近日,人工智能领域计算机视觉方向的国际顶级学术会议International Conference on Computer Vision(ICCV)官方发布了接受论文列表,厦门大学媒体分析与计算实验室共有八篇论文被录用。
ICCV ( IEEE International Conference on Computer Vision),即国际计算机视觉大会,由IEEE主办,与计算机视觉模式识别会议(CVPR)和欧洲计算机视觉会议(ECCV)并称计算机视觉方向的三大顶级会议,被澳大利亚ICT学术会议排名和中国计算机学会等机构评为最高级别学术会议,在业内具有极高的评价。不同于在美国每年召开一次的CVPR和只在欧洲召开的ECCV,ICCV在世界范围内每两年召开一次。ICCV论文录用率非常低,是三大会议中公认级别最高的会议。
实验室接收论文简要介绍如下:
1. Category-aware Allocation Transformer for Weakly Supervised Object Localization
弱监督目标定位(WSOL)旨在实现仅给定图像级标签的前提下学习一个目标定位器。最近,基于自注意力机制和多层感知器结构的transformer因其可以捕获长距离特征依赖而在WSOL中崭露头角。美中不足的是,transformer类的方法使用类别不可知的注意力图来预测边界框,从而容易导致混乱和嘈杂的目标定位。本文提出了一个基于transformer的新颖框架——CATR(类别感知Transformer),来在transformer中学习特定目标的类别感知表示,并为目标定位生成相应的类别感知注意力映射。具体地,我们提出了一个类别感知模块来诱导自注意力图的可学习类别偏差,提供辅助监督来指导学习更有效的特征表示。此外,本文还设计了一个目标约束模块,以自我监督的方式细化类别感知注意力图的目标区域。最后,在两大公开数据集CUB-200-2011和ILSVRC上进行了充分的实验来验证本文方法的有效性。
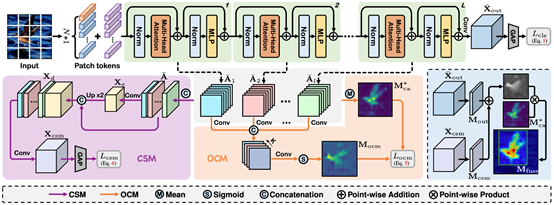
该论文由厦门大学信息学院人工智能系2020级博士生陈志威与曹刘娟教授(通讯作者)、沈云航(优图实验室)、张声传助理教授、纪荣嵘教授等合作完成。
2. Pseudo-label Alignment for Semi-supervised Instance Segmentation
该论文面向半监督实例分割任务,针对现有方法的一个局限性,即伪标签的类别和掩模质量的不匹配问题,提出了一种新颖的框架,称为PAIS。在PAIS中,我们设计了一种动态对齐损失函数(DALoss),它可以调整具有不同类别和掩模分数对的半监督损失函数项的权重,以此来缓解不匹配的问题。通过在COCO 和 Cityscapes 数据集上进行的广泛实验,我们证明 PAIS 是半监督实例分割的一个有效的框架,特别是在标记数据严重有限的情况下。
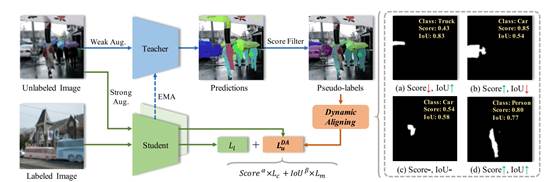
该论文由厦门大学信息学院2019级博士生胡杰、2021级硕士生陈晨(共同一作)与其导师曹刘娟教授(通讯作者)、张声传助理教授、宁德时代束岸楠、宁德时代江冠南、纪荣嵘教授合作完成。
3.InterFormer: Real-time Interactive Image Segmentation
该论文提出了一种高效的图像交互分割方法,称为InterFormer,用于解决现行交互分割流程中存在的模型低并行处理以及计算冗余问题。InterFormer先利用Vision Transformer在高性能设备上并行预处理图像,后基于预处理后的图像特征以及所提出的交互多头自注意力模块(I-MSA)可在低性能的端设备上进行实时的交互分割。经过多个数据集上的实验验证,InterFormer在计算效率和分割质量上均表现卓越,甚至在只使用CPU的设备上,也能实现实时的高质量交互分割。
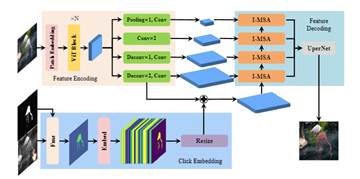
该论文由厦门大学信息学院人工智能系2022级博士生黄有与张声传助理教授(通讯作者),曹刘娟教授,纪荣嵘教授,宁德时代江冠南博士等共同合作完成。
4.X-Mesh: Towards Fast and Accurate Text-driven 3D Stylization via Dynamic Textual Guidance
本文提出了一个用于文本驱动 3D 风格化任务的新框架,称为 X-Mesh,它采用了动态文本指导机制。在预测 Mesh 属性过程中,X-Mesh 引入早期的动态文本指导,从而实现更快的收敛速度和更精准的编辑效果。同时,在以往的文本驱动 3D 风格化任务中,往往需要人工进行效果评估,且缺乏标准的测试数据集,因此难以进行公平的比较。为此,本文提出了一个专门用于文本驱动 3D 风格化任务的测试集,并基于 CLIP 模型提出了两个定量指标,以便更好地促进该领域的研究。
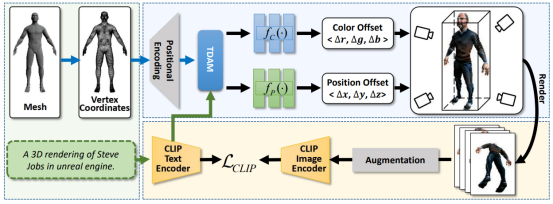
该论文由厦门大学信息学院人工智能系2020级研究生马祎炜、厦门大学人工智能研究院2022级研究生张晓庆与其导师孙晓帅副教授(通讯作者),纪荣嵘教授,宁德时代江冠南博士等合作完成。
5.Automatic Network Pruning via Hilbert-Schmidt Independence Criterion Lasso under Information Bottleneck Principle
大多数现有的神经网络剪枝方法都是手工设计其重要性标准和结构以进行剪枝。这对于启发式和专家经验有着严重的依赖。本文通过引入基于信息瓶颈理论的一个原则性和统一性框架来解决这个问题,从而进一步指导我们实现自动剪枝方法。具体而言,我们首先从信息瓶颈的角度对通道剪枝问题进行了建模,然后在一定条件下通过解决希尔伯特-施密特独立准则(HSIC)Lasso问题来实现信息瓶颈原则。基于理论指导,我们提供了一个通过搜索全局惩罚系数来实现自动剪枝的方案。通过广泛的实验证明,我们的方法在各种基准网络和数据集上取得了SOTA的性能。例如,使用ResNet-50,在去除50%的参数的同时,我们减少56%的计算量,并且剪枝后的模型在ImageNet上的准确率仅仅损失了0.08%。
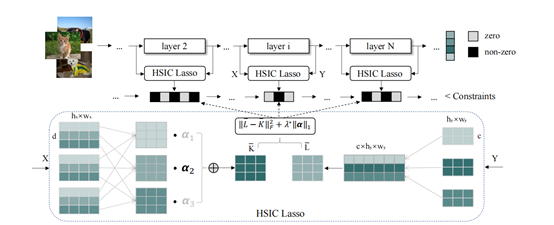
该论文由厦门大学信息学院人工智能系2021级硕士生郭颂,2021级硕士生张雷,鹏城实验室郑侠武博士,Samsara王言博士,阿里巴巴李与超,晁飞副教授,张声传助理教授(通讯作者),纪荣嵘教授等合作完成。
6.SMMix: Self-Motivated Image Mixing for Vision Transformers
CutMix是一种重要的数据增强策略,对于视觉变换器(ViTs)的性能和泛化能力至关重要。然而,混合图像与相应标签之间的不一致性会损害其有效性。现有的CutMix变体通过生成更一致的混合图像或更精确的混合标签来解决这个问题,但不可避免地引入了沉重的训练开销或需要额外的信息,削弱了使用的便利性。为此,我们提出了一种新颖而有效的自我激励图像混合方法(SMMix),该方法通过训练模型本身来激励图像和标签的增强。具体而言,我们提出了一种最大-最小注意力区域混合方法,丰富了混合图像中的注意力聚焦对象。然后,我们引入了一种细粒度标签分配技术,通过细粒度监督来共同训练混合图像的输出标记。此外,我们设计了一种新颖的特征一致性约束,以使混合图像和未混合图像的特征对齐。由于自我激励范式的微妙设计,我们的SMMix在训练开销更小且性能更好方面具有显著优势,特别是在ImageNet-1k数据集上,SMMix将DeiT-T/S/B,CaiT-XXS-24/36和PVT-T/S/M/L的准确性提高了超过+1%。我们的方法的泛化能力还在下游任务和分布外数据集上得到了证明。
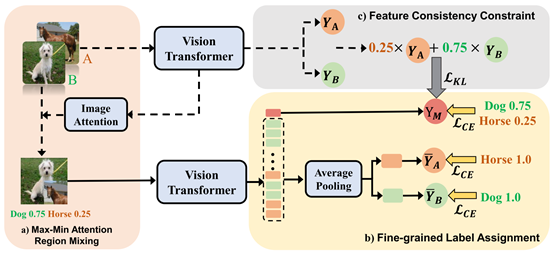
该论文由厦门大学信息学院人工智能系2021级硕士生陈锰钊与其导师纪荣嵘教授(通讯作者),腾讯优图林明宝,2022级硕士生林志航,2022级博士生张玉鑫,晁飞副教授等共同合作完成。
7. DiffRate: Differentiable Compression Rate for Efficient Vision Transformers
令牌压缩旨在通过修剪(丢弃)或合并令牌来加速大规模视觉变换器(例如ViTs)。这是一项重要而具有挑战性的任务。虽然最近的先进方法取得了巨大的成功,但它们需要精心制定压缩率(即要删除的令牌数量),这是一项繁琐的工作,并导致次优的性能。为了解决这个问题,我们提出了可微分压缩率(DiffRate),这是一种具有几个吸引人的特性的新型令牌压缩方法。首先,DiffRate能够将损失函数的梯度传播到压缩率上,而在以前的工作中,压缩率被视为不可微分的超参数。在这种情况下,不同的层可以自动学习不同的压缩率,无需额外的开销。其次,在DiffRate中,令牌修剪和合并可以自然地同时进行,而在以前的工作中它们是独立的。第三,广泛的实验证明DiffRate实现了最先进的性能。例如,将学习到的逐层压缩率应用于现成的ViT-H(MAE)模型,我们在ImageNet上实现了40%的FLOPs减少和1.5倍的吞吐量提高,而准确率仅下降了0.16%,甚至优于以前的经过微调的方法。
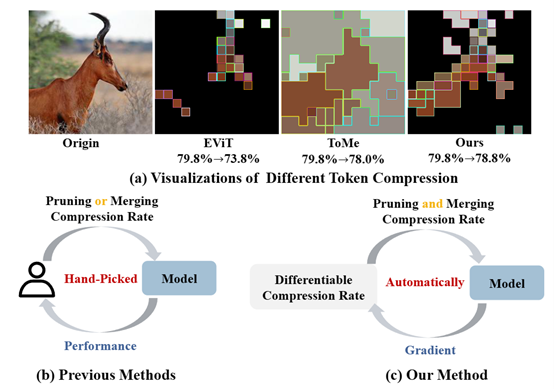
该论文由厦门大学信息学院人工智能系2021级硕士生陈锰钊与其导师纪荣嵘教授(通讯作者),晁飞副教授,上海人工智能实验室邵文琪,乔宇教授,罗平教授等共同合作完成。
8.AutoDiffusion:Training-FreeOptimizationofTimeStepsandArchitecturesforAutomatedDiffusionModelAcceleration
扩散模型在图像⽣成、图像超分辨率重建等多个领域都获得了令⼈印象深刻的效果,但是这类模型的⽣成过程包含多个时间步,每个时间步需要进⾏⼀次模型前向传播,这导致扩散模型⽣成速度远慢于其它⽣成模型。现有的扩散模型加速⽅法往往通过减少时间步数量以实现加速扩散模型,这些⽅法均使⽤均匀时间步。本⽂认为,均匀时间步不是最优的时间步序列,并且对于每个扩散模型都存在对应的最优时间步序列。因此,本⽂提出在⼀个统⼀的框架内为扩散模型搜索最优的时间步序列以及对应的模型结构,并将这套框架称为AutoDiffusion。AutoDiffusion的搜索空间同时包括扩散模型的时间步和模型结构,因此可以从两个正交的⻆度加速扩散模型。同时,AutoDiffusion使⽤进化算法作为搜索策略,并使⽤FID指标作为性能评估策略,以实现准确快速的搜索。实验结果表⽰,AutoDiffusion可以显著提⾼扩散模型的⽣成速度与⽣成质量。在ImageNet64x64上,AutoDiffusion在时间步数量为4的条件下搜索得到的最优序列的FID为17.86,相对于均匀时间序列(FID=138.66)极⼤提⾼了扩散模型在极少时间步情况下的⽣成质量。
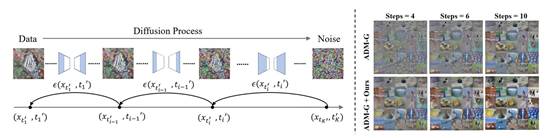
该论⽂由厦⻔⼤学信息学院⼈⼯智能系2022级研究⽣李漓江与其导师晁⻜副教授(通讯作者),纪荣嵘教授等共同合作完成。