近日,厦门大学多媒体分析与计算实验室在多媒体领域顶级会议ACM Multimedia 2023上录用6篇论文。实验室接收论文简要介绍如下:
1. Beat: Bi-directional One-to-Many Embedding Alignment for Text-based Person Retrieval
本文为基于文本的行人检索任务提出了一种名为BEAT的双向一对多映射模型,用于解决传统单向映射范式优化不稳定的问题和一对一映射范式忽略图文一对多关系的问题。BEAT首先使用预训练的视觉和文本编码器提取相应的视觉和文本特征,然后使用所提出的残差映射模块组(REM-G)将视觉和文本特征在文本和视觉空间中进行双向一对多的映射。最后,在文本和视觉空间中同时利用损失函数对特征进行优化。实验结果表明,BEAT在CUHK-PEDES、ICFG-PEDES和RSTPReID数据集上均取得了优异的性能,证明了双向一对多映射范式的有效性。
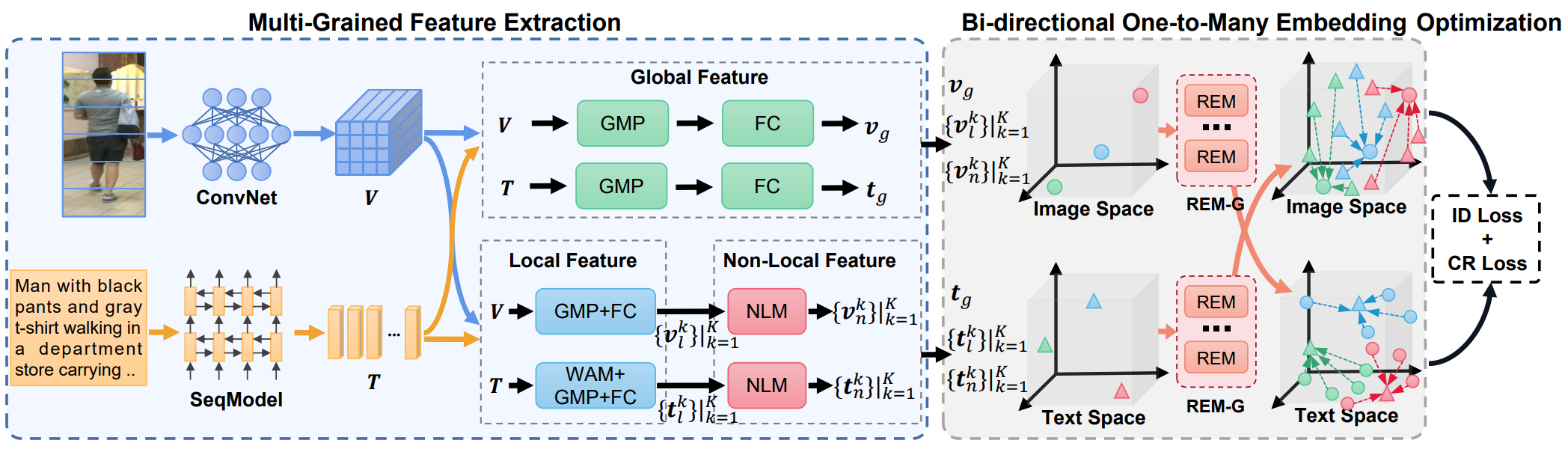
该论文的第一作者是厦门大学信息学院人工智能系2020级硕士生马祎炜,通讯作者是孙晓帅副教授,由纪家沂博士后、江冠南博士(宁德时代)、纪荣嵘教授等共同合作完成。
2. PixelFace+: Towards Controllable Face Generation and Manipulation with Text Descriptions and Segmentation Masks
本文提出了一种名为PixelFace+的新型跨模态像素合成网络。通过结合文本描述和分割图,PixelFace+可实现高质量的人脸生成,同时在保留人物面部信息的基础上,支持通过修改输入的文本描述或分割图进行交互式的面部编辑。PixelFace+利用了CLIP的预训练语言编码器来提取输入文本描述的语义信息。基于此,本文提出了门控跨模态注意模块(GCMF),将得到的词嵌入转换为文本先验张量。在视觉信息方面,先通过浅卷积层从输入的分割图中提取视觉先验特征,再将这些文本和视觉先验输入到生成器中以生成最终的面部图像。PixcelFace+在训练过程中使用对抗损失函数,通过学习文本、分割图和生成图像之间的三元组一致性来确保生成的可控性。此外,本文还设计了基于CLIP的正则化损失来对齐视觉语言特征。经过训练,PixelFace+能够通过单个或双重条件输入来实现高度可控的面部生成和操作。为验证PixelFace+的有效性,本文在MultiModal CelebA-HQ数据集上进行了广泛的实验。结果表明,与传统的文本引导人脸生成和编辑方法相比,本文所提出的PixelFace+在图像质量和图文匹配方面具有更好的性能。
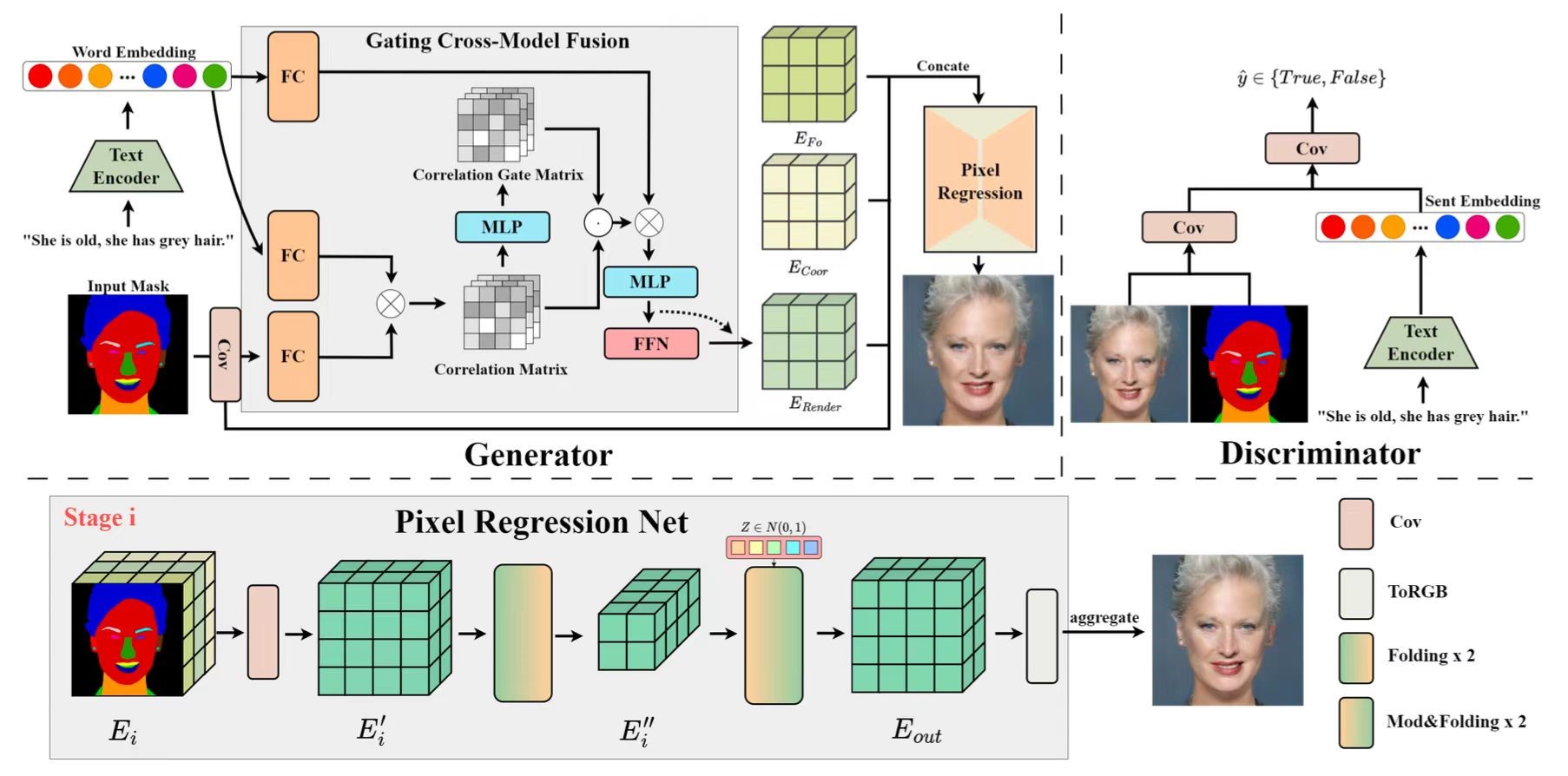
该论文共同第一作者是厦门大学信息学院人工智能系2021级硕士生杜晓雄和2019级博士生彭军,通讯作者是孙晓帅副教授,由周奕毅副教授,硕士生张金璐、硕士生陈思亭、江冠南博士(宁德时代),纪荣嵘教授共同合作完成。
3. Beyond First Impressions: Integrating Joint Multi-modal Cues for Comprehensive 3D Representation
本文横跨3D、文本和图像多个模态,旨在构建3D到自然语言的表征学习与训练框架。近年来,3D表示学习已逐步引入2D视觉-语言预训练模型,以克服数据稀缺的挑战。然而,现有方法仅仅是将2D对齐策略简单地转移到3D表示上,导致了信息退化和协同不足的瓶颈。本文提出了一种名为JM3D的多视角联合模态建模框架,以获得3D点云、文本和图像的统一表示。在数据组织上,本文提出了一种新颖的结构化多模态组织器(SMO),引入了连续随机采样多视角图像和层次化文本以丰富视觉和语言模态的表示,进而解决信息退化问题。同时,本文设计了一种联合多模态对齐(JMA)来解决协同上的不足,并给出了相关的理论推导和原理解释,实现了点云-图片-文本多模态的统一表征。相关代码和数据已在https://github.com/Mr-Neko/JM3D开源。
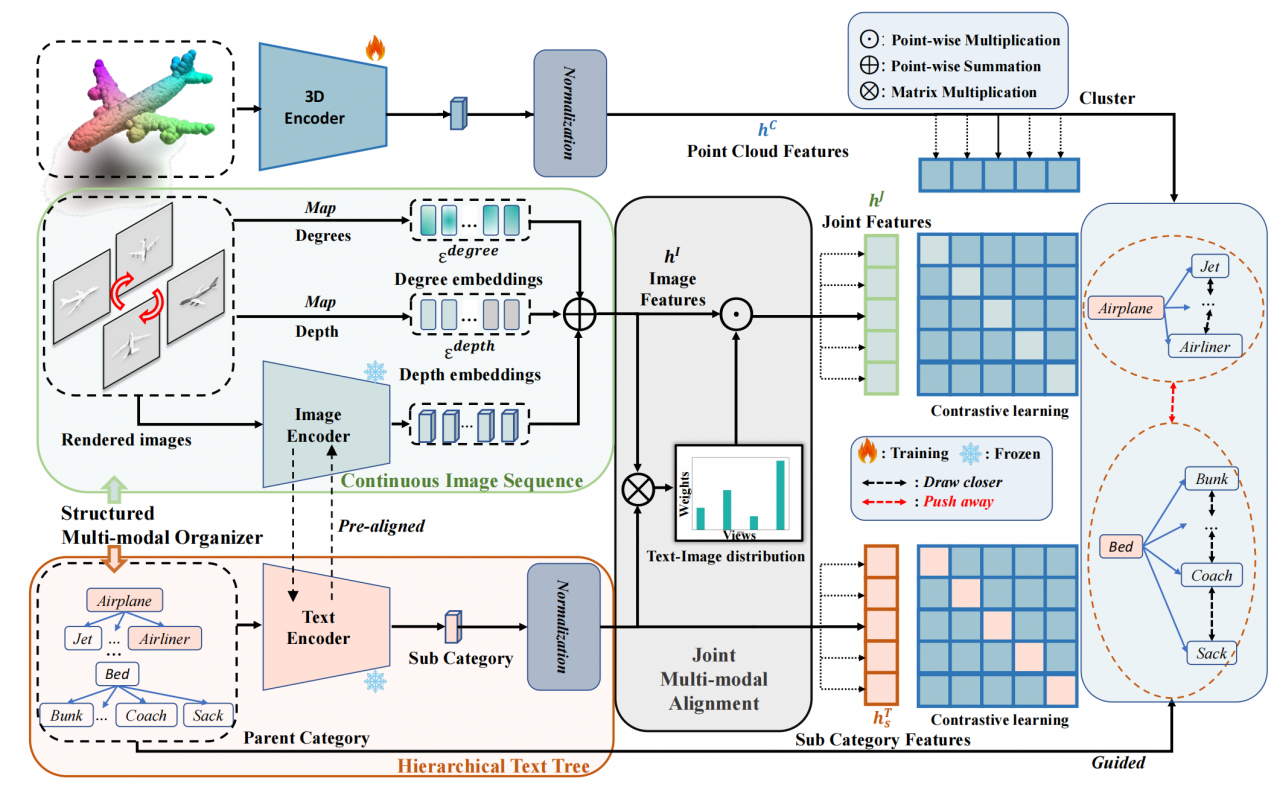
该论文共同第一作者是厦门大学信息学院人工智能系2021级硕士生王昊为和博士后研究员纪家沂,通讯作者是孙晓帅副教授,由唐霁霁(网易伏羲)、张荣升(网易伏羲)、纪荣嵘教授等合作完成。
4.Semi-Supervised Panoptic Narrative Grounding
全景叙事定位(PNG)任务需要相对昂贵的像素级标注,这限制了该任务的推广落地。本文提出一个新的任务设定——半监督全景叙事分割(SS-PNG),只需少量的图文对和分割标注,即可完成高效的PNG模型训练,减小了对标注数据的依赖。具体而言,本文采用教师-学生网络架构搭建了SS-PNG-NW网络,探索了Burn-In策略和各种数据增强技术来确定最优设置。针对训练过程中不同样本的伪标签质量存在差异的问题,本文进一步提出了基于伪标签质量的损失函数调整方法,并基于此构建了SS-PNG-NW+网络,以更好地让高质量伪标签指导学生模型学习。基于PNG数据集的各类消融实验验证了所提出方法的有效性。在仅使用30%的标签数据时,所提出的半监督网络甚至可超过全监督模型。
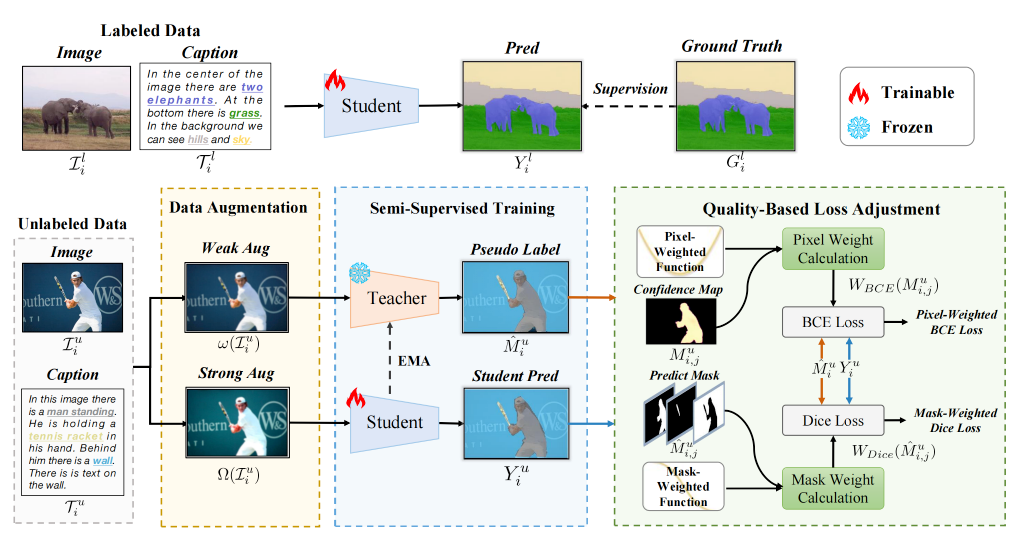
该论文第一作者是厦门大学信息学院人工智能系2022级硕士生杨丹妮,通讯作者是博士后研究员纪家沂博士,由2021级硕士生王昊为、2020级硕士生李毅男、2020级硕士生马祎炜,以及孙晓帅副教授和纪荣嵘教授合作完成。
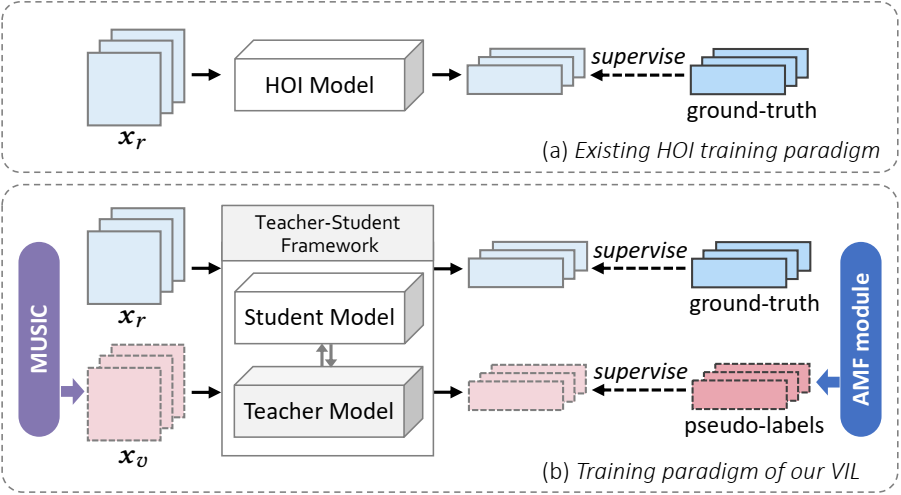
5. Improving Human-Object Interaction Detection via Virtual Image Learning
人-物交互(HOI)检测旨在定位图像中具有交互性的人与物体,并识别两者间的交互关系。HOI的性能受限于严重的长尾问题,为缓解长尾问题,本文提出了模型无关的增益方法——VIL(Virtual Image Learning)。首先,本文设计了名为MUSIC的数据生成法,通过向朴素文本提示添加特定描述生成图像,并采用多环节过滤过程,构造与真实数据集同分布的虚拟数据集。之后,训练时引入教师-学生网络框架。为提升伪标签的质量,本文提出了AMF模块,自适应地对伪标签进行匹配与筛选。最后,本文在HOI常用的两大数据集上与多个现有方法结合,性能的提升证明了本文方法的有效性。
该论文第一作者是厦门大学信息学院人工智能系2020级硕士研究生方姝曼,通讯作者是林贤明助理教授,由2022级硕士研究生刘帅、2019级博士研究生李杰,以及江冠南博士(宁德时代)和纪荣嵘教授合作完成。
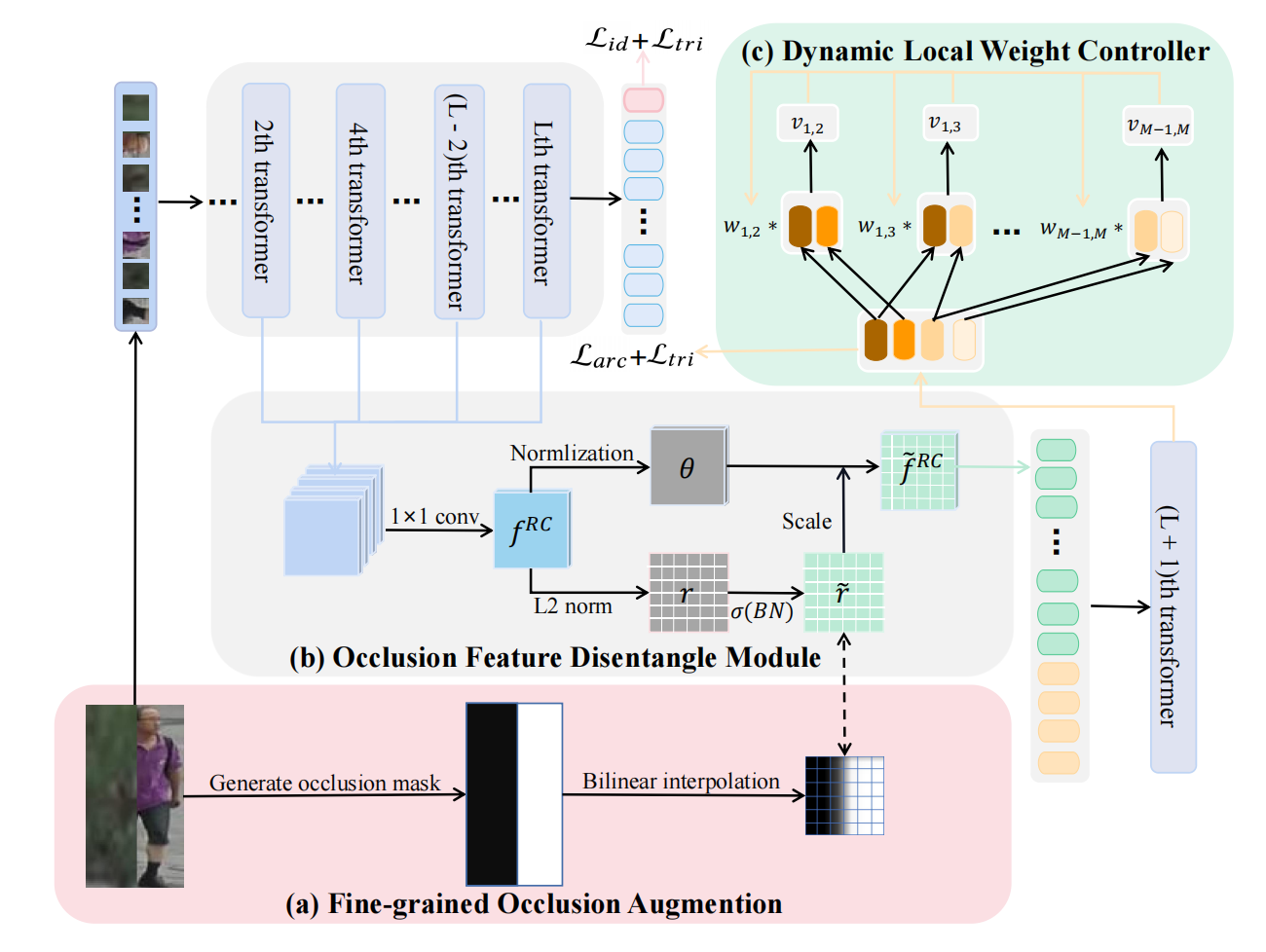
6. Learning Occlusion Disentanglement with Fine-grained Localization for Occluded Person Re-identification
该论文面向行人重识别任务,提出了一个细粒度遮挡解耦网络(Fine-grained Occlusion Disentangled Network,简称为 FODN)。FODN 方法提出了三个组件来改善在遮挡情况下现有方法的不足,分别是精细化遮挡数据增强,遮挡特征解耦模块,动态局部权重控制器。这些组件使得 Transformer 网络能够更精确地去除遮挡的影响,并更好地关注多样性的局部特征。精细化遮挡数据增强方案通过双线性插值产生相应的精细化局部标签,指示行人的哪些具体区域被遮挡。遮挡特征解耦模块,通过解耦范数和角度分别用于遮挡感知和行人重识别任务,缓解了遮挡感知和行人重识别任务的冲突。动态局部权重控制器能够在训练过程中对各个局部token的学习权重进行动态调整,以平衡各个人体部位之间的相对重要性。在该任务的常用公开数据集Occluded-Duke、Occluded-REID等的实验结果充分验证了本文方法的有效性。
该论文第一作者是厦门大学信息学院人工智能系2020级硕士生刘文锋,通讯作者是戴平阳高级工程师,由张岩工程师、纪荣嵘教授、吴永坚(腾讯优图)等共同合作完成。