近日,国际人工智能顶级会议AAAI 2025论文录用结果揭晓,厦门大学MAC实验共有15篇论文被AAAI 2025录用。
AAAI是由国际人工智能促进协会主办的年会,是人工智能领域中历史最悠久、涵盖内容最广泛的国际顶级学术会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议,每年举办一届。AAAI 2025将于2025年2月25日- 3月4日在美国宾夕法尼亚州费城举办。本届AAAI会议共有12957篇有效投稿,录用3032篇,录取率为 23.4%。
1. Move and Act: Enhanced Object Manipulation and Background Integrity for Image Editing
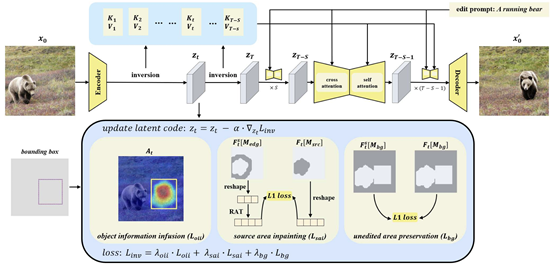
简介:当前常采用反演、重建和编辑的三分支结构的方法来解决一致的图像编辑任务。然而,这些方法缺乏对编辑对象的生成位置的控制,并且在背景保持方面存在问题。为了克服这些限制,本文提出了一种只有反演和编辑两个分支的免微调方法。该方法允许用户同时编辑对象的动作并控制编辑对象的生成位置。此外,本文还实现了更优的背景保持,即在反演过程中的特定时间步将被编辑对象的信息传输到目标区域并修复或保持其他区域的背景。编辑阶段,在自注意力机制中使用图像特征来查询反演过程中对应时间步的键和值,以实现一致的图像编辑。定性的图像编辑结果和定量的评估实验证明了本文方法的有效性。
该论文第一作者是厦门大学信息学院2023级硕士生蒋鹏飞,通讯作者是晁飞副教授,由林明宝(新加坡Skywork AI 2050研究院)共同合作完成。
2. Memory-reduced Meta-learning with Guaranteed Convergence
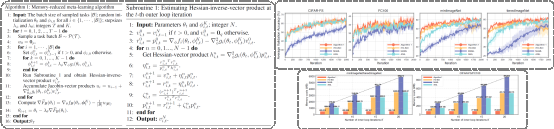
简介:基于优化的元学习方法因其利用少量数据快速适应新任务的独特能力而受到越来越多的关注。然而,现有的基于优化的元学习方法,如MAML、ANIL及它们的变体方法,通常直接使用反向传播来进行上层(超)梯度估计。由于需要存储和使用历史下层参数或者梯度,导致在每次迭代中都增加了计算和内存开销。本文提出了一种元学习算法,与现有的基于优化的元学习方法相比,在超梯度估计中避免了使用历史参数或梯度,并显著减少每次迭代所需的内存成本。本文证明了所提出的算法可以实现随上层优化的迭代次数以次线性速度收敛,并且收敛误差随采样任务的批量大小以次线性速度衰减。在确定性元学习的情况下,本文证明了所提出的算法可以收敛到一个精确解。本文量化了该算法的计算复杂度为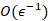 ,该复杂度与现有的元学习方法收敛结果相匹配,但本文提出的算法并不需要使用任何历史参数或者梯度。最后,在元学习基准数据集上的实验结果验证了所提出算法的有效性。
,该复杂度与现有的元学习方法收敛结果相匹配,但本文提出的算法并不需要使用任何历史参数或者梯度。最后,在元学习基准数据集上的实验结果验证了所提出算法的有效性。
该论文第一作者是厦门大学航空航天学院自动化系2023级博士生杨宏林,通讯作者是航空航天学院自动化系马骥助理教授,合作作者是人工智能研究院喻骁教授。
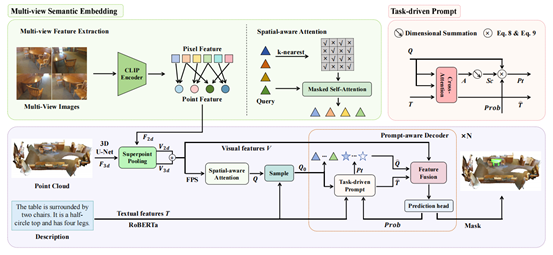
3. IPDN: Image-enhanced Prompt Decoding Network for 3D Referring Expression Segmentation
简介:三维指向性目标分割(3D-RES)的目的是基于给定的文本描述对点云场景进行分割。然而,现有的3D-RES方法面临着两个主要的挑战:特征模糊和意图模糊。特征模糊是由于照明和视角等限制,在点云采集过程中存在信息丢失或失真而引发的。意图模糊是指模型在解码过程中对所有查询的平等处理,缺乏自上而下的任务特定的指导。本文引入了一种图像增强的提示解码网络(IPDN),它利用多视角图像和任务驱动信息来增强模型的推理能力。为了解决特征模糊问题,本文提出了多视角语义嵌入模块,该模块将多视图二维图像信息注入到三维场景中,并补偿潜在的空间信息损失。为了解决意图模糊问题,本文设计了一个提示感知解码器,它通过从文本和视觉特征之间的交互中获得任务驱动的信号来指导解码过程。综合实验表明,IPDN在3D-RES和3D-GRES任务上的mIoU指标上分别比目前最先进的模型高1.9和5.4个点。
该论文共同第一作者是厦门大学信息学院人工智能系2023级硕士生陈琦和2024级博士生吴昌鲡,通讯作者为博士后研究员纪家沂,由2023级博士生马祎炜、2022级硕士生杨丹妮以及孙晓帅教授共同合作完成。
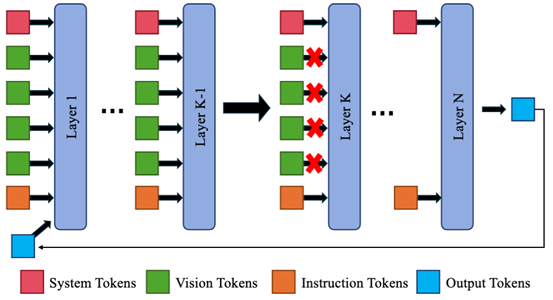
4. Boosting Multimodal Large Language Models with Visual Tokens Withdrawal for Rapid Inference
简介:本文提出了一种即插即用的模块(VTW),旨在加速多模态大语言模型(MLLMs)的推理过程。VTW 的设计灵感来源于以下两点关键观察:1)注意力下沉现象:在大语言模型(LLMs)中普遍存在的注意力下沉(Attention Sink)现象同样出现在多模态大语言模型(MLLMs)中。2)信息迁移现象:VTW 首次发现并验证了视觉令牌(visual tokens)携带的信息会在 MLLMs 的前几层迁移到后续的文本令牌中。推断视觉令牌在 MLLMs 的深层网络中并非必需。据此,我们创新性地提出在模型的特定层提前移除视觉令牌,以减少计算开销。实验结果表明,VTW 在各种多模态任务和对话机器人场景中,能够显著提升 MLLMs 的推理效率,同时保持性能不受影响。
该论文第一作者是厦门大学信息学院人工智能系2024级博士生林志航,通讯作者是纪荣嵘教授,由林明宝(新加坡Skywork AI 2050研究院)、2024级硕士生林卢希共同合作完成。
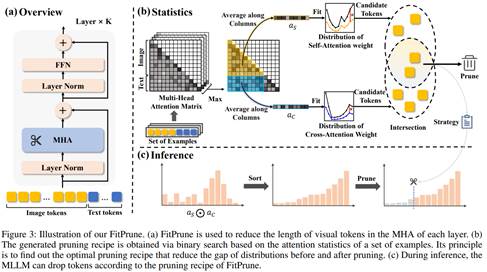
5. Fit and Prune: Fast and Training-free Visual Token Pruning for Multi-modal Large Language Models
简介:多模态大语言模型(MLLMs)虽然发展迅速,但存在视觉信息冗余和计算成本高的问题。通过观察发现模型中存在大量冗余的视觉标记,本文提出 FitPrune 方法,该方法将视觉标记修剪任务视作注意力分布拟合问题,通过统计来确定最优策略,推理时依据统计得到的策略进行标记剪枝。 在10 个基准数据集上的实验结果显示 FitPrune 方法能大幅降低计算复杂度的同时保持性能不变,如在 LLaVA-NEXT数据集上减少 54.9% FLOPs 而准确率仅降 0.5%,这相比于其他方法优势明显。本文还通过消融实验验证该方法的有效性和鲁棒性。实验证明,FitPrune 为 MLLMs 优化提供了实用且高效的方案,降低模型运行开销且易部署,有助于视觉-语言任务的发展。
该论文第一作者为厦门大学人工智能研究院2023级硕士生叶伟豪,通讯作者是周奕毅副教授,由2022级博士生吴穹、2024级硕士生林文浩共同合作完成。
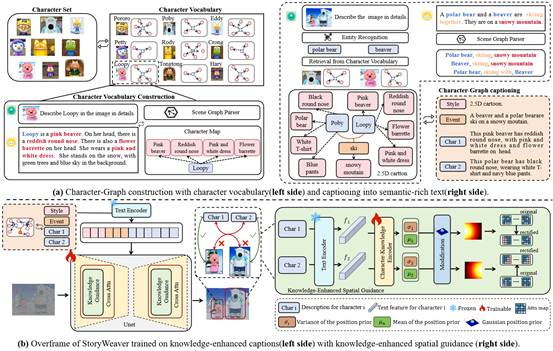
6. StoryWeaver: A Unified World Model for Knowledge-Enhanced Story Character Customization
简介:故事可视化任务指的是给定一段故事文本和故事中出现的角色图片,模型逐句生成包含指定角色的图像来描绘故事的发展。现有方法存在图像与文本语义匹配度不高、角色定制化效果差、多角色交互图像生成质量差等问题。基于此,本文提出一个统一的世界模型(StoryWeaver),通过角色定制化实现高质量的故事可视化。本文首先提出一种知识增强的角色图谱,用于表示故事世界中具有丰富语义的角色、事件及其对应属性的信息,再将故事场景图结构化地表示为角色图谱的文本表达形式。模型在知识增强后的文本上进行训练,实现高保真的角色定制化效果。此外,为了解决多角色交互图像生成中的身份混淆问题,本文提出了一种基于角色知识感知的空间引导方法,该方法利用可训练的知识编码器对扩散模型图像生成中的交叉注意力矩阵进行修正,以纠正文本注意力在图像上的错误分配。为了验证模型性能,本文提出一个新的基准数据集TBC-Bench。 在该基准数据集上的实验结果表明,StoryWeaver在单个角色和多角色故事可视化任务中,均能实现更优的角色定制化和文本语义匹配效果。
该论文的共同第一作者是厦门大学信息学院人工智能系2024级博士生张金璐和网易伏羲实验室研究员唐霁霁,通讯作者是孙晓帅教授,由张荣升(网易伏羲)、吕唐杰(网易伏羲)共同合作完成。
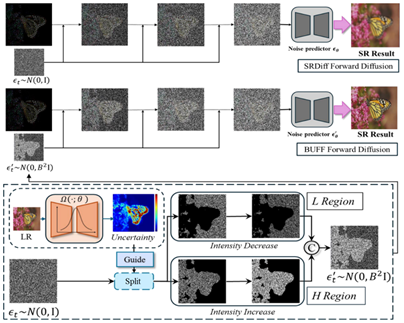
7. BUFF: Bayesian Uncertainty Guided Diffusion Probabilistic Model for Single Image Super-Resolution
简介:超分辨率(SR)技术对于提高图像质量至关重要,尤其是在需要高分辨率图像但又受到硬件限制的情况下。现有的超分辨率扩散模型主要依赖高斯模型来生成噪声,但在处理自然场景中固有的复杂多变的噪声时,高斯模型往往显得力不从心。为了解决这些不足,本文引入了贝叶斯不确定性引导扩散概率模型(BUFF)。BUFF 的与众不同之处在于它结合了贝叶斯网络来生成高分辨率的不确定性掩码。这些掩码为扩散过程提供指导,允许以一种上下文感知和自适应的方式调整噪声强度。这种新颖的方法不仅提高了超分辨图像与原始高分辨率图像的保真度,还显著减少了以复杂纹理和精细细节为特征的区域的伪影和模糊。该模型对复杂噪声模式表现出卓越的鲁棒性,并在处理图像中的纹理和边缘方面展现出超强的适应性。由视觉结果支持的经验证据说明了该模型的鲁棒性,尤其是在具有挑战性的场景中,以及在解决模糊等常见 SR 问题方面的有效性。在 DIV2K 数据集上进行的实验评估显示,BUFF 实现了显著的改进,在 BSD100 上的 SSIM 与基线相比提高了 +0.61,超过了传统的扩散方法,平均多提高了 +0.20dB PSNR。这些发现强调了贝叶斯方法在增强 SR 扩散过程中的潜力,为该领域未来的发展铺平了道路。
该论文的第一作者是厦门大学人工智能研究院2022级硕士生何子豪,通讯作者是张岩工程师,由张声传助理教授等共同合作完成。
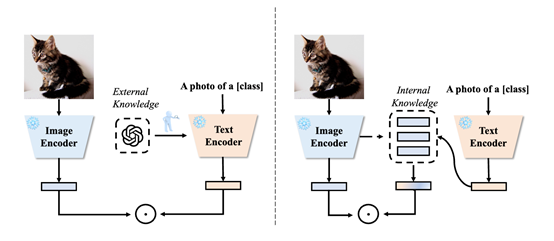
8. TextRefiner: Internal Visual Feature as Efficient Refiner for Vision-Language Models Prompt Tuning
简介:现有提示学习方法主要以在所有类别中共享的粗粒度的方式学习下游任务的提示,从而实现将视觉-语言模型迁移。这些类间共享的提示通常难以识别特定类别的细粒度视觉概念,从而影响了提示在具有相似视觉属性任务上的泛化性能。现有方法通过利用大型语言模型的外部知识来生成细粒度的类别描述,补充视觉概念,从而缓解这一问题。但其代价是显著增加了推理成本,同时需要复杂的模块来保证外部知识和下游分布对齐。本文提出了一种即插即用的组件TextRefiner,通过利用VLM的内部知识来补充现有文本提示的细粒度视觉概念信息。配备 TextRefiner 后,PromptKD 实现了最先进的性能,超过了依赖外部专家的 LLaMP,性能。此外,TextRefiner 展现出了极高的推理效率,CoCoOp推理速度为20.45 FPS,LLaMP推理速度为1473.46 FPS,而搭载 TextRefiner 的 PromptKD 则达到了 12793.26 FPS。
该论文第一作者是厦门大学信息学院计算机系2023级硕士生谢晶晶,通讯作者是曹刘娟教授,由2021级博士生张玉鑫、2019级博士生彭军、2023级硕士生黄钊宏共同合作完成。
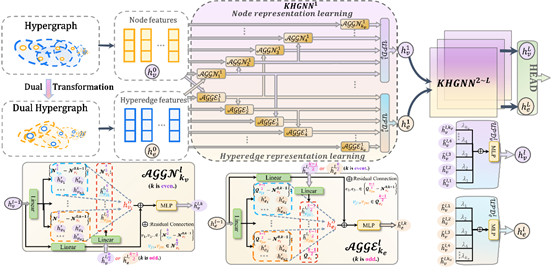
9. K-hop Hypergraph Neural Network: A Comprehensive Aggregation Approach
简介:超图神经网络(HGNNs)能够建模多个数据样本之间高阶关系,然而现有超图神经网络面临着过挤压和过平滑的问题。本文提出一种新颖的K跳超图神经网络(KHGNN),该方法通过引入远距离节点和超边之间交互缓解以上问题。具体来说,采用基于HyperGINE的二分嵌套卷积提取来自沿节点或超边之间的所有最短路径上的节点、超边和结构信息作为路径特征,从而提供远距离关系的表示。借助全面的路径特征,超图神经网络的节点和超边能够聚合远距离信息,提高了神经网络表示能力。在标准数据集,特别是在长距离图数据集上的实验结果表明,本文提出的方法超过了现有主流的超图神经网络和图神经网络,取得了最优的学习性能。
该论文第一作者是厦门大学信息学院2022级硕士生谢林煌,通讯作者是金泰松副教授,由2022级硕士生高世豪等共同合作完成。
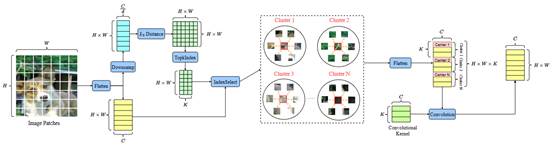
10. Dynamic Clustering Convolutional Neural Network
简介:卷积神经网络一直在计算机视觉领域中占据重要地位。然而,目前流行的卷积神经网络通常依赖于局部窗口建模,限制了其捕捉图像中长距离依赖关系的能力。为了解决这些局限性,本文提出了一种新颖的卷积神经网络架构——动态聚类卷积神经网络。该方法通过全局聚类将具有相似语义的图像块分组为簇,然后使用共享卷积核对这些簇进行卷积。为了解决全局聚类的高计算复杂性,该方法从每个图像块的子空间中提取特征向量来进行高效聚类,从而使得该模型能够广泛适配于各种下游视觉任务。在基准数据集上的图像分类、目标检测、实例分割和语义分割的大量实验表明:本文所提的方法在性能上优于主流的卷积神经网络、视觉Transformer、视觉多层感知机、视觉图神经网络以及视觉Mamba。。
该论文第一作者是厦门大学信息学院2024级博士生李谭哲,通讯作者是金泰松副教授,由张宝昌教授(北京航空航天大学),郑侠武副教授等合作完成。
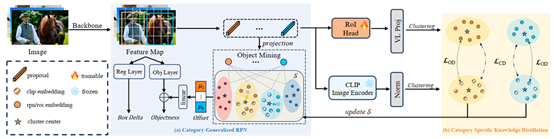
11. CAKE: Category Aware Knowledge Extraction for Open-Vocabulary Object Detection
简介:本文提出了一种用于开放词汇目标检测的类别感知知识蒸馏方法。该方法包括两个模块:类别泛化区域提议网络(CG-RPN)和类别特定知识蒸馏分支(CSKD),能够显著提高检测器对于未见类别的零样本泛化能力。CG-RPN通过利用CLIP的高质量特征构建特征集用于区分前景和背景提议,提高了检测器在新类别上的召回率;CSKD则拉近相同类别物体的聚类中心,有利于检测器学习到类别特定的语义知识。CAKE在开放词汇目标检测相关benchmark上达到了新的最佳性能。
该论文第一作者是厦门大学人工智能系2023级硕士生马世元,通讯作者是张声传助理教授,由2023级硕士生钱东麟,2024级博士生叶锴共同合作完成的。
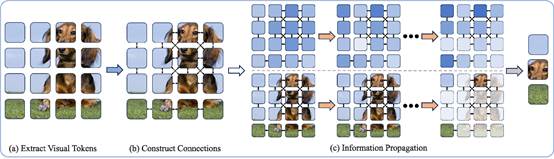
12. What Kind of Visual Tokens Do We Need? Training-free Visual Token Pruning for Multi-modal Large Language Models from the Perspective of Graph
简介:多模态大语言模型(MLLMs)在处理视觉-语言(VL)任务时,通常使用大量的视觉标记来弥补其视觉处理的不足,但这也导致了计算开销的增加和视觉冗余问题。现有方法虽然通过增加图像分辨率和视觉标记数量提升了视觉推理能力,但往往伴随过多冗余信息,尤其在一些精细任务(如TextVQA)中,过多的视觉标记反而可能影响模型表现。基于此,本文提出了一种基于图的视觉标记修剪方法(G-Prune),旨在通过有效选择关键的视觉标记来减少计算负担并提升模型效率。本文首先通过分析不同类型的视觉标记在多模态推理中的重要性,发现前景和背景标记对MLLMs都是至关重要的,尤其在任务难度不同的情况下,两者的作用各有不同。基于这一观察,本文提出了一种将视觉标记视为图节点,并根据其语义相似度构建连接的图方法。通过迭代的信息传播算法,模型能够自动更新每个标记的重要性,最终保留对任务最有贡献的标记,从而减少冗余计算。为了验证G-Prune的有效性,本文将该方法应用于多模态大语言模型LLaVA-NeXT,并在多个基准数据集上进行了广泛的实验。实验结果表明,G-Prune能够显著降低计算开销,同时在多个视觉-语言任务中保持高性能。
该论文的共同第一作者是厦门大学信息学院人工智能系2023级研究生蒋雨涛和人工智能研究院2022级博士生吴穹,通讯作者是周奕毅副教授,由2024级硕士生林文浩、2022级硕士生余薇共同合作完成。
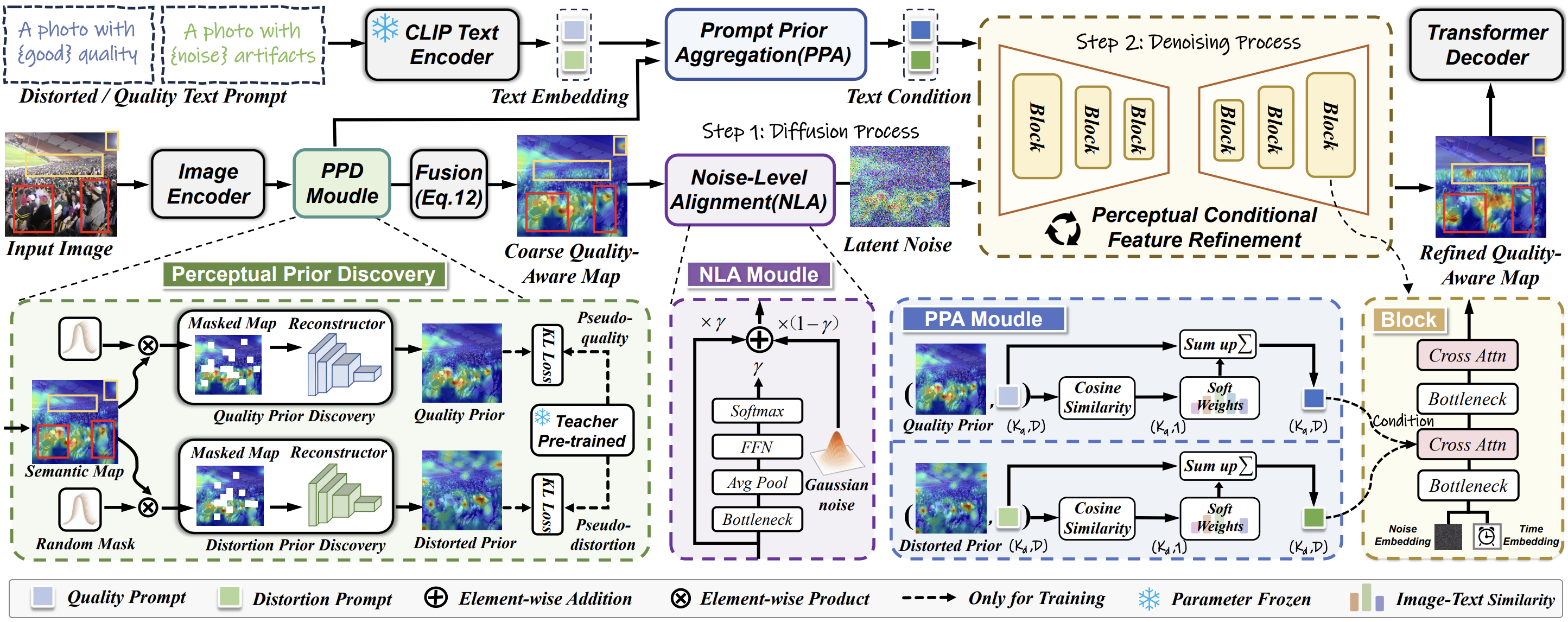
13. Feature Denoising Diffusion Model for Blind Image Quality Assessment
简介:盲图像质量评价(BIQA)旨在在没有参考基准的情况下,对图像质量进行符合人类感知的评价。目前,深度学习BIQA方法通常依赖于使用来自高层任务的特征进行迁移学习。然而,BIQA与这些高级任务之间的固有差异不可避免地将噪声引入到质量感知特征中。本文初步探索了BIQA任务中用于特征去噪的扩散模型,即感知特征扩散IQA方法(PFD-IQA),旨在从质量感知特征中去除噪声。具体来说,1)提出一种感知先验发现和聚合模块,建立两个辅助任务,以发现图像中潜在的低层特征,用于为扩散模型聚合质量感知的文本条件。2)提出一种感知条件特征细化策略,将噪声特征与预定义的去噪轨迹进行匹配,然后基于质量感知的文本条件进行精确的特征去噪。通过合并一个轻量级去噪器,并且只需要几个特征去噪步骤,所提出方法在多个标准BIQA数据集上表现出优越的性能。
该论文第一作者是厦门大学人工智能研究院2023级硕士生李旭东,通讯作者是张岩工程师,由胡润泽副研究员(北京理工大学),郑侠武副教授等共同合作完成。
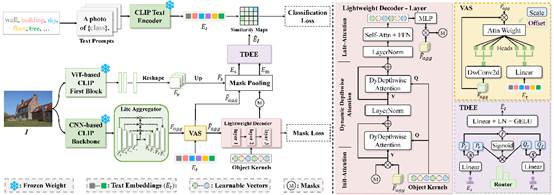
14. EOV-Seg: Efficient Open-Vocabulary Panoptic Segmentation
简介:开放词汇全景分割旨在对任意词汇表中不同场景的所有物体进行分割。现有方法中两阶段框架通常使用掩码生成器生成的掩码多次裁剪图像,然后进行特征提取,而单阶段框架依靠重量级掩码解码器通过多个堆叠的 Transformer 块中的自注意力和交叉注意力来弥补空间位置信息的不足。这两种方法都会产生大量的计算开销,从而阻碍模型推理的效率。为了填补效率方面的空白,本文提出了一种新颖的单阶段、共享、高效的框架,并引入两个将基线提升到强大的EOV-Seg框架的优雅设计。首先,本文提出了一个词汇感知选择模块来提高对视觉聚合特征的语义理解并减轻掩码解码器上的特征交互负担。其次,本文引入了双向动态嵌入专家,它有效地利用了基于 ViT 的 CLIP 主干网络的空间感知能力,使用权重分配路由器动态分配嵌入专家权重,以生成具有语义感知和空间感知的实例嵌入,用于掩码识别。据我们所知,EOV-Seg 是第一个面向效率的开放词汇全景分割框架,与最先进的方法相比,它运行速度更快,性能更具竞争力,实现了速度与性能的最佳权衡。
该论文第一作者是厦门大学人工智能研究院2023级硕士生牛鸿伟,通讯作者是张声传助理教授,由胡杰(新加坡国立大学博士后研究员)、2023级博士生林将航、江冠南(宁德时代)共同合作完成的。
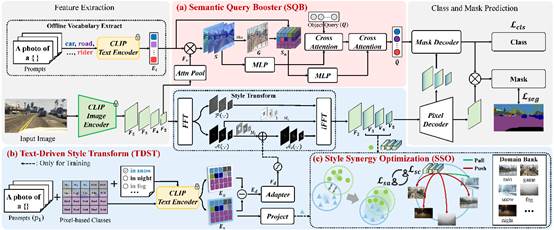
15. Exploring Semantic Consistency and Style Diversity for Domain Generalized Semantic Segmentation
简介:域泛化语义分割 (DGSS) 旨在利用源域数据增强跨未知目标域的语义分割泛化。当前的研究主要集中在特征归一化和域随机化,这些方法表现出明显的局限性。基于特征归一化的方法在约束特征空间分布的过程中往往会混淆语义特征,导致分类误判。基于域随机化的方法由于风格转换的不可控性,经常会包含与领域无关的噪声,从而导致分割模糊。为了应对这些挑战,本文引入了一个用于语义一致性预测和风格多样性泛化的新颖框架,名为 SCSD。它包含三个关键组件:首先,语义查询增强器旨在增强掩码解码器中对象查询的语义感知和辨别能力,实现跨域语义一致性预测。其次,本文提出了一个文本驱动的风格转换模块,利用域差异文本嵌入可控地引导图像特征的风格转换,从而增加域间风格多样性。最后,为了防止相似域特征空间的崩溃,本文引入了一种风格协同优化机制,通过协同加权风格对比损失和风格聚合损失来强化域间特征的分离和域内特征的聚合。大量实验表明,所提出的 SCSD 明显优于现有的最先进方法。
该论文第一作者是厦门大学人工智能研究院2023级硕士生牛鸿伟,通讯作者是张声传助理教授,由2022级硕士生谢林煌、2023级博士生林将航共同合作完成的。