第20届ICCV国际计算机视觉大会论文录用结果近日揭晓,MAC实验室共有7篇论文被录用。
International Conference on Computer Vision (ICCV)是计算机视觉领域的顶级国际会议,CCF A类会议。ICCV 2025将于2025年10月19日- 10月23日在美国夏威夷举办,ICCV 2025 共有11239 份投稿,录用2698篇,录取率为 24%。
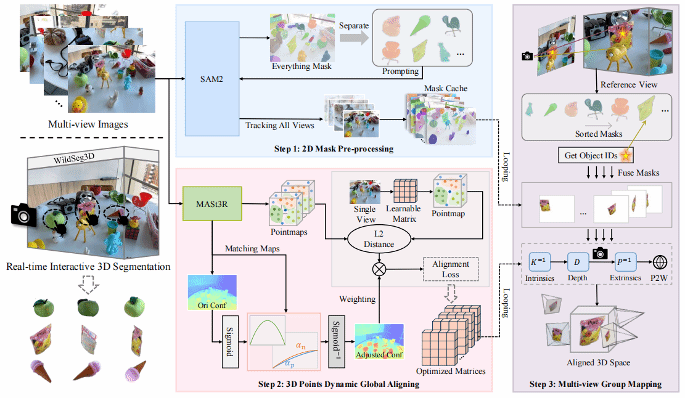
1. WildSeg3D: Segment Any 3D Objects in the Wild from 2D Images
简介:基于二维图像的交互式三维分割技术最近展现了令人印象深刻的性能。然而,当前的模型通常需要大量针对特定场景的训练才能准确地重建和分割物体,这限制了它们在实时场景中的适用性。本文提出一种前馈的交互式分割方法(WildSeg3D),能够在不同的环境中分割任意三维物体。这种前馈方法的一个关键挑战在于跨多个二维视图的三维对齐误差的累积,这会导致三维分割结果不准确。为了解决这个问题,本文提出了动态全局对齐 (DGA) 技术,通过使用动态调整函数来专注于图像中难以匹配的三维点,从而提高全局多视图对齐的准确性。此外,为了实现实时交互式分割,本文还引入了多视图组映射 (MGM) 方法,该方法利用对象掩码缓存来集成多视图分割并快速响应用户提示。WildSeg3D 展现了跨任意场景的泛化能力,无需针对特定场景进行训练,与现有 SOTA 模型相比,在保证精度的前提下,很大提升了整体速度。
该论文第一作者是厦门大学信息学院2024级硕士生郭岩松,通讯作者是曹刘娟教授,由胡杰(新加坡国立大学)、2023级博士曲延松等合作完成。
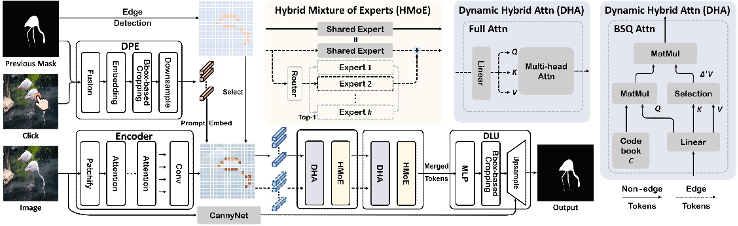
2. Inter2Former: Dynamic Hybrid Attention for Efficient High-Precision Interactive Segmentation
简介:论文提出了一种名为Inter2Former的交互式分割模型,旨在解决传统交互分割模型的CPU效率与分割精度难以兼顾的问题。所提模型通过优化计算资源的动态分配来提升性能:首先,该模型采用动态提示嵌入(DPE)与动态局部上采样(DLU),将计算量自适应地聚焦于目标所在区域;其次,利用动态注意力混合(DHA)和混合专家模型(HMoE),根据交互迭代中前一次分割结果的边界来动态调整计算复杂度,对CPU任务处理进行了深度优化。结果表明,Inter2Former在多个高精度交互分割基准上达到了最佳水平,同时在CPU设备上保持了较高的效率。
该论文第一作者为厦门大学信息学院2022级博士生黄有,通讯作者是张声传副教授,由2024级硕士生陈立超、博士后研究员纪家沂、曹刘娟教授、纪荣嵘教授等共同合作完成。
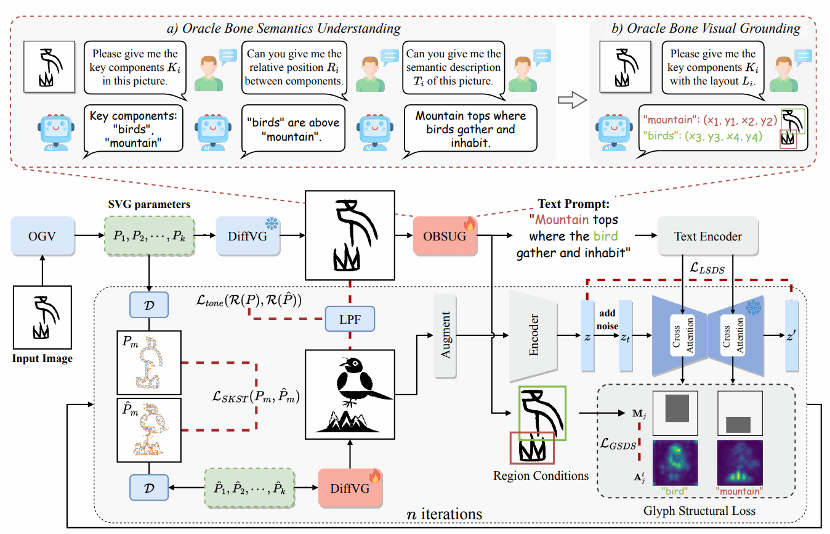
3. OracleFusion: Assisting the Decipherment of Oracle Bone Script with Structurally Constrained Semantic Typography
简介:甲骨文是最早的古代语言之一,它封装了古代文明的文化记录和知识表达。尽管发现了大量的甲骨字,但只有一部分甲骨字被破译。未破译甲骨字具有复杂的结构和抽象的图像,对破译构成了重大挑战。为了应对这些挑战,本文提出一种两阶段语义排版框架 OracleFusion。在第一阶段,利用具有增强空间感知推理(SAR) 的多模态大型语言模型分析甲骨文的字形结构并执行关键组件的视觉定位。在第二阶段,提出了甲骨结构向量融合方法(OSVF)。该方法结合字形结构约束和字形维护约束,确保生成语义丰富的矢量字体。大量的定性和定量实验表明:OracleFusion 在语义、视觉吸引力和字形维护方面优于基线模型,显著提高了甲骨字的可读性和美学质量。此外,OracleFusion 还提供了关于未破译甲骨字的专家级见解,使其成为推进甲骨文破译的宝贵工具。
该论文的共同第一作者是厦门大学信息学院2023级硕士生李曹硕、安阳师范学院丁增茂和腾讯优图胡晓斌,共同通讯作者是金泰松副教授、腾讯优图罗栋豪和安阳师范学院李邦,由汪钺杰(腾讯优图)、吴运声(腾讯优图)、刘永革教授(安阳师范)、纪荣嵘教授等共同合作完成。
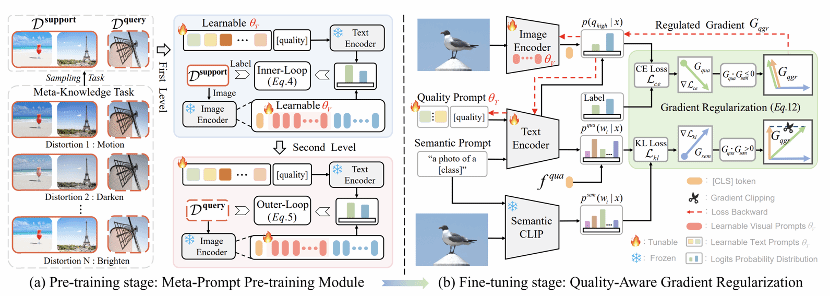
4. Few-Shot Image Quality Assessment via Adaptation of Vision-Language Models
简介:图像质量评估(Image Quality Assessment, IQA)因其复杂的失真条件、多样的图像内容以及有限的可用数据,至今仍是计算机视觉领域一个尚未解决的挑战。现有的盲IQA (BIQA)方法严重依赖广泛的人工标注来训练模型,由于创建IQA数据集的要求高,这是劳动密集型和成本高昂的。为了减轻对标记样本的依赖,本文提出了一种梯度调节元提示IQA框架(GRMP-IQA)。该框架旨在将强大的视觉-语言预训练模型CLIP快速迁移至下游IQA任务,显著提高在数据有限的场景下的准确性。GRMP-IQA包括两个关键模块:元提示预训练模块和质量感知梯度正则化。前者利用元学习范式对软提示进行预训练,使其学习跨不同失真类型的共享元知识,从而实现对各类IQA任务的快速适应;后者则在目标任务微调过程中调整更新梯度,引导模型聚焦于质量相关的特征,以防止对图像的语义信息产生过拟合。实验结果表明,GRMP-IQA在少样本设定下表现优异。此外,仅用20%的训练数据,其表现即可超越大多数现有的全监督BIQA方法。
该论文第一作者是厦门大学人工智能研究院2023级硕士生李旭东,通讯作者是张岩工程师,由郑侠武副教授、曹刘娟教授、纪荣嵘教授等共同合作完成。
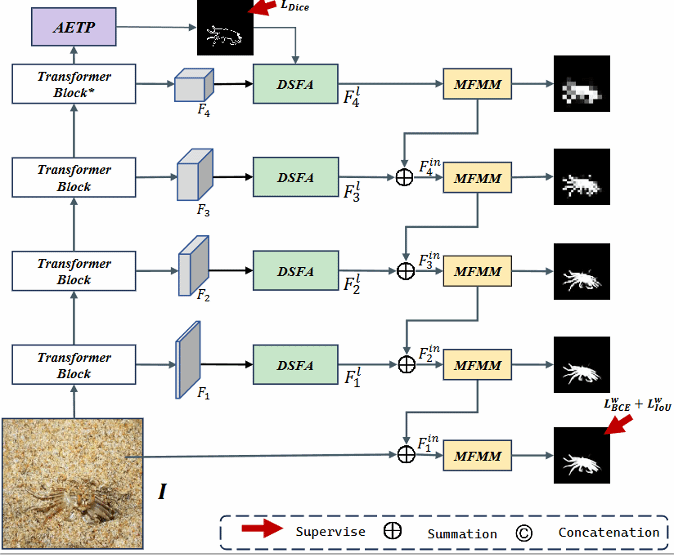
5. ESCNet:Edge-Semantic Collaborative Network for Camouflaged Object Detect
简介:针对伪装目标检测(COD)中目标与背景纹理高度相似导致边界本质模糊,以及现有各种特征方法因边界约束不足常产生断断续续预测的问题,本文提出了具备动态耦合边缘-纹理感知能力的ESCNet框架。该框架的核心创新在于三个协同工作的组件:自适应边缘-纹理感知器(AETP),其融合Transformer全局语义的图像多尺度特征,创建了边缘与纹理信息相互协同引导的边缘预测机制;双流特征增强器(DSFA)则依据局部纹理复杂度和边缘方向动态调整核采样位置,精准强化不规则边界和非定型纹理区域的特征信息;多特征调制模块(MFMM)通过增强边缘感知表征及层级融合多种纹理,为特征校准与模型预测建立了渐进细化的优化过程。这些组件相互关联构成一个闭环反馈系统,增强的边缘感知提升纹理预测,而优化的纹理信息亦反哺边缘感知。在三大权威数据集上的实验充分验证了ESCNet的显著性能优势。
该论文第一作者是厦门大学信息学院2024级硕士生叶胜,通讯作者是林贤明助理教授,由2023级硕士陈馨、张岩工程师、曹刘娟教授等共同合作完成。
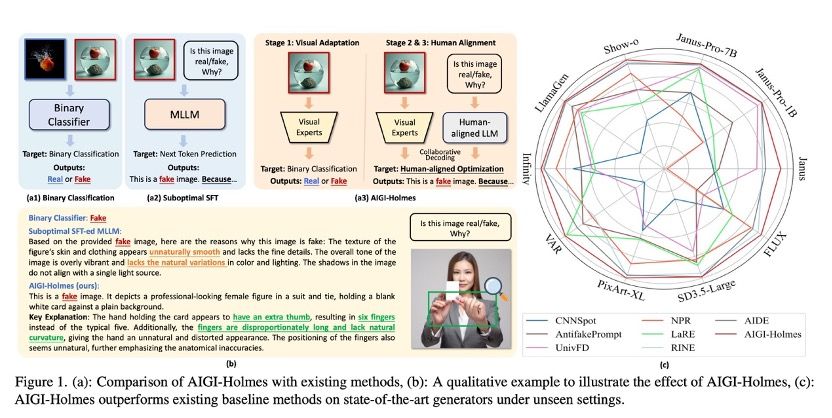
6. AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models
简介:AI生成内容(AIGC)技术的飞速发展,导致高度逼真的AI生成图像(AIGI)被滥用于传播虚假信息,对公共信息安全构成威胁。现有AI生成图像检测技术虽普遍效果良好,但存在缺乏可人工验证的解释依据以及对新一代生成技术(多模态大模型自回归生成图片范式)泛化能力不足这两大缺陷。为此,本文构建了大规模综合数据集Holmes-Set,其包含提供AI图像判定解释的指令微调数据集Holmes-SFTSet,以及人类对齐偏好数据集Holmes-DPOSet。本文还创新提出”多专家评审机制"的高效数据标注方法,该方法通过结构化多模态大语言模型(MLLM)解释增强数据生成,并采用跨模型评估、专家缺陷过滤与人类偏好修正实现质量管控。本文还提出一个Holmes Pipeline三阶段训练框架:视觉专家预训练、监督微调和直接偏好优化,使多模态大语言模型适配AI生成图像检测任务,生成兼具可验证性与人类认知对齐的解释,最终产出AIGI-Holmes模型。推理阶段,本文还引入协同解码策略,融合视觉专家模型感知与MLLM语义推理,进一步强化泛化能力。在三大基准测试中的广泛实验验证了AIGI-Holmes的有效性。
该论文的共同第一作者是厦门大学人工智能研究院2023级硕士生周子寅和和腾讯优图研究员骆云鹏,通讯作者是孙晓帅教授,由吴远尘(腾讯优图)、鄢科(腾讯优图)、丁守鸿(腾讯优图)、吴运声(腾讯优图)、2021级博士生孙可、博士后研究员纪家沂、纪荣嵘教授等共同合作完成。
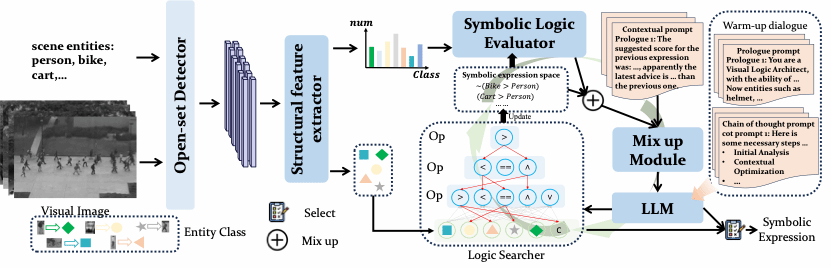
7. From Objects to Events: Unlocking Complex Visual Understanding in Object Detectors via LLM-guided Symbolic Reasoning
简介:本文提出了一个创新的框架,旨在让普通的目标检测器不仅能“看见”物体,更能“理解”正在发生的复杂事件。它通过结合大语言模型(LLM)的引导和符号推理来实现这一目标。其核心是一个“即插即用”的模块,无需进行昂贵的额外训练,可以直接与现有的物体检测器配合使用。该模块会自动分析检测到的物体之间的关联和模式,并由LLM引导,进而发现能够定义一个“事件”的逻辑规则。
该论文第一作者是厦门大学人工智能研究院2024级硕士生曾宇晖,通讯作者郑侠武副教授,由2024级硕士生吴豪翔、2023级硕士生聂文杰、沈云航(腾讯优图)、纪荣嵘教授等共同合作完成。