近日,厦门大学媒体分析与计算实验室三篇论文被人工智能领域的顶级会议NeurIPS 2023接收。简要介绍如下:
1. Parameter and Computation Efficient Transfer Learning for Vision-Language Pre-trained Models
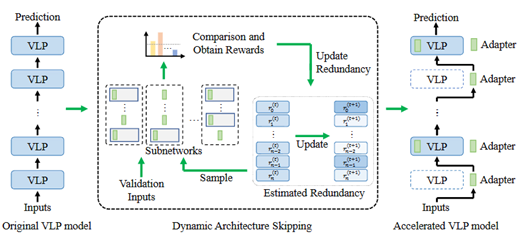
近年来,视觉语言预训练(VLP)模型的规模和计算量不断增加,导致将这些模型迁移到下游任务时的开销也越来越大。最近的研究重点关注了VLP模型参数高效迁移学习(PETL),该方法仅需更新少量参数即可实现模型任务迁移。然而,仍然存在大量的计算开销困扰着VLP的应用。因此,本文致力于研究VLP模型参数和计算的高效迁移学习(PCETL)。需要特别注意的是,PCETL不仅要限制VLP模型中可训练参数的数量,还注重减少推理过程中的计算冗余,以实现更高效的传输。为了实现这一目标,我们提出了一种新的动态架构跳过(DAS)方法。DAS不是直接优化VLP模型的内在架构,而是通过基于强化学习(RL)的过程观察模块对下游任务的重要性,然后使用轻量级网络跳过冗余模块。这样一来,VLP模型的迁移过程能够有效地将可训练参数保持在较低水平,同时加快对下游任务的推理速度。
该论文第一作者是厦门大学人工智能研究院2022级博士生吴穹,通讯作者是纪荣嵘教授,由2022级硕士生余薇、周奕毅副教授,2021级硕士生黄书滨等共同合作完成。
2. Improving Adversarial Robustness via Information Bottleneck Distillation
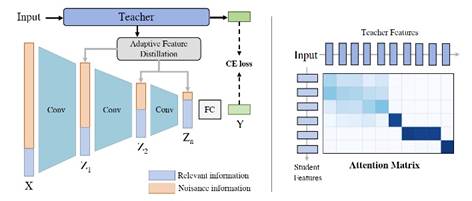
本文提出了信息瓶颈蒸馏(IBD)方法。提出了两种蒸馏策略来分别匹配信息瓶颈的两个优化过程。IBD首先利用鲁棒的软标签蒸馏来最大化潜在特征和输出预测之间的互信息。其次,本文进一步提出了一种自适应特征蒸馏,可以自动将相关知识从教师模型转移到目标模型,从而可以限制输入特征和潜在特征之间的互信息。本文方法在各种基准数据集进行了广泛的实验,实验结果证明了所提出的方法可以显著提高模型的对抗鲁棒性。
该论文的第一作者是厦门大学信息学院人工智能系2020级博士生匡华峰,通讯作者是纪荣嵘教授,由刘宏博士(日本国立信息研究所)、Shin’ichi Satoh教授(日本国立信息研究所)、吴永坚(腾讯优图)等共同合作完成。
3. Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
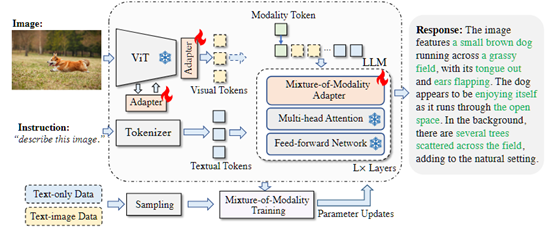
本文提出了一种新颖且经济实惠的解决方案,用于有效地将 LLMs 适应到 VL(视觉语言)任务中,称为 MMA。MMA 不使用大型神经网络来连接图像编码器和 LLM,而是采用轻量级模块,即适配器,来弥合 LLMs 和 VL 任务之间的差距,同时也实现了图像模型和语言模型的联合优化。同时,MMA 还配备了一种路由算法,可以帮助 LLM 在不损害其自然语言理解能力的情况下,在单模态和多模态指令之间实现自动切换。
该论文的第一作者是厦门大学信息学院人工智能系2021级博士生罗根,通讯作者是纪荣嵘教授,由周奕毅副教授、孙晓帅副教授和2022级硕士生陈晟新等共同合作完成。