厦门大学媒体分析与计算实验室共有九篇论文被CVPR 2025接收。IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)是计算机视觉领域的顶级国际会议,CCF A类会议。CVPR2025将于2025年6月11日至15日在美国田纳西州纳什维尔举办。CVPR 2025 共有13,008 份投稿,录用2878篇,录取率为 22.1%。
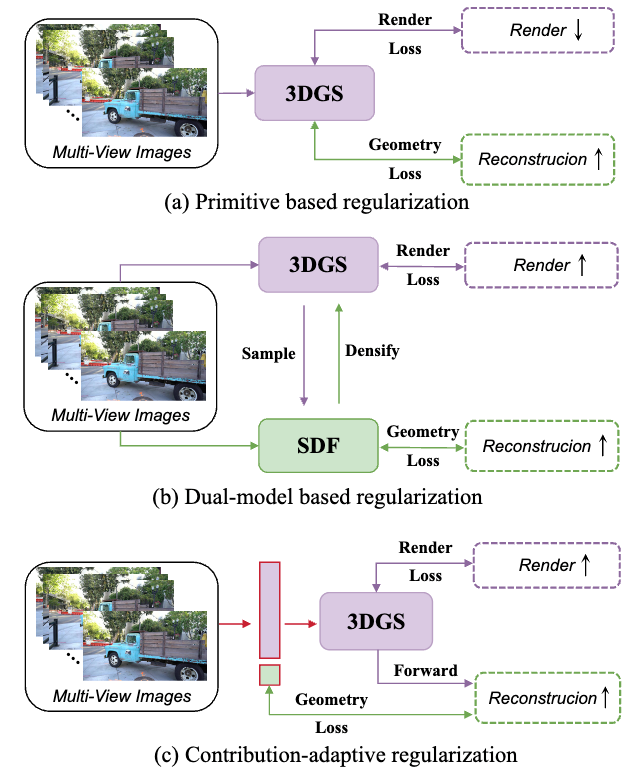
1.Evolving High-Quality Rendering and Reconstruction in a Unified Framework with Contribution-Adaptive Regularization
本文提出了一种基于三维高斯泼溅 (3D Gaussian Splatting, 3DGS)的贡献自适应正则化的统一模型CarGS,用以实现同时进行的高质量渲染和表面重建。此外,本文还引入了一种几何引导的致密化策略,利用法线和符号距离场的线索进一步提升捕获高频细节的能力。本文的框架提升了渲染和几何重建两个任务的互助学习能力,同时其统一的结构无需像双模型方法那样使用单独的模型作用于不同任务,保证了高效性。广泛的实验表明,CarGS能够在保持实时速度和最小存储大小的同时,在渲染保真度和重建精度上实现SOTA的结果。
该论文的共同第一作者是厦门大学信息学院计算机系2024级博士研究生沈优和滴滴创新实验室研究员张志鹏,通讯作者是曹刘娟教授,由2023级博士生李新阳,2023级博士生曲延松,2024级博士研究生林煜、张声传副教授,曹刘娟教授共同合作完成。
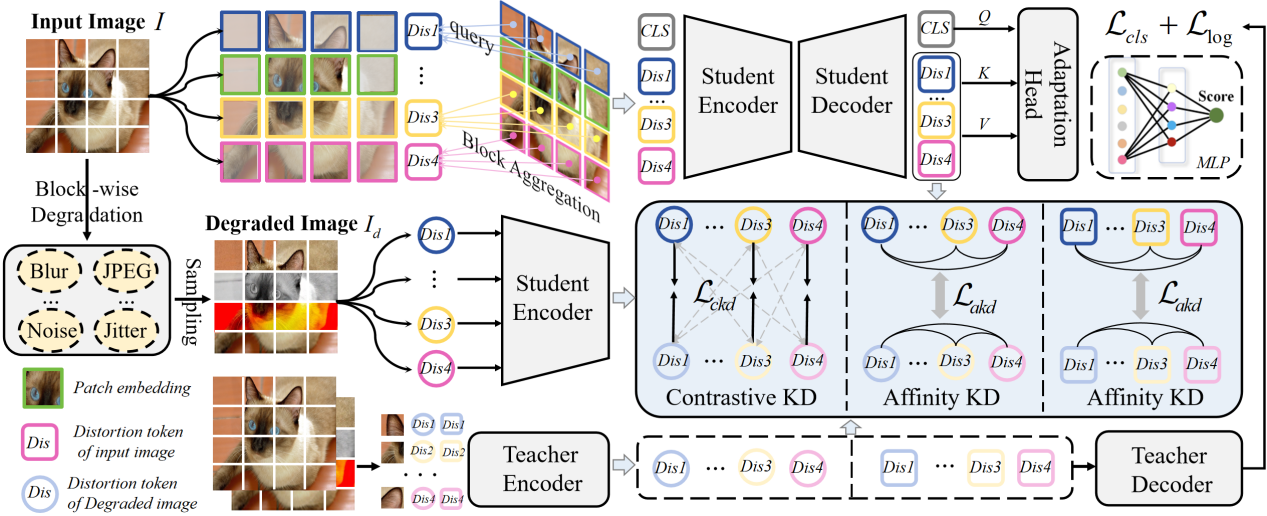
2. Distilling Spatially-Heterogeneous Distortion Perception for Blind Image Quality Assessment
在盲图像质量评价(BIQA)领域,由于自然环境中失真类型的多样性,准确评估真实失真图像的质量是一个巨大的挑战。现有的最先进的IQA方法通过对整个图像施加一系列失真来建立全局失真先验,但这些方法难以有效处理具有空间变化失真的图像。为解决这个问题,本文提出一种新的IQA框架,利用知识蒸馏来感知空间异构失真,增强质量失真感知。具体而言,本文提出了一种基于分块的退化建模方法,对图像的不同空间块应用不同的失真,从而扩展了局部失真先验。在此基础上,本文设计了一个分块聚合和过滤模块,能够对图像中不同失真区域的质量信息进行细粒度关注。此外,为了在保持质量感知的同时增强不同区域失真的感知粒度,本文引入了对比知识蒸馏和亲和知识蒸馏策略,分别学习不同区域的失真判别能力和失真相关性。在多个标准IQA数据集上进行的实验证明了所提出方法的有效性。
该论文第一作者是厦门大学人工智能研究院2023级硕士生李旭东,通讯作者是曹刘娟教授,由张岩工程师、胡润泽副研究员(北京理工大学)、郑侠武副教授等共同合作完成。
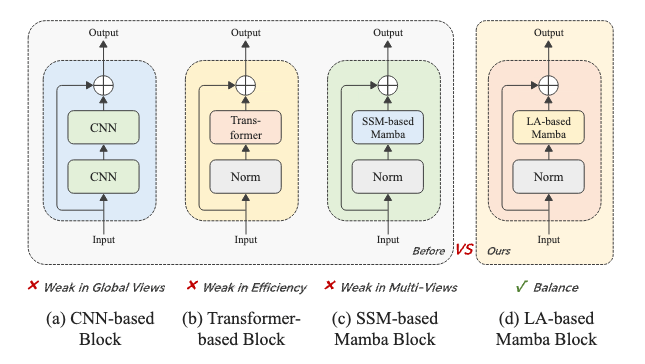
3. ACL: Activating Capability of Linear Attention for Image Restoration
图像修复作为计算机视觉领域的核心课题,在深度学习驱动下已迈入全新阶段。当前基于CNN和Transformer的主流方法虽取得进展,但面临全局感受野受限与计算效率不足的双重挑战。针对这些问题,本研究创新性地提出基于ACL架构的模型:通过利用Mamba模型中状态空间模型(SSM)与线性注意力(linear attention)的表达同构性,采用线性注意力模块取代传统SSM作为编解码器核心,在保持全局感知能力的同时显著提升计算效率。此外,设计的多尺度空洞卷积局部增强模块为模型注入局部学习能力,能有效提取粗细粒度特征以优化局部细节重建。实验表明,该模型在去模糊、去雨等经典IR任务中均取得优异性能,且参数量与计算量(FLOPs)保持较低水平,可为移动端实时图像增强、安防监控画质优化等场景提供了更轻量高效的解决方案。
该论文第一作者为厦门大学信息学院2023级博士生谷雨斌,通讯作者是孙晓帅教授,由2024级硕士生孟媛、博士后研究员纪家沂等共同合作完成。
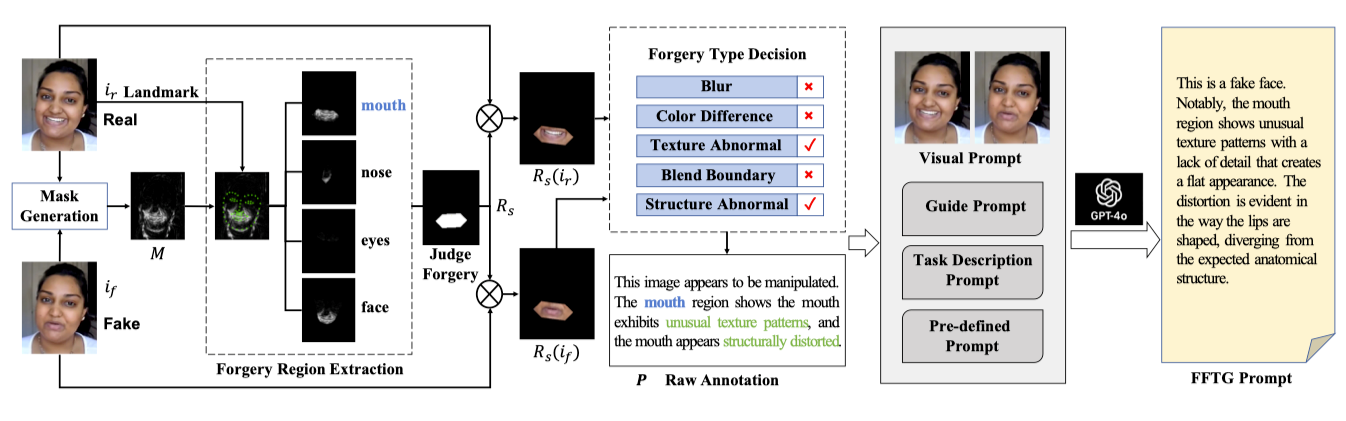
4.Towards General Visual-Linguistic Face Forgery Detection
本文针对面部伪造检测领域中文本注释的质量问题提出了创新性解决方案。随着面部伪造篡改技术的发展,现有的检测方法在泛化能力和可解释性方面面临挑战。本研究提出了一种新型注释方法 Face Forgery Text Generator (FFTG),通过利用伪造掩码进行初始区域和类型识别,结合全面的提示策略来减少多模态大型语言模型中的幻觉问题。FFTG生成的文本注释在识别伪造区域方面显著优于人工标注和直接的GPT标注,准确率提高了27%。基于这些高质量注释,通过微调CLIP和多模态LLM进行验证,实验结果表明本方法不仅能产生更准确的注释,还能提高模型在各种伪造检测基准上的性能。FFTG为多模态伪造检测提供了一种兼具泛化能力和可解释性的方法,为未来多模态取证任务的研究提供了全新的思路。
本文第一作者是厦门大学2021级博士生孙可,通讯作者是孙晓帅教授,由陈燊(腾讯优图)、姚太平(腾讯优图)、林嘉文教授(台湾清华大学),2023级硕士生周子寅、博士后研究员纪家沂、纪荣嵘教授合作完成。
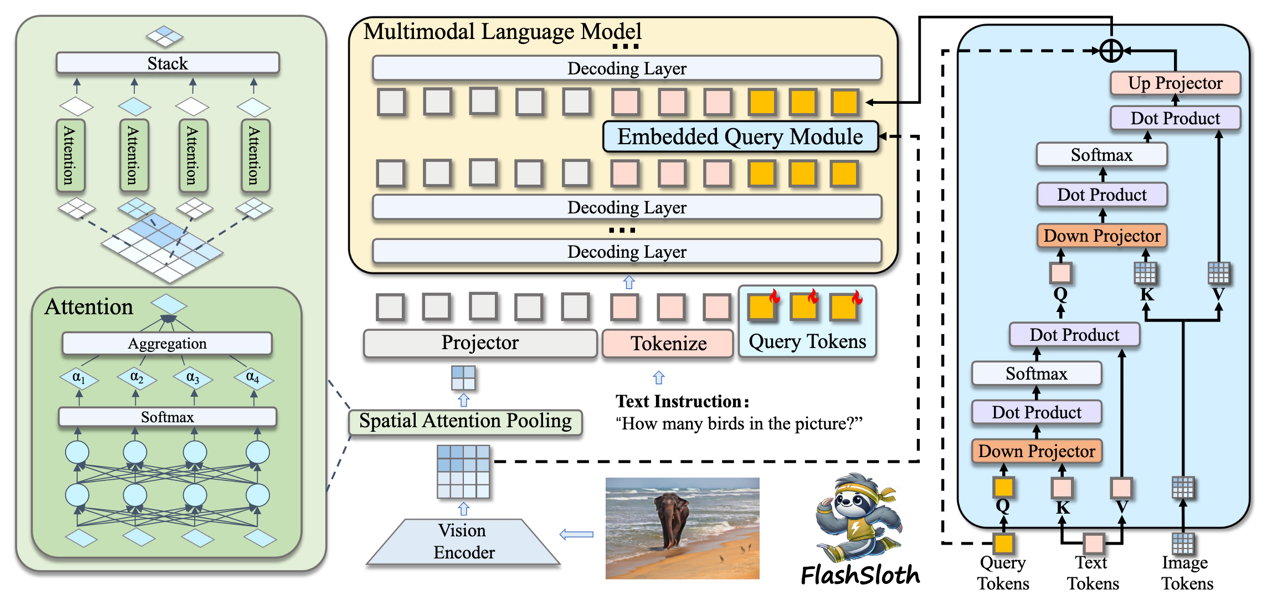
5. FlashSloth: Lightning Multimodal Large Language Models via Embedded Visual Compression
现有多模态大语言模型(MLLM)在性能上有了显著提升,但在实际应用中往往存在响应缓慢和延迟大的问题。近期学术界和工业界都聚焦小型(tiny) MLLM ,但现有工作仍然受限于大量视觉标记的使用,未能达到实际模型加速和快响应的目的。本文提出了一种功能强大且高效的小型MLLM,称为 FlashSloth。FlashSloth 在压缩冗余语义的同时,专注于提升视觉标记的描述能力。具体而言,FlashSloth 引入了嵌入式视觉压缩设计,通过空间注意力池化模块和嵌入式查询模块分别捕捉显著性的和与指令相关的图像信息,从而以更少的视觉标记实现卓越的多模态性能。广泛的实验表明,与 InternVL2、MiniCPM-V2 和 Qwen2-VL 等先进的小参数量MLLM相比,FlashSloth 能够显著提升训练与推理效率,响应时间可以压缩到0.01秒内,同时在多项视觉语言任务上保持高性能。
该论文第一作者为厦门大学信息学院2023级硕士生佟浡,通讯作者是周奕毅副教授,由2021级本科生赖博恺、2021级博士生罗根、沈云航(腾讯优图实验室)、李珂(腾讯优图实验室)、孙晓帅教授、纪荣嵘教授共同合作完成。
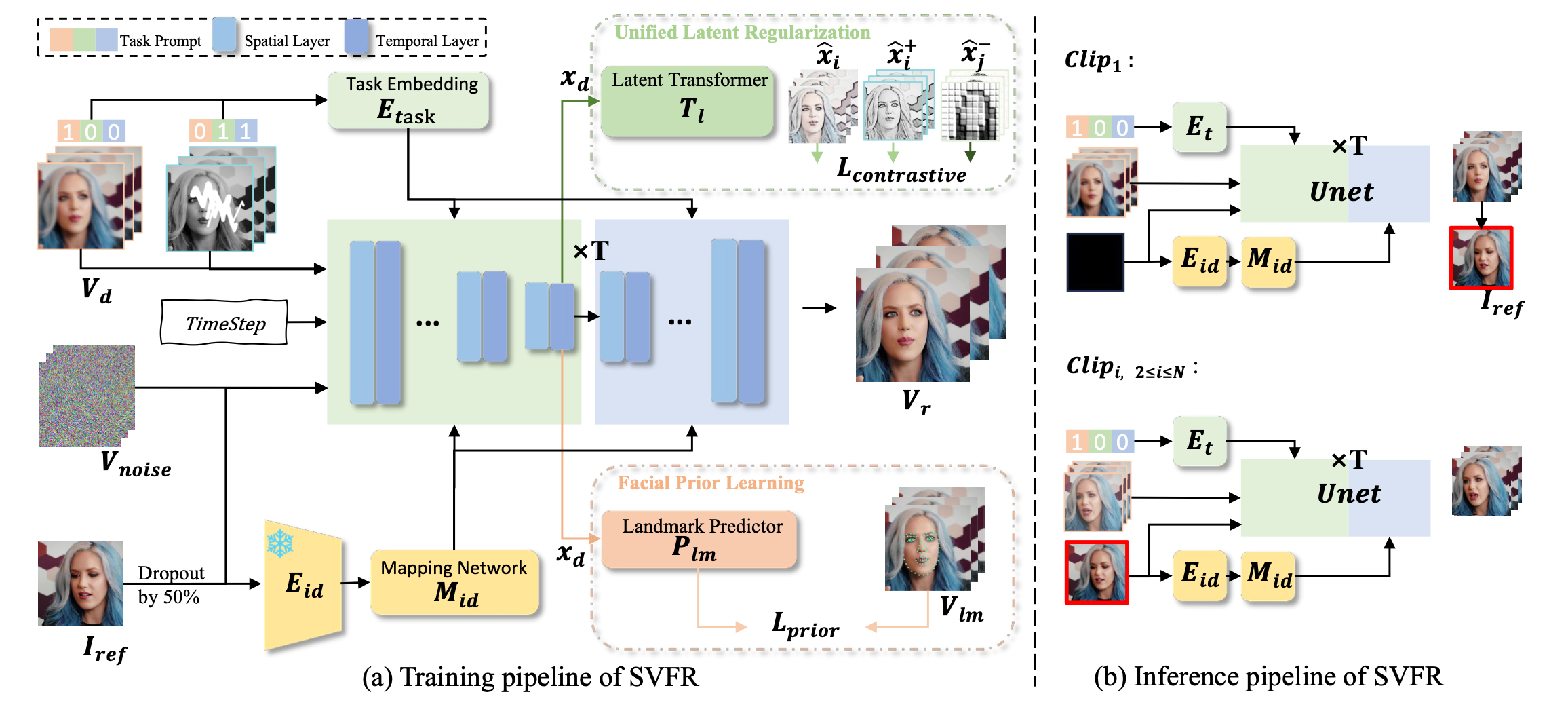
6. SVFR: A Unified Framework for Generalized Video Face Restoration
人脸修复(FR)是图像和视频处理领域的一个重要方向,主要关注从降质的输入中重建高质量的人物肖像。尽管图像人脸修复(FR)已有显著进展,但对视频人脸修复(FR)的探索仍然相对较少,主要由于时序一致性、运动伪影以及高质量视频数据的有限性等挑战。此外,传统的人脸修复通常侧重于提升分辨率,可能未充分考虑到诸如人脸上色和补全等相关任务。本文提出了一种新颖的方法用于广义视频人脸修复(GVFR)任务,该方法整合了视频BFR、补全和上色任务,且通过实验证明这些任务能互有增益。本文设计了一个统一的框架,称为稳定视频人脸修复(SVFR),利用稳定视频扩散(SVD)的生成和运动先验,并通过统一的人脸修复框架融入任务特定信息。本文引入了可学习的任务嵌入以增强任务识别能力,同时采用了一种新颖的统一潜在正则化(ULR)策略,鼓励不同子任务之间共享特征表示学习。为了进一步提升修复质量和时序稳定性,本文引入了面部先验学习和自参考优化作为训练和推理中的辅助策略。所提出的框架有效地结合了这些任务的互补优势,增强了时序一致性并实现了优越的修复质量。该工作推动了视频人脸修复的最新进展,并为广义视频人脸修复奠定了新的范式。
该论文的共同第一作者是厦门大学人工智能研究院2022级硕士生王志遥和2018级硕士毕业生陈旭,共同通讯作者是周奕毅副教授和朱俊伟(腾讯优图),由徐程明(腾讯优图)、汪铖杰(腾讯优图)、2024级博士生刘宇琪、纪荣嵘教授等共同合作完成。
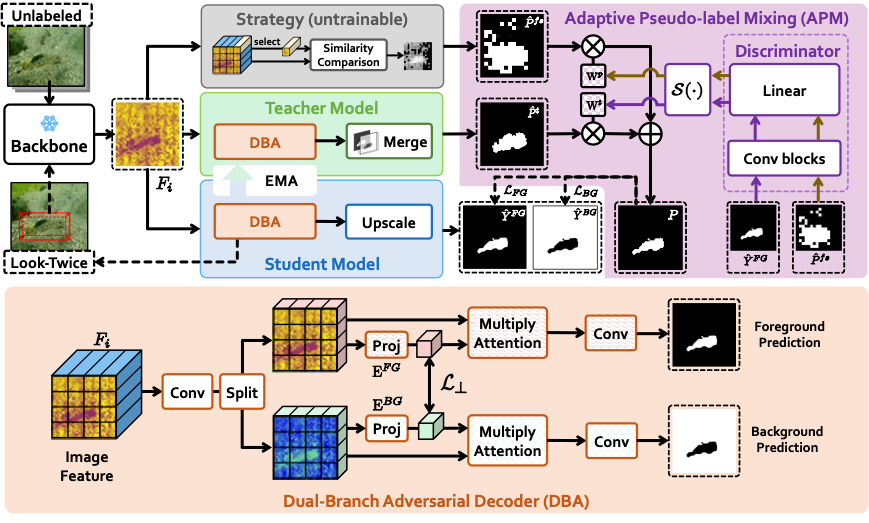
7. UCOD-DPL: Unsupervised Camouflaged Object Detection via Dynamic Pseudo-label Learning
无监督伪装目标检测因其无需依赖大量像素级标注而受到广泛关注。现有方法通常采用固定策略生成伪标签,并使用1x1卷积层作为简单解码器进行训练,导致其性能远低于全监督方法。我们认为现有方法存在两个主要缺陷:1) 固定策略构建的伪标签通常包含大量噪声,模型容易学习到错误的知识;2) 伪标签分辨率较低且前景与背景像素之间存在严重混淆,简单解码器难以有效捕捉和学习伪装目标的语义特征,尤其是在处理小尺度目标时表现较差。为了解决上述问题,我们提出了一个动态伪标签驱动的无监督伪装目标检测框架(UCOD-DPL)。该方法包括自适应伪标签融合模块(APM)、双分支对抗解码器(DBA)以及“二次观察”机制(Look-Twice Mechanism)。其中,APM模块自适应融合由固定策略和教师模型生成的伪标签,以防止模型过度拟合错误知识,同时保持自我纠正能力;DBA解码器通过对不同分割目标的对抗学习,引导模型克服伪装目标的前景-背景混淆问题;“二次观察”机制模拟人眼观察伪装目标时的缩放过程,对小尺度目标进行二次细化处理。实验结果表明,我们的方法表现优异,甚至超越了部分现有的全监督方法。
该论文第一作者是厦门大学信息学院2024级硕士生颜玮琦,通讯作者是张声传副教授,由张岩工程师、曹刘娟教授等合作完成。
8. DVHGNN: Multi-Scale Dilated Vision HGNN for Efficient Vision Recognition
近来,视觉图神经网络(ViG)在计算机视觉领域引起了广泛关注。然而,视觉图神经网络仍面临两个关键问题,包括K近邻(KNN)构图导致的二次计算复杂度以及普通图只能建模数据之间的成对关系。为了解决上述挑战,该文提出了一种新颖的视觉架构,称为空洞视觉超图神经网络(DVHGNN)。该方法设计了聚类和膨胀超图构建方法,能够自适应地捕捉数据样本之间的多尺度依赖关系。此外,提出了一种动态超图卷积机制,实现了超图层级上的视觉特征自适应消息传递。在基准图像数据集进行的实验表明:提出的DVHGNN优于主流的卷积神经网络、视觉Transformer、视觉多层感知机、视觉图神经网络以及视觉Mamba。
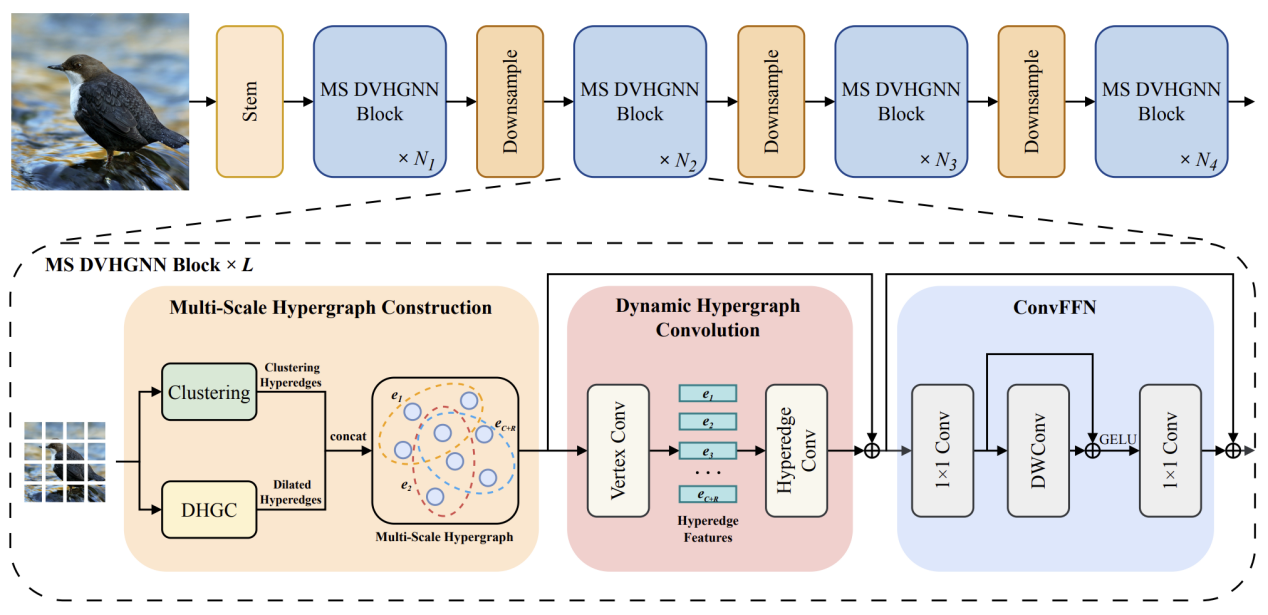
该论文的共同第一作者是厦门大学信息学院2023级硕士生李曹硕和信息学院2024级博士生李谭哲,通讯作者是金泰松副教授,由胡晓斌(腾讯优图)、罗栋豪(腾讯优图)共同合作完成。
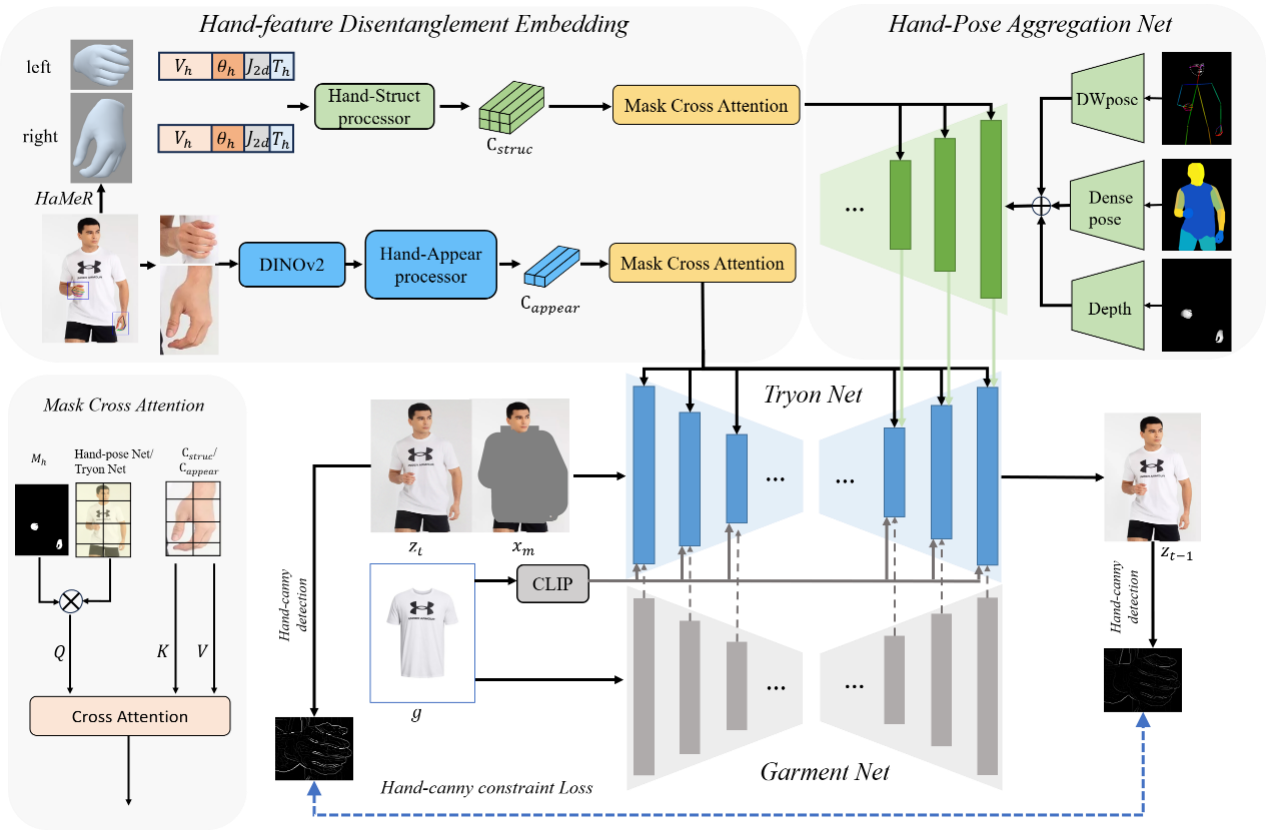
9. VTON-HandFit: Virtual Try-on for Arbitrary Hand Pose Guided by Hand Priors Embedding
该文提出一种基于手部先验增强的虚拟试衣方法VTON-HandFit,以解决扩散模型在手部遮挡场景下的服装失真问题。首先,基于ControlNet架构定制了手部姿势聚合网络,能够显式且自适应地编码全局手部及人体姿势先验。其次,为了充分挖掘手部相关结构与视觉信息,提出了手部特征解耦嵌入模块将手部先验解耦为手部结构参数特征和视觉外观特征,并设计了掩码交叉注意力机制实现特征解耦嵌入。最后,构建手部边缘约束损失,能够从原始模特图像的手部轮廓中更好地学习结构边缘信息。在公共数据集及自建Handfit-3K手部遮挡数据集进行的实验表明:该文提出的方法优于现有主流方法。
该论文共同第一作者是厦门大学信息学院 2022级硕士生梁宇杰和腾讯优图胡晓彬,共同通讯作者是金泰松副教授和腾讯优图罗栋豪,由姜博源(腾讯优图)、汪铖杰(腾讯优图)、纪荣嵘教授等共同合作完成。