对优势值的完成,大幅减少策略模型训练所需的计算量,并通过动态分配策略,有效利用完成剪枝策略释放的计算量,进一步提高GPU利用率。实验表明,CPPO在GSM8K和Math数据集上相对于GRPO算法分别实现了 8.32× 和 3.51× 的训练加速,同时保持甚至提升了策略模型精度。
该论文第一作者是厦门大学信息学院人工智能系2024级博士生林志航,通讯作者是纪荣嵘教授,由林明宝(Rakuten 首席科学家)、谢源教授(华东师范大学)共同合作完成。
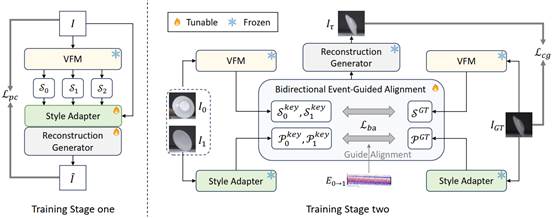
7. EPA: Boosting Event-based Video Frame Interpolation with Perceptually Aligned Learning
简介:针对基于事件的视频插帧在高速运动场景中,因关键帧模糊、失真等退化而导致生成质量不佳的核心挑战,本文提出了一种名为EPA的新框架。EPA创新性地摒弃了传统的像素级监督学习,转而采用一种在对图像退化不敏感的“语义-感知”特征空间中进行对齐和学习的新范式。该框架借助视觉基础模型提取鲁棒的语义特征,并通过一个双向事件引导模块,利用事件数据的高时间分辨率优势来精确对齐这些特征,最终生成在人类感知上更为真实、清晰的插入帧,并在多个数据集上的大量实验证明了该方法的优越性。
该论文的第一作者是厦门大学信息学院2025级博士生刘宇涵,通讯作者是邓勇舰副教授(北京工业大学),由付凌辉(北京工业大学)、杨震教授(北京工业大学)、陈浩副教授(东南大学)、李有福教授(香港城市大学)共同合作完成。
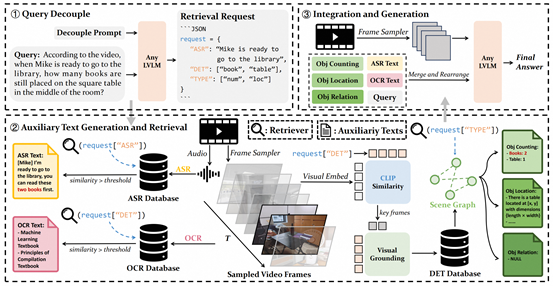
8. Video-RAG: Visually-aligned Retrieval-Augmented Long Video Comprehension
简介:不同于主流的基于长视频微调和基于Agent这类高资源需求的方案,本文提出的Video-RAG利用开源工具从纯视频数据中提取视觉对齐信息(音频、文字和物体检测)作为辅助文本,经过检索后与视频帧和问题一起以即插即用的方式整合到现有的LVLM中,节约计算资源。实验结果表明,Video-RAG在接入到主流开源模型后在三个流行的长视频评估基准中得到了大幅的性能提升。在与72B模型结合使用时,Video-RAG的性能可以超过商业闭源模型(例如GPT4o、Gemini1.5)。
该论文第一作者为厦门大学信息学院2023级硕士生罗咏东,通讯作者是郑侠武副教授,由纪家沂博士后研究员、黄锦发(罗切斯特大学)、纪荣嵘教授等共同合作完成。
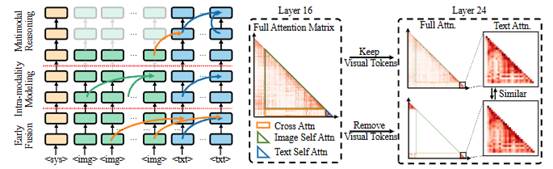
9. Accelerating Multimodal Large Language Models via Dynamic Visual-Token Exit and Empirical Findings
简介:本文从注意力行为的角度研究多模态大型语言模型(MLLM)的视觉冗余问题。通过大量的实证实验,我们观察并总结了MLLM的三个主要推理阶段:首先快速完成Token之间的早期融合;然后模态内建模开始发挥作用;最终,多模态推理}恢复并持续到推理结束。具体而言,我们发现,当文本标记接收到足够的图像信息时,视觉标记将停止对推理做出贡献。基于此观察,我们提出了一种提高 MLLM 效率的有效方法,称为动态视觉标记退出(DyVTE)。该方法通过判断模型所处的推理阶段,来删除所有的视觉Token,与之前的基于标记的视觉压缩方法正交但协同。
该论文第一作者是厦门大学人工智能研究院2022级博士研究生吴穹,通讯作者是周奕毅副教授,由2024级硕士生林文浩、2023级硕士生叶伟豪、曾展鹏副教授、孙晓帅副教授、纪荣嵘教授共同合作完成。