近日,厦门大学媒体分析与计算实验室十二篇论文被人工智能领域的顶级会议AAAI 2024接收。简要介绍如下:
Learning Image Demoir‘eing from Unpaired Real Data
本文提出了一种弱监督图像去摩尔纹的方法(UnDeM)。与大量依赖于从成对的真实数据中学习的现有研究不同,该方法试图从未配对的真实数据(即与不相关的干净图像相关的莫尔图像)中学习去摩尔纹模型。首先将真实的摩尔纹图像划分为块,并根据其摩尔纹复杂度对其进行分组,接着引入了一种新的摩尔纹生成框架以合成具有不同摩尔纹特征的莫尔图像,生成的图像的伪摩尔纹类似于真实的摩尔纹,生成的图像的细节类似于真实无摩尔纹图像的细节。此外,本文还引入了一种自适应去噪方法来消除对模型学习产生不利影响的低质量伪摩尔纹图像。在常用的FHDMi和UHDM数据集上进行的实验结果表明,当使用现有的去摩尔纹模型(如MBCNN和ESDNet-L)时,本文提出的UnDeM方法性能更好。
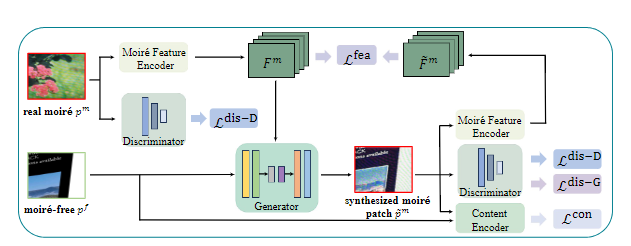
该论文第一作者是厦门大学人工智能研究院2021级博士生钟云山,通讯作者是纪荣嵘教授,由2022级硕士生周毓尧,2022级博士生张玉鑫,以及晁飞副教授共同合作完成。
Toward Open-set Human Object Interaction Detection
本文致力于开放领域的人体对象交互(HOI)检测任务。挑战在于识别全新的、超出领域的关系,而不是在领域内已经取得零样本HOI检测改进的关系。为了解决这一挑战,本文引入了一种简单的解耦HOI检测(DHD)模型,通过将开放集对象检测器与视觉语言模型(VLM)相结合,实现对新颖关系的检测。本文采用了一种解耦的图像-文本对比学习度量进行训练,并通过轻量级的单元和成对适配器将底层视觉特征连接到文本嵌入。本文的模型能够从开放集对象检测器和VLM中受益,以检测新的动作类别并将动作与新的对象类别相结合。此外,本文还提出了VG-HOI数据集,这是一个包含超过17,000个HOI关系的全面基准,适用于开放集场景。实验结果表明,本文的模型能够检测未知的动作类别并结合未知的对象类别。而且,它可以在仅在600个HOI类别上进行训练的情况下泛化到超过17,000个HOI类别。
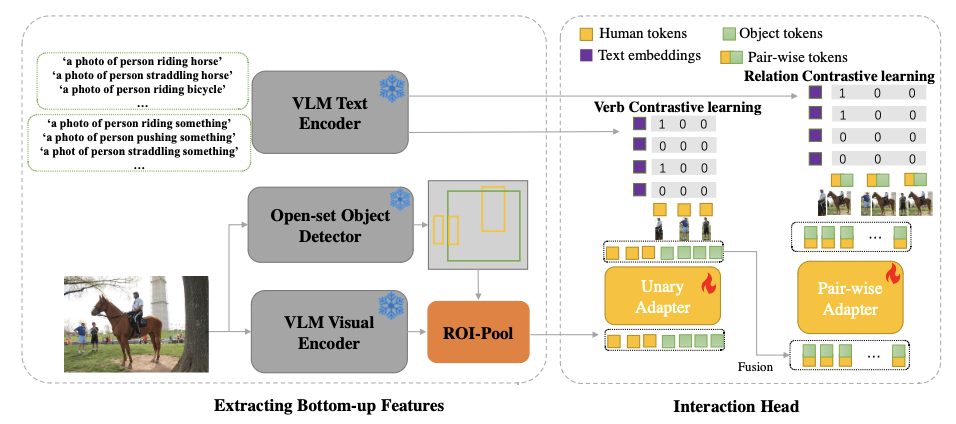
该论文共同第一作者是厦门大学人工智能研究院2023级博士生吴明瑞和2022级硕士生刘宇琪,通讯作者是博士后研究员纪家沂,由纪荣嵘教授、孙晓帅教授等共同合作完成。
Semi-Supervised Blind Image Quality Assessment through Knowledge Distillation and Incremental Learning
本文提出了一种用于无参考图像质量评估(BIQA)的半监督方法,旨在解决图像质量评估领域中标注数据稀缺和成本高昂的问题。我们引入了一个统一的框架称为SS-IQA,将半监督学习和增量学习相结合。具体来说,我们首先在有标签的数据集上训练一个高性能的教师模型,用来生成无标签数据的伪标签。我们引入了一个结合核岭回归的知识蒸馏模块,以从教师模型中提取高质量知识,进而提升伪标签的质量。此外,为了模拟多轮半监督学习过程,我们将无标签数据分批进行学习,但这可能引发灾难性遗忘问题。为此,我们采用了一种基于最小化差异的样本回放机制以缓解此问题。最后,我们在几个常用的BIQA数据集上(KADID、TID2013等)验证了本文方法的有效性。
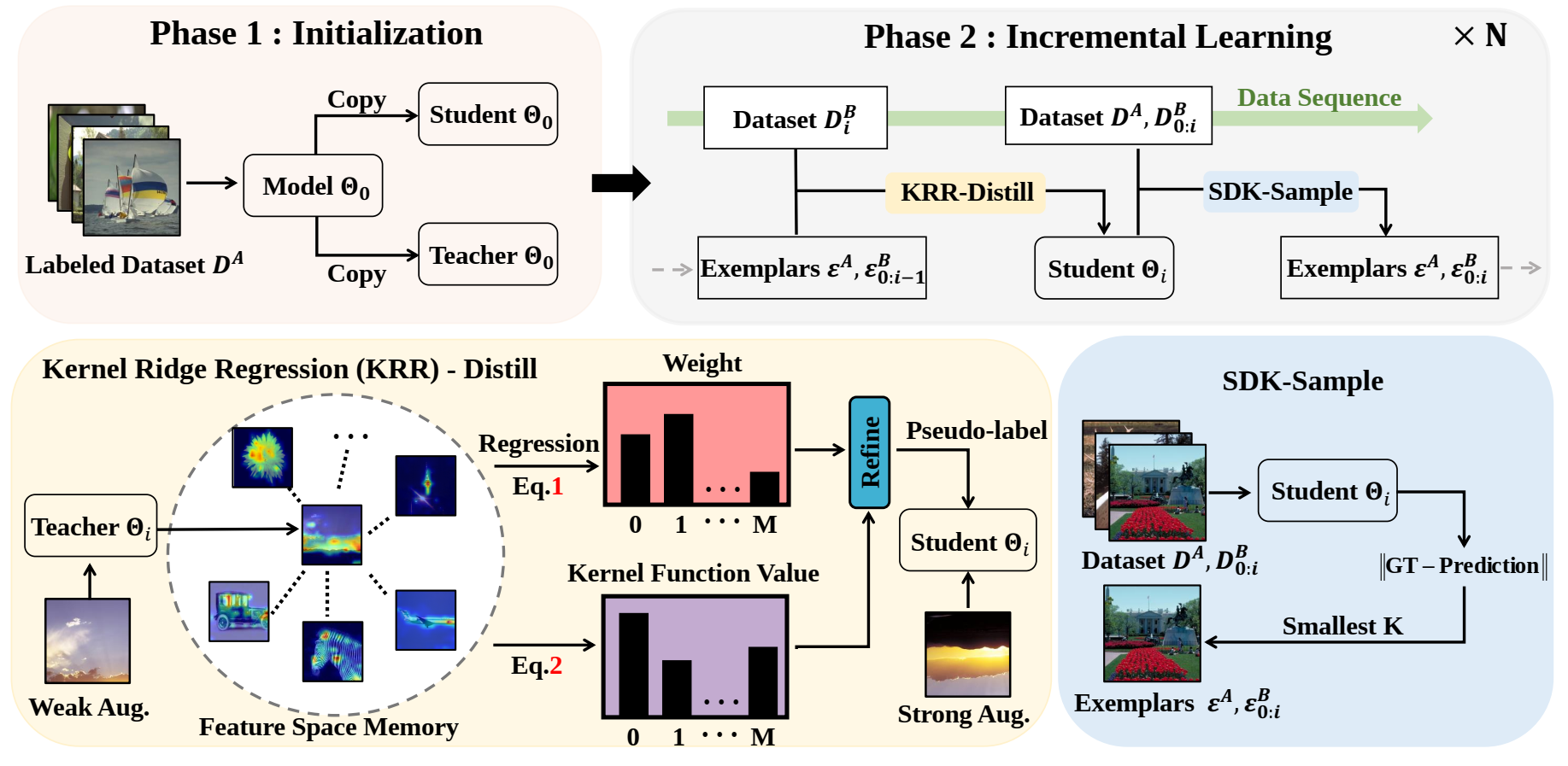
该论文共同第一作者是厦门大学信息学院人工智能系2022级硕士研究生潘文胜、高体民,通讯作者是张岩工程师, 由郑侠武副教授,戴平阳高级工程师等共同合作完成。
3D-STMN: Dependency-Driven Superpoint-Text Matching Network for End-to-End 3D Referring Expression Segmentation
本文提出了一种用于解决3D指向性分割任务 (3D-RES)的端到端超点文本匹配网络 (3D-STMN)。这是一种全新的单阶段范式,在性能和速度上都大幅优于之前的双阶段范式。为了解决双阶段范式受限于第一阶段分割不准确以及实例缺失的问题,本文引入了一种新的超点文本匹配机制,利用超点文本特征的聚合来获取目标实例的掩码。为了从文本角度增强语义解析,本文引入了一个基于依存树的依赖驱动交互模块,实现了令牌级交互。该模块利用来自依存语法树的先验信息来引导文本信息的流动。相关代码和数据已在https://github.com/sosppxo/3D-STMN上开源。
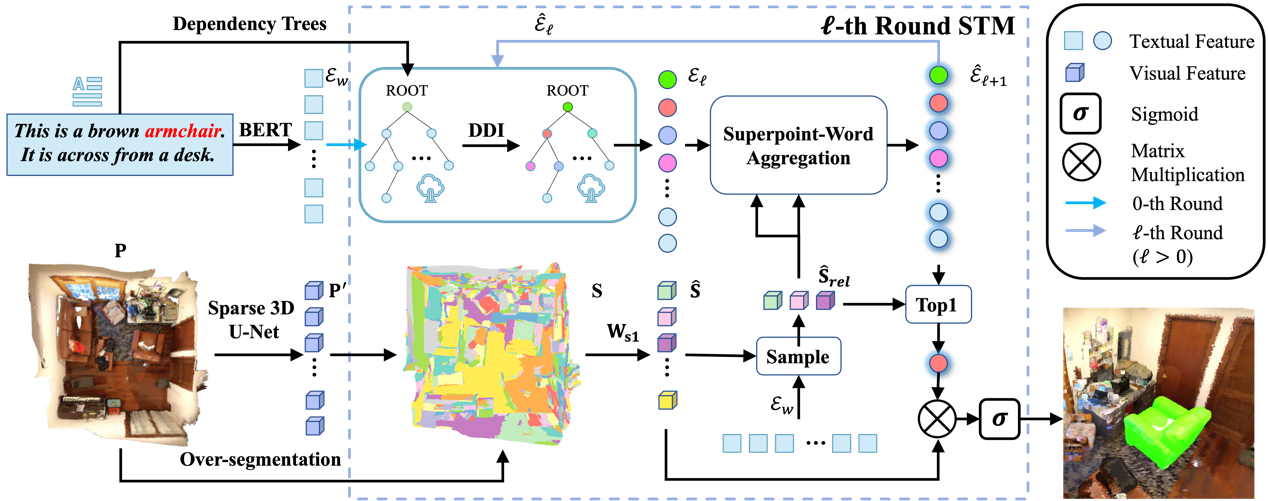
该论文的第一作者是厦门大学信息学院人工智能系2022级硕士生吴昌鲡,通讯作者是博士后研究员纪家沂,由孙晓帅教授、2023级博士生马祎炜、2023级硕士生陈琦、2021级硕士生王昊为和2021级博士生罗根共同合作完成。
Improving Panoptic Narrative Grounding by Harnessing Semantic Relationships and Visual Confirmation
本文为全景叙事分割任务提出了一种名为XPNG的模型,用于解决此前模型缺乏实例之间语义关系建模的问题。XPNG首先提出语义上下文卷积模块(SCC),利用文本模态作为语义先验信息来构建短语之间的内部关系,从而提升短语表征的区分性和指向性。此外,XPNG还设计了视觉上下文验证模块(VCV)来构建实例之间的几何关系,以此消除来自文本的先验语义偏差并进一步细化特征。实验结果表明,XPNG在PNG数据集上取得了最先进的性能。
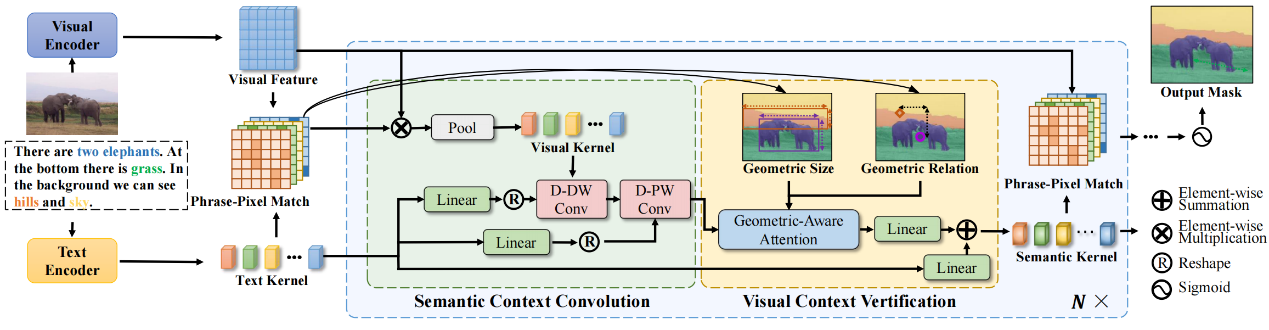
该论文共同第一作者是厦门大学信息学院人工智能系2022级硕士生郭天宇和2021级硕士生王昊为,通讯作者是博士后研究员纪家沂,由孙晓帅教授、2023级博士生马祎炜等共同合作完成。
Towards Efficient Diffusion-based Image Editing with Instant Attention Masks
本文提出了一种用于文本到图像(Text to Image, T2I)扩散模型的免训练、即插即用图像编辑方法,称为即时扩散编辑(InstDiffEdit)。该方法旨在解决扩散模型在利用掩码进行局部编辑任务时的效率低、精度差的问题。具体来说,InstDiffEdit 利用现有扩散模型的跨模式注意能力,在扩散步骤中实现即时的掩模引导。此外,本文还为 InstDiffEdit 配备了免训练的解决方案,通过自适应地聚合注意力分布,实现自动且准确的即时掩模生成。最后,为了充实基于扩散的图像编辑(DIE)评估体系,本文提出了一个名为Editing-Mask的新基准来度量现有编辑方法的掩模准确性和局部编辑能力。在ImageNet和Image数据集上的实验结果验证了本文方法在效率以及精度上的有效性。
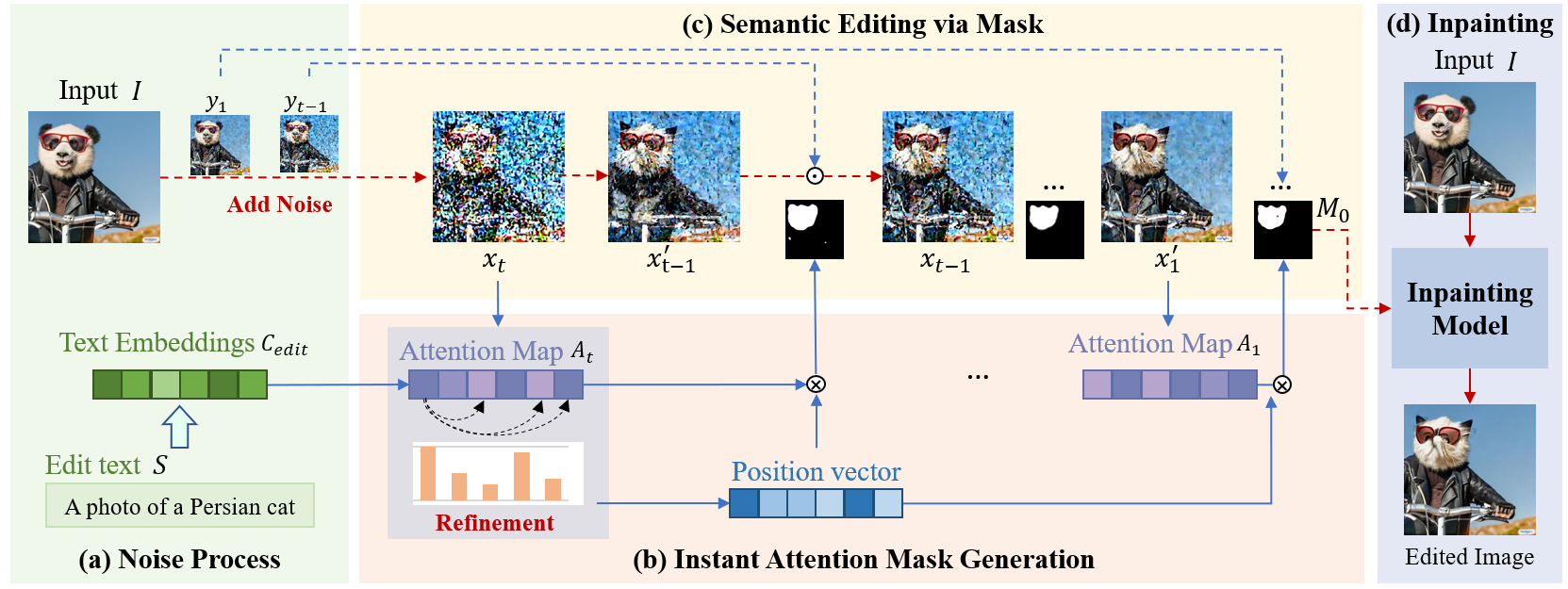
该论文第一作者是厦门大学信息学院人工智能系2021级硕士生邹思雨,通讯作者是孙晓帅教授,由周奕毅副教授、唐霁霁(网易伏羲)、张荣升(网易伏羲)等合作完成。
X-RefSeg3D: Enhancing Referring 3D Instance Segmentation via Structured Cross-Modal Graph Neural Networks
文本引导的3D实例分割是一项具有挑战性的任务,其目标是根据给定的文本描述准确地分割3D场景中的目标实例。本文提出了一种名为X-RefSeg3D的全新模型。具体而言,本文的方法首先捕捉待分割对象特定的文本特征,然后将其与实例特征融合,构建一个跨模态的场景图。随后将获得的跨模态特征整合到图神经网络中,利用KNN算法从场景的文本描述和空间关系中获取信息,从而捕获实例之间的高阶关系,以增强特征的有效融合,并保障模型的准确推理。最后,基于直接预测得分与相似度计算得分,将改进后的特征输入匹配模块进行最终匹配分数的计算。在Scanrefer数据集上的实验结果证明了X-RefSeg3D方法的有效性,在mIOU方面超过了以往SOTA方法3.67%。
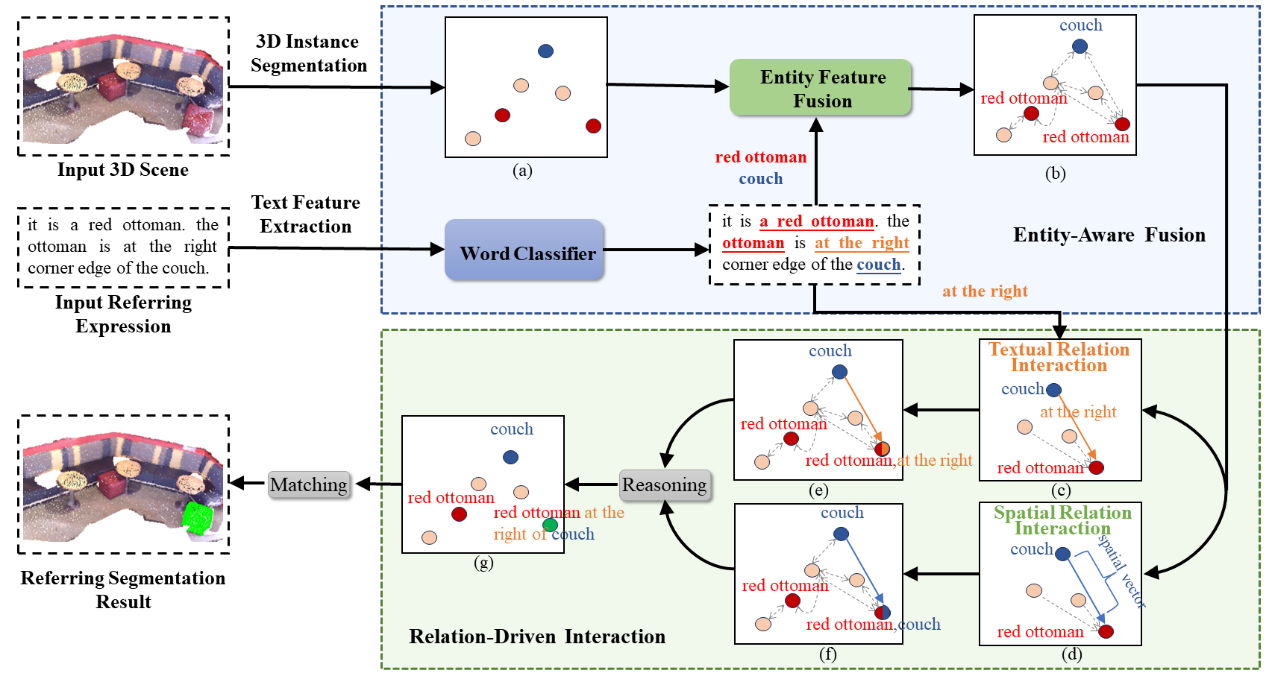
该论文第一作者是厦门大学人工智能研究院2022级硕士生钱志鹏,通讯作者是孙晓帅教授,由厦门大学信息学院人工智能系2023级博士生马祎炜、纪家沂博士后研究员共同合作完成。
CamoDiffusion: Camouflaged Object Detection via Conditional Diffusion Models
本文提出了一种基于扩散模型的伪装目标检测方法(CamoDiffusion)。该方法解决了伪装目标检测中伪装对象边界混淆和过度自信的错误预测问题。首先,从标准正态分布中采样的噪声图像被用作初始分割预测。然后,通过提出的自适应Transformer条件网络动态提取图像特征,并结合多尺度机制将粗粒度到细粒度的特征进行全面融合,得到伪装图像特征。接下来,去噪网络结合所提取的特征,从初始噪声掩膜开始,结合多尺度特征和时间步,输出细化后的分割图像。去噪扩散模型的训练使用了交并比损失和二元交叉熵损失。在测试阶段,通过重复去噪操作,得到一个精细的特征图。此外,本研究还设计了一种新的加噪策略(对轮廓进行破坏),引入了结构级别的噪声,并提出了新的融合策略,以有效利用不同时间步的预测结果。实验结果表明,与其他伪装目标检测模型相比,本文的模型取得了更好的效果。
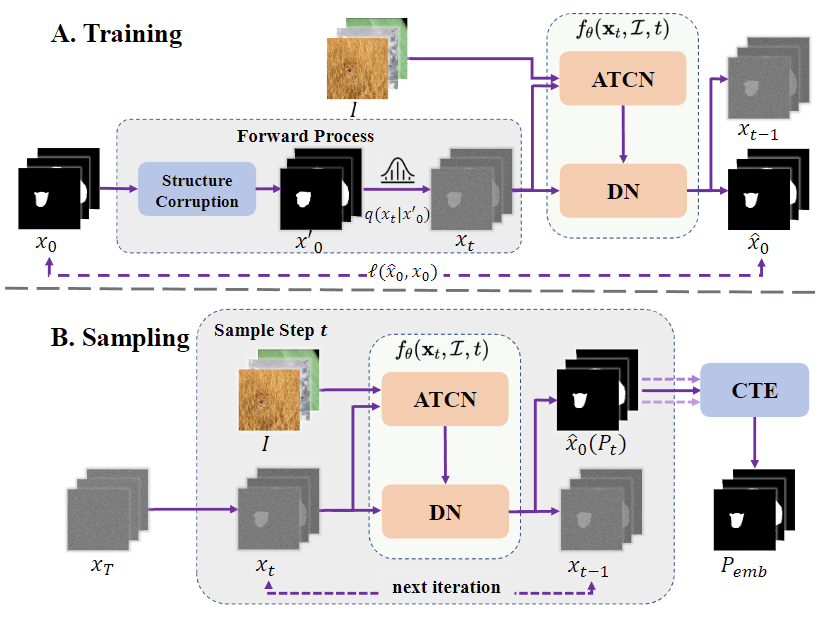
该论文第一作者是厦门大学人工智能研究院2022级硕士生陈忠淅,通讯作者是林贤明助理教授。
Hypergraph Neural Architecture Search
近年来,超图神经网络在处理非欧数据中引起了广泛的关注。然而,现有超图神经网络需要研究人员手动调整各种复杂的模型参数,耗费了大量人力和计算资源。为了解决这个问题,本文提出一种超图神经架构搜索方法,能够自动化整个超图神经网络的构建过程。具体来说,定义了一个适用于超图神经网络的搜索空间,然后采用可微的神经架构搜索策略自动寻找适合下游学习任务的超图神经网络架构。在引文网络数据集和超图数据集上的实验表明本文模型优于现有的超图神经网络模型。
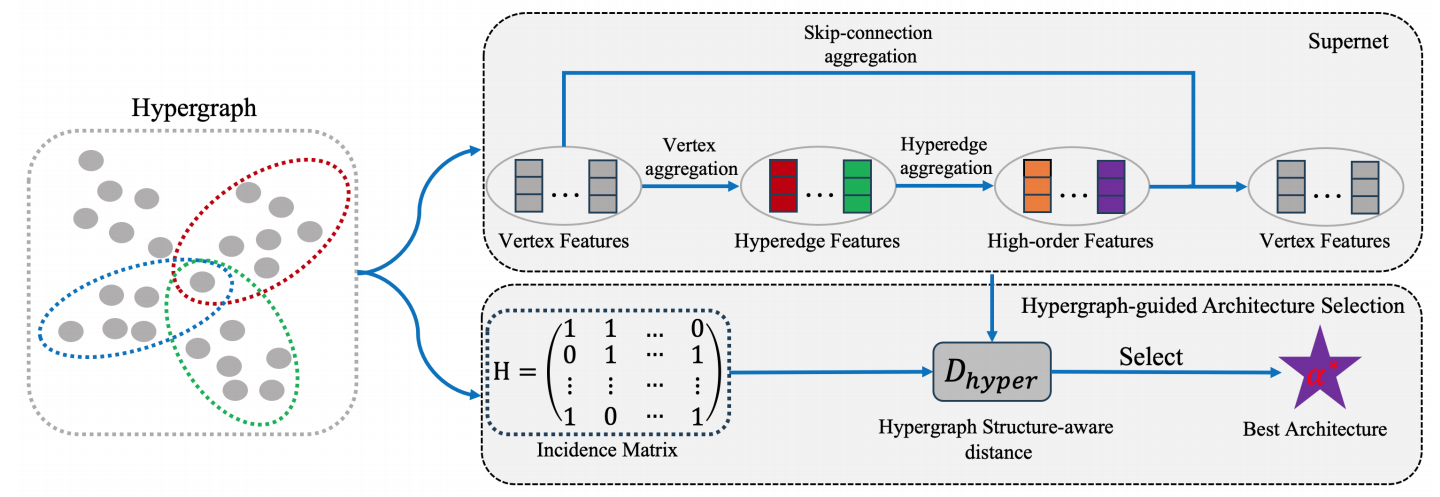
该论文第一作者是厦门大学计算机系2021级硕士生林威,通讯作者是金泰松副教授,由2021级硕士彭旭等共同合作完成。
Occluded Person Re-Identification via Saliency-Guided Patch Transfer
对于遮挡行人重识别问题,当前常用的数据驱动的增强方式主要遵循随机擦除模式,这些策略通常使用随机生成的噪声来取代随机选择的图像区域来模拟障碍物。然而,随机策略对位置和内容不敏感,这意味着它们无法在应用场景中模拟真实世界的遮挡情况。为了克服这一限制,充分利用数据集中的真实场景信息,本文提出了一种更直观、更有效的数据驱动策略,称为Saliency-Guided Patch Transfer (SPT)。结合ViT,SPT使用显著性块选择模块来划分人物实例和背景障碍。通过将前景人物实例转移到不同的背景遮挡物图像中,SPT可以轻松生成逼真的遮挡样本。此外,我们提出了一种遮挡感知交并比(Occluded-Aware IoU),并通过结合掩码滚动策略来获得更合适的组合,以及一种类忽略策略来实现更稳定的处理过程。对被遮挡和整体人物重识别任务进行的广泛实验评估表明,在基于ViT的不同ReID算法中,SPT在遮挡行人重识别问题上提供了显著的性能增益。
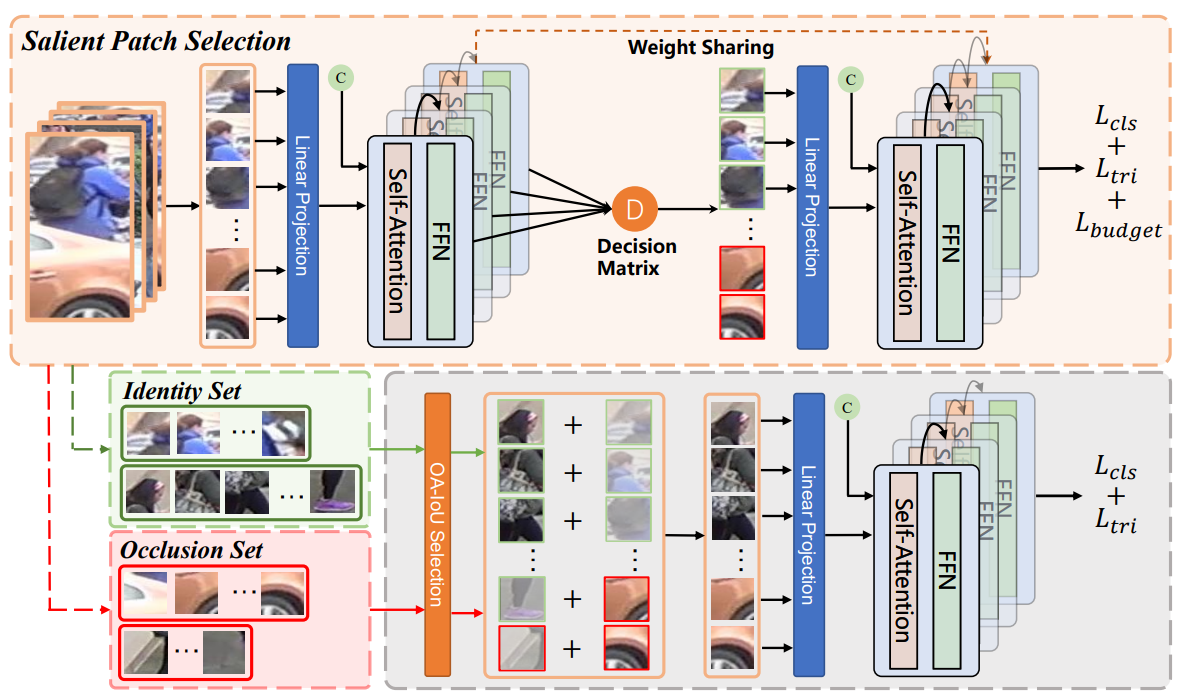
该论文的第一作者是厦门大学信息学院人工智能系2020级博士生谭磊,通讯作者是曹刘娟教授,由2021级硕士生夏佳尔、2020级硕士生刘文锋、戴平阳高级工程师、吴永坚(腾讯优图)合作完成。
Attention Disturbance and Dual-Path Constraint Network for Occluded Person Re-Identification
本文提出了一种新的数据增强方法(ADM),尝试改善遮挡行人重识别任务中缺少有效遮挡数据的问题。该方法根据注意力热图,动态的学习了一个能够干扰注意
力分布的噪声掩码,使得人工遮挡数据能够更贴近实际的遮挡数据,解决了以往人工遮挡与真实遮挡分布差异过大的问题。同时,本文提出了一个新的约束损失(DPC),使得网络能够更好地利用生成的困难遮挡数据进行学习,有效规避遮挡。
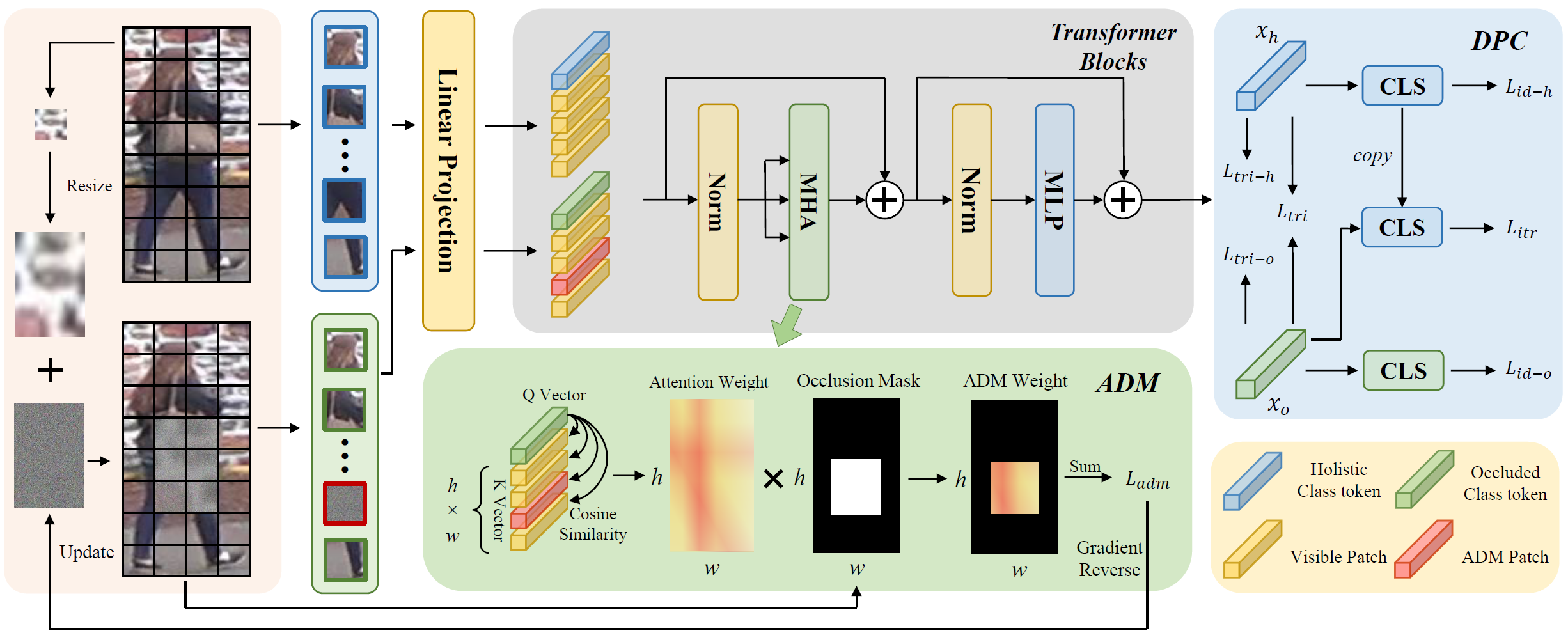
该论文的第一作者是厦门大学信息学院人工智能系2021级硕士生夏佳尔,通讯作者是戴平阳高级工程师,由2020级博士生谭磊、吴永坚(腾讯优图)、曹刘娟教授等共同合作完成。
Weakly Supervised Open-Vocabulary Object Detection
本文提出了一种新型的弱监督开放词汇目标检测框架WSOVOD,利用仅包含图像级注释的多样化数据集来扩展传统的弱监督目标检测框架(WSOD)来检测新颖目标。本文探索了三种关键策略,包括数据特征适应、图像显著目标定位和区域视觉语言对齐。首先,进行数据感知特征提取,生成输入条件系数,该系数被利用到组合数据集属性原型中以识别数据集偏差并帮助实现跨数据集泛化。其次,提出了一个自定义的位置导向弱监督区域提议网络,利用类别无关的分割模型的语义布局来区分对象边界。最后,引入了一个提案概念同步的多实例网络,即对象挖掘和视觉语义对齐的细化,以发现与概念的文本嵌入匹配的对象。在Pascal VOC和MS COCO上的大量实验表明,与先前的WSOD方法相比,WSOVOD在封闭集对象定位和检测任务中实现了新的最先进性能。同时,WSOVOD实现了跨数据集和开放词汇表学习以实现与全监督SOTA开放词汇表对象检测(FSOVOD)相当或更好的性能。
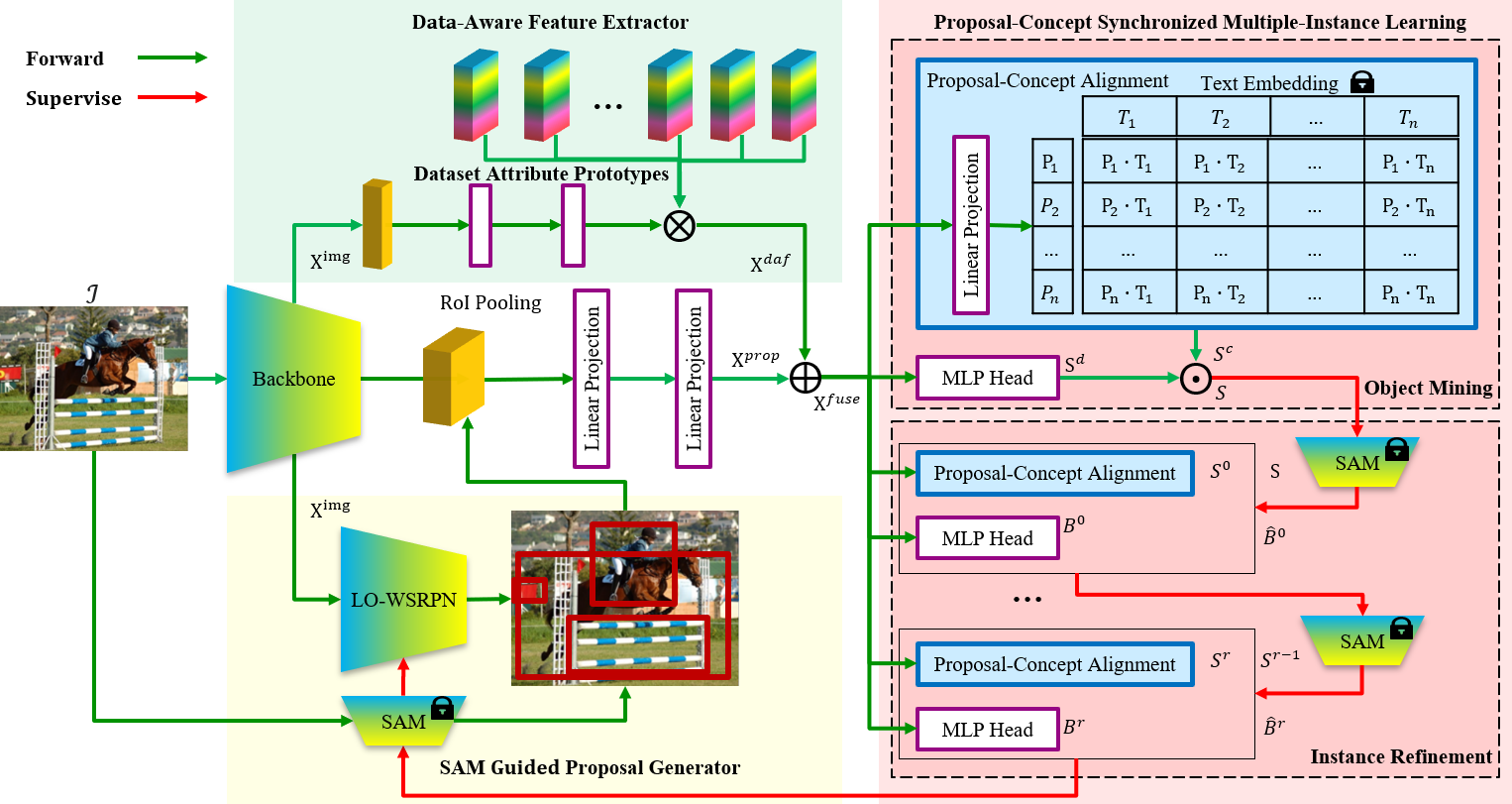
该论文第一作者是厦门大学信息学院计算机系2023级博士研究生林将航,通讯作者是曹刘娟教授,由沈云航(腾讯优图)、2021级硕士生王秉权等共同合作完成。