近日,欧洲计算机视觉国际会议European Conference on Computer Vision(ECCV 2024)公布了论文的收录结果,厦门大学多媒体可信感知与高效计算教育部重点实验室十篇论文被录用。ECCV是国际顶尖的计算机视觉会议之一,每两年举行一次。ECCV 2024论文总投稿数约12600篇,其中2395篇论文中选,录用率为18%,录用论文简要介绍如下:
1. AccDiffusion: An Accurate Method for Higher-Resolution Image Generation
为解决高分辨率图像生成中的物体重复生成问题,本文提出了AccDiffusion方法。AccDiffusion首先引入了块内容感知提示,这可以使每个块的去噪更加准确,从而从根源上避免重复生成物体。然后,进一步提出了具有窗口交互的膨胀采样,用以增强高分辨率图像生成过程中的全局一致性。包括定性和定量结果在内的大量实验表明,AccDiffusion可以成功地进行无重复高分辨率的图像生成。

该论文第一作者是信息学院人工智能系2022级硕士生林志航,通讯作者是纪荣嵘教授,由林明宝(新加坡Skywork AI 2050研究院)、赵朦(腾讯)共同合作完成。
2. Enhancing Tampered Text Detection through Frequency Feature Fusion and Decomposition
文档图像篡改对信息的真实性构成了严重威胁,其潜在后果包括虚假信息传播、金融欺诈和身份盗窃。虽然目前的检测方法可利用频率信息来发现肉眼不可见的篡改痕迹,但它们往往无法精确地整合这些信息,也无法增强对检测细微篡改至关重要的高频成分。为了解决这些问题,本文提出了一种新的文档图像篡改检测 (DITD) 方法——特征融合与分解网络 (FFDN)。该方法将视觉增强模块 (VEM) 与类小波频率增强 (WFE) 相结合,以提高对细微篡改痕迹的检测能力。具体而言,VEM 增强了对细微篡改痕迹检测的同时保持了原始 RGB 检测能力的完整性。同时,WFE 将特征进一步分解为高频和低频分量,强调微小但关键的篡改细节。在 DocTamper 数据集上的严格测试证实了 FFDN 的优势,其在检测篡改方面明显优于现有的最先进方法。

该论文第一作者是人工智能研究院2022级硕士生陈忠淅,通讯作者是林贤明助理教授,由腾讯优图实验室陈燊、姚太平、丁守鸿以及厦门大学2021级博士生孙可、曹刘娟教授、纪荣嵘教授共同合作完成。
3. Exploring Phrase-Level Grounding with Text-to-Image Diffusion Model
近两年,文本到图像(Text-to-Image,T2I)扩散模型在细粒度文本提示下,展现出高质量的图像生成能力,这表明扩散模型的表征与高级语义概念高度关联。探索T2I扩散模型在短语级理解的判别式任务的潜能,有助于拓展扩散模型的多元应用。本文使用全景叙事定位(PNG)任务作为代理任务对上述问题展开研究。PNG是一个phrase-pixel级感知任务,需要模型对图像有很好的语义理解。首先,本文重新定义PNG为一个从定位-分割-细化的零样本问题,并提出DiffPNG方法。具体而言,本文提出了定位-分割处理器(LSP)模块,它利用 T2I 扩散模型中的 Cross-Attention机制来定位锚像素,并通过Self-Attention机制进行聚合得到粗糙的含有文本语义信息的预测掩码。此外,本文进一步提出了主语词聚焦的特征聚合器(SFFA)模块去更好地利用主语词在Cross-Attention机制对掩码的贡献;最后,本文提出了基于SAM的掩码细化(SMR )策略,利用 SAM 模型的分割能力去进一步细化分割掩码。在 PNG 基准数据集上,相比其他的 Diffusion-based 的零样本方法,DiffPNG实现了最佳的性能,证明了T2I扩散模型在短语级理解视觉内容的能力。
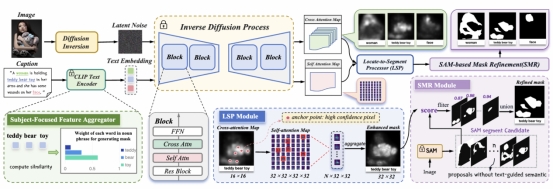
该论文第一作者是信息学院人工智能系2022级硕士生杨丹妮,通讯作者是孙晓帅教授,由2021级本科生董若含、博士后研究员纪家沂、2023级博士生马祎炜、2021级硕士生王昊为、纪荣嵘教授共同合作完成。
4. Multi-branch Collaborative Learning Network for 3D Visual Grounding
3D视觉定位任务(3D Visual Grounding)由3D指向性目标检测(3DREC)与3D指向性实例分割(3DRES)这两个子任务构成,两个子任务虽然最终表现形式不同,但是仍有着极大的关联和协同求解空间。现有的多任务协同方法主要依赖于一项任务的结果来对另一项任务进行预测,因而限制了两个任务之间的有效协作。因此,本文提出了双分支协同网络(MCLN),该网络包括 3DREC 和 3DRES 两个任务的独立分支;与此同时,本文还引入了相对超点聚合 (RSA) 模块和自适应软对齐 (ASA) 模块,来促进两个分支之间的相互协同。上述架构对两个分支的预测结果进行了精确的对齐,并将更多的注意力分配到关键位置。实验评估结果表明,本文所提出的方法在 3DREC 和 3DRES 任务上都取得了最先进的性能,其中,3DREC的Acc@0.5提高了 3.27%,3DRES的mIOU 提高了5.22%。
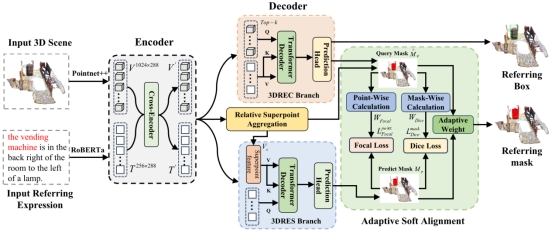
该论文的共同第一作者是人工智能研究院2022级硕士钱志鹏与信息学院人工智能系2023级博士马祎炜,通讯作者是孙晓帅教授,由2023级硕士生林哲恺、博士后研究员纪家沂、郑侠武副教授、纪荣嵘教授共同合作完成。
5. CamoTeacher: Dual-Rotation Consistency Learning for Semi-Supervised Camouflaged Object Detection
现有的伪装目标检测(COD)方法依赖于大规模的像素级标注。然而,由于其伪装特性,想要获取像素级的标注耗时耗力。半监督学习为解决这一问题提供了一种潜在的方案,但是直接将成功的半监督范式迁移到COD任务上,会导致伪标签存在过多噪声,直接用带噪声的伪标签进行监督会损害模型性能。针对这个问题,本文提出了一个半监督伪装目标检测模型CamoTeacher,并设计了一种新颖的学习方法——双旋转一致性学习(DRCL)。具体来说,DRCL包括像素一致性学习(PCL)和实例一致性学习(ICL)两种学习策略。PCL通过精细评估不同旋转视图下的像素级一致性,为伪标签中的各区域分配差异化权重,从而有效减少了像素级噪声的干扰;ICL通过计算不同旋转视图的实例级一致性,动态调整伪标签的整体权重,能有效地缓解实例级噪声问题。DRCL能帮助模型自适应调整不同质量伪标签的贡献,使模型获得充分监督的同时又避免确认偏差。本文在四个 COD 基准数据集上进行了广泛实验,实验结果充分验证了CamoTeacher的有效性。
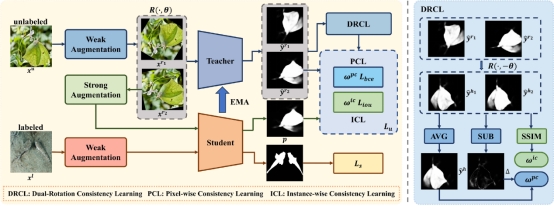
该论文的第一作者是信息学院人工智能系2022级硕士生赖训发,通讯作者是张声传助理教授,由2022级硕士生杨芷钰、曹刘娟教授,纪荣嵘教授等共同合作完成。
6. TF-FAS: Twofold-Element Fine-Grained Semantic Guidance for Generalizable Face Anti-Spoofing
泛化性人脸防伪(FAS)技术因其在未知场景中的鲁棒性备受关注。尽管一些最新方法引入了视觉-语言模型,但仅使用粗粒度或单一元素提示,未能充分发挥语言监督的潜力,导致泛化能力有限。为此,本文提出了TF-FAS框架,通过双重元素细粒度语义指导来增强泛化能力。本文设计了内容元素解耦模块(CEDM),用以全面探索与内容相关的语义元素,并监督类别特征与内容特征的解耦。此外,本文提出的细粒度类别元素模块(FCEM)用于探索和整合细粒度的类别元素指导,从而提升每类数据的分布建模能力。实验结果表明,TF-FAS在各项指标上均优于现有最先进方法,展示了其卓越的性能和广泛的应用前景。

该论文共同第一作者是信息学院人工智能系2022级硕士生王旭东和张克越(腾讯优图实验室),共同通讯作者是腾讯优图实验室丁守鸿(腾讯优图实验室)和戴平阳高级工程师,由姚太平(腾讯优图实验室)、周千寓(上海交通大学)、纪荣嵘教授共同完成。
7. Textual Grounding for Open-vocabulary Visual Information Extraction in Layout-Diversified Documents
现有的视觉文本信息抽取方法在封闭集视觉信息提取任务中取得了显著成功,而在开放词汇设置方面的探索相对不够深入。对于个人用户来说,后者在多种类型文档中推断信息方面更为实际。现有的解决方案,包括面向命名实体识别任务(NER)的方法和基于大语言模型(LLM)的方法,在处理无限范围的开放词汇key和缺少显式版式建模方面有所欠缺。本文提出将分类文本token的过程转变为基于给定query定位区域的任务的方法,来解决上述挑战。具体来说,本文将开放词汇键的语言嵌入与相应的局部文本视觉嵌入配对,并设计了一个适用于文档的grounding框架。该框架结合了版式感知上下文学习和适用于文档的两阶段预训练,显著提高了模型对文档的理解能力。
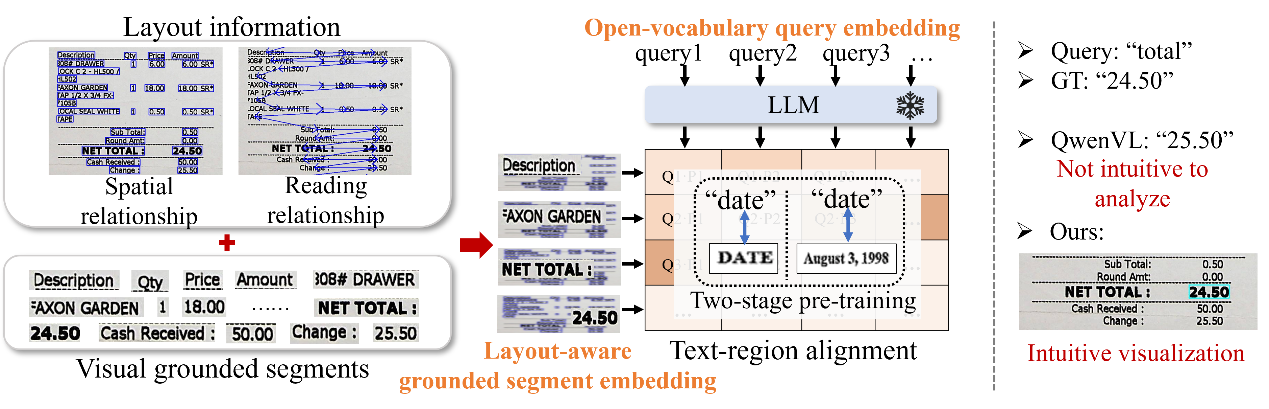
该论文第一作者是北京大学2020级博士生程梦钧,由陈杰副教授(北京大学)、刘畅(清华大学)、纪荣嵘教授、郑侠武副教授和百度视觉技术部共同合作完成。