2025年1月,人工智能领域国际学术会议ICLR 2025论文接收结果公布,厦门大学媒体分析与计算实验室共有5篇论文被录用。ICLR,全称为「International Conference on Learning Representations」(国际学习表征会议),被认为是深度学习的顶级会议,是新兴的会议,在最新的谷歌学术期刊和会议影响力排名中位列计算机学科前列。ICLR 2025年会议将于4月24日至4月28日在新加坡博览中心举行,本届ICLR共接收了11,565份投稿,录用率为32.08%。

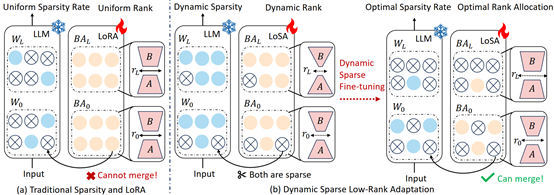
1. Dynamic Low-Rank Sparse Adaptation for Large Language Models
简介:该论文提出了动态低秩稀疏微调(LoSA)方法,在统一框架内将低秩矩阵无缝融入稀疏大语言模型中,从而在不增加推理延迟的情况下提升稀疏大语言模型的性能。具体而言,LoSA在微调过程中,根据相应的稀疏权重对低秩矩阵进行动态稀疏化,从而确保训练后低秩矩阵能够融入稀疏大语言模型。此外,LoSA利用表征互信息作为指标来确定各层的重要性,在微调过程中高效地确定各层的稀疏率。在此基础上,LoSA根据各层重构误差的变化调整低秩矩阵的秩,为每一层分配适当的微调参数,以减少原始模型和稀疏模型之间的输出差异。大量实验表明,LoSA能在数小时内有效降低稀疏模型困惑度,提升零样本精度,同时在CPU和GPU上均能实现推理加速,且不会引入任何额外的推理延迟。
该论文第一作者为厦门大学信息学院2023级硕士生黄伟中,通讯作者是纪荣嵘教授,由2022级博士生张玉鑫、郑侠武副教授、刘杨(华为杭州研究所)、林菁(华为杭州研究所),姚益武(华为杭州研究所)等共同合作完成。
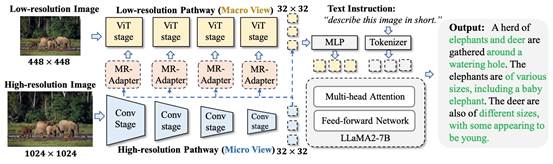
2. Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models
简介:尽管现有的多模态大型语言模型(MLLMs)取得了显著进展,但在细粒度视觉识别方面仍存在不足。与以往研究不同,本文从图像分辨率的角度出发,发现将低分辨率和高分辨率视觉特征相结合可以有效缓解这一问题。基于此,提出了一种新颖且高效的方法——分辨率混合适应(MRA)。MRA为不同分辨率的图像设置了两条视觉路径,并通过新颖的分辨率混合适配器(MR-Adapters)将高分辨率视觉信息嵌入低分辨率路径中,这一设计还大幅减少了MLLMs的输入序列长度。为了验证MRA的有效性,将其应用于一种名为LLaVA的最新MLLM,并将新模型命名为LLaVA-HR。在11个视觉语言(VL)任务上的广泛实验表明,LLaVA-HR在8个VL任务上的表现优于现有的MLLMs。
该论文第一作者是厦门大学信息学院2021级博士生罗根,通讯作者是纪荣嵘教授,由周奕毅副教授、孙晓帅教授、郑侠武副教授和张玉鑫博士共同合作完成。
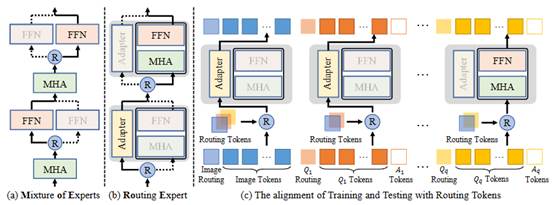
3. Routing Experts: Learning to Route Dynamic Experts in Existing Multi-modal Large Language Models
简介:本文致力于探索现有 MLLM 中的动态专家,并表明标准的MLLM也是专家的混合。本文为现有的MLLM提出了一种新颖的动态专家路由方法,称为路由专家(RoE),该方法可以实现基于示例的最佳路径路由,而无需明显的结构调整。本文还引入了一种新的结构稀疏正则化,以迫使训练有素的 MLLM 学习更多的推理路径。实验结果不仅显示了本文的 RoE 在提高 MLLM 效率方面的有效性,而且在性能和速度方面也比 MoE-LLaVA 具有明显的优势
该论文第一作者为厦门大学人工智能研究院2022级博士生吴穹,通讯作者是周奕毅副教授,由2023级硕士生柯昭熙、孙晓帅教授、纪荣嵘教授共同合作完成。
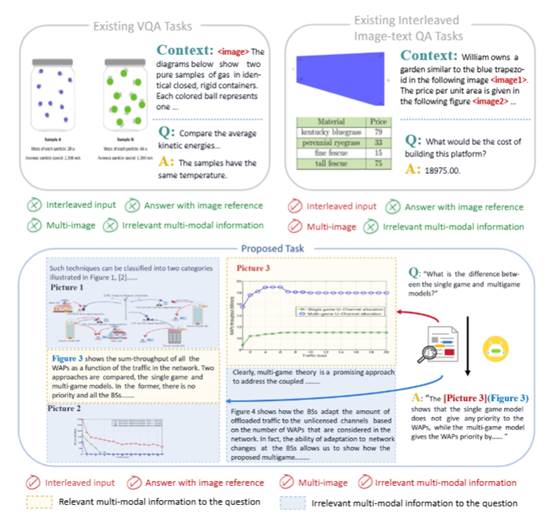
4. VEGA: Learning Interleaved Image-Text Comprehension in Vision-Language Large Models
简介:多模态大型语言模型(MLLMs)的迅速发展展示了它们在处理融合视觉和语言的任务方面的卓越能力,然而,当前大多数模型和Benchmark主要针对的是有限长度的图片和文本上下文的情景。当面对复杂的理解任务时,这些模型往往表现不佳,因为这类任务需要模型处理大量无关甚至可能存在误导性的图文信息。为了解决这一问题,本文引入了一项更具挑战性的任务——交错图文理解(IITC),该任务要求模型能够识别并忽略图像和文本中的多余信息,以准确回答问题,并遵循复杂指令精确定位相关图像。为了评估和提升模型在IITC任务上的表现,本文构建了一个新的VEGA数据集(科学论文领域的IITC任务),并提出一个子任务,即图文关联(ITA)任务,以提升模型的图文关联技能。本文使用VEGA对四个闭源模型以及各种开源模型进行了评估,结果表明,即使是Gemini-1.5-pro和GPT4V这样最先进的闭源模型也仅表现出有限的性能。通过采用多任务、多尺度的后训练策略,本文为MLLMs在IITC任务上设立了一个强大的baseline,在图像关联方面达到了85.8%的准确率和0.508的Rouge得分,这些结果验证了本文的数据集在提升MLLMs对于图文交错信息理解能力方面的有效性。
该论文共同第一作者是厦门大学人工智能研究院2023级硕士生周陈昱、张梦丹(腾讯优图实验室)和陈珮娴(腾讯优图实验室),通讯作者是郑侠武副教授,由傅朝友(腾讯优图实验室)、沈云航(腾讯优图实验室)、孙星(腾讯优图实验室)、纪荣嵘教授等共同合作完成。
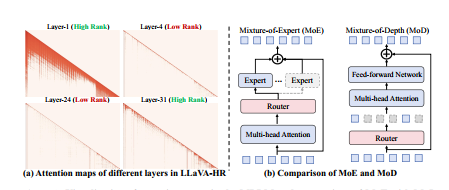
5. gamma-MoD: Exploring Mixture-of-Depth Adaptation for Multimodal Large Language Models
简介:尽管多模态大型语言模型(MLLMs)取得了显著进展,但其高计算成本仍然是实际部署的障碍。受自然语言处理中深度混合(MoDs)的启发,本文从“激活标记”的角度来解决这一限制。关键见解是,如果大多数标记对层计算来说是多余的,可以通过MoD层直接跳过。然而,直接将MLLMs的密集层转换为MoD层会导致性能大幅下降。为了解决这个问题,本文提出了一种创新的MoD适应策略,称为γ-MoD。γ-MoD提出了一个新的指标——注意力图排名(ARank),用于指导MoD在MLLM中的部署。通过ARank,可以有效识别哪些层是多余的,并用MoD层替换。基于ARank,本文进一步提出了两种设计:共享视觉语言路由器和掩码路由学习,以最大限度地提高MLLM的计算稀疏性,同时保持其性能。通过这些设计,MLLM的90%以上的密集层可以有效地转换为MoD层。实验结果验证了γ-MoD对现有MLLM的显著效率优势,并证实了其在各种MLLM上的泛化能力。
该论文第一作者是丹麦技术大学本科生罗亚鑫,通讯作者是厦门大学信息学院2021级博士生罗根,由纪荣嵘教授、周奕毅副教授、孙晓帅教授、纪家沂博士后和MBZUAI 沈志强教授共同合作完成。