在刚刚公布的ECCV评审结果中,厦门大学媒体分析与计算实验室(MAC)共有十篇论文被接收。ECCV(European Conference on Computer Vision) ,欧洲计算机视觉国际会议,每两年举办一次,是计算机视觉三大会议之一。2022 ECCV论文总投稿数8000多篇,共接收论文1629篇,接收率不到20%。
1. SeqTR: A Simple yet Universal Network for Visual Grounding (Oral)
现有视觉定位任务的模型架构和目标函数设计复杂度较高,且指向型检测和分割子任务需不同的分支处理粗粒度(边界框)和细粒度标注(二进制掩码)。针对这些问题,论文提出了一种新颖的序列化建模范式,创新性的将指向型目标检测和分割问题转化为分类问题,通过自回归方式逐步预测采样点的横纵坐标。该范式能够统一模型架构,无需额外的分支,训练仅采用经典的交叉墒分类目标函数,大幅简化目标函数,降低训练成本,且推理速度达到一阶段模型实时推理速度。
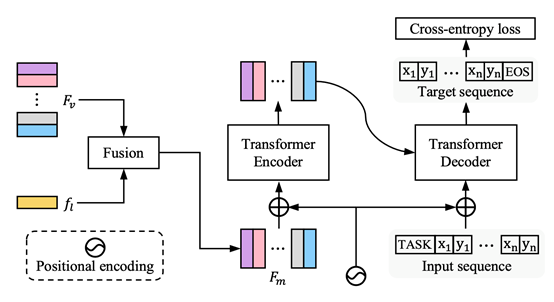
论文提出的SeqTR网络首先采用DarkNet视觉编码器和LSTM文本编码器提取图像级别、单词级别的特征。单模态特征经过点乘和非线性激活后形成多模态特征,送入Transformer编码器中进一步更新。其次为每个任务配置一个可学习的嵌入向量,通过解码器对更新后的多模态特征进行解码,逐步预测出真实标签所对应序列其中的坐标点。对于边界框,序列由左上角和右下角点坐标组成;对于二进制掩码,序列由在mask轮廓边缘均匀采样的点组成。在RefCOCO、RefCOCO+、RefCOCOg、Flickr30K等数据集上,论文方法取得了最佳性能,证明了基于序列化建模的简单、通用的视觉定位范式的有效性。
该论文由2020级硕士生朱朝阳,周奕毅副教授,曹刘娟副教授(通讯作者),纪荣嵘教授,腾讯优图实验室沈云航,陈超等合作完成。
2. Black-Box Dissector: Towards Erasing-based Hard-Label Model Stealing Attack
该论文针对模型窃取攻击任务,发现之前方法都没有关注只有硬标签可用这种场景下的攻击,并且之前方法在这种场景下的性能较差。为了解决这个问题,本文设计了一种先验驱动的擦除策略,这种策略根据模型的类别激活图(CAM)擦除样本上的高响应区域,之后重现查询模型获得新的标签,从而挖掘出硬标签下掩盖的其它类别相似性信息。除此之外,本文还使用了一种基于擦除的自知识蒸馏模块,这个模块可以很好的提高模型的泛化能力,从而增强模型的鲁棒性。改方法在四个常用数据集(CIFAR10、SVHN、Caltech256和CUBS200)上取得的效果均大大优于之前的方法。
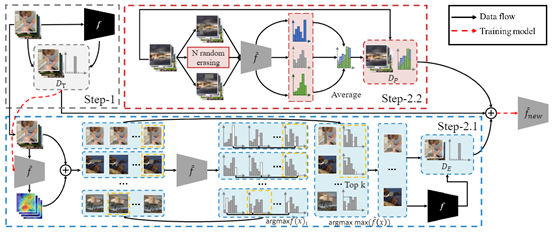
论文由2019级硕士生王熠旭,2019级博士生李杰,纪荣嵘教授,NII(日本国立情报学研究所)刘弘,Pinterest(拼趣)王言,腾讯优图实验室吴永坚等合作完成。
3. ECO-TR: Efficient Correspondences Finding Via Coarse-to-Fine Refinement
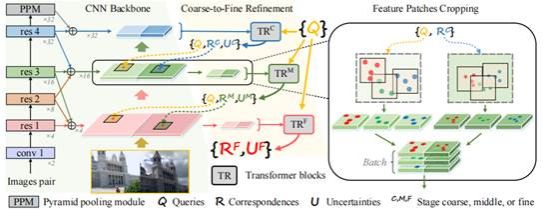
该论文针对传统查询式图像匹配方案的方法使用迭代推理速度过慢的问题,考虑使用多层级特征融合并使用特征复用策略,提出了一种端到端的基于查询的图像匹配方案。通过融合不同尺度感受野下的特征组合,通过Transformer端到端层级回归对应匹配位置,同时预测匹配对的不确定性。此外,通过使用适应性聚类策略进行查询匹配对聚类,并将聚类后特征和查询匹配对进行中等、精细两个阶段微调得到最终精确匹配输出。该模型较其他迭代式查询匹配方案,随查询点数增加可加速数十到上百倍,且在精度方面没有明显损失。基于该方案的比赛策略获得了CVPR2022 IMC挑战赛的top1%(5/642)。论文由2019级硕士生檀东力和优图实验室研究员刘姜江,与纪荣嵘教授(通讯作者)等共同完成。
4. Dynamic Dual Trainable Bounds for Ultra-low Precision Super-Resolution Networks
轻量超分辨率(SR)模型因其在移动设备中的适用性而备受关注。许多工作采用网络量化来压缩SR模型。然而,当使用低成本分层量化器将SR模型量化到超低精度(例如,2位和3位)时,这些方法的性能严重下降。在本文中,我们发现性能下降源于SR模型中分层对称量化器和高度不对称激活分布之间的矛盾。这种差异导致重建图像中的量化级别浪费或细节损失。因此,我们提出了一种新的激活量化器,称为动态双可训练边界(DDTB),以适应激活的不对称性。具体来说,DDTB在以下方面进行了创新:1)具有可训练上下限的分层量化器,以解决高度不对称的激活问题。2) 动态门控制器在运行时自适应调整上下限,以克服不同样本上剧烈变化的激活范围。为了减少额外开销,动态门控制器被量化为2位,并根据引入的动态强度仅应用于SR网络的部分层。大量实验表明,我们的DDTB在超低精度方面表现出显著的性能改进。例如,当将EDSR量化为2位并将输出图像放大到x4时,我们的DDTB在Urban100基准上实现了0.70dB的峰值信噪比增加。
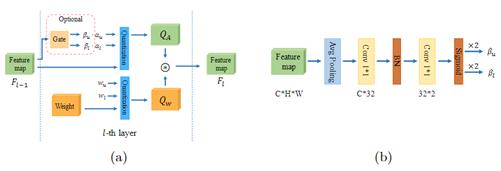
该论文由2021级博士钟云山,2018级博士林明宝,2021级硕士李训潮,纪荣嵘教授(通讯作者)等合作完成。
5. Fine-grained Data Distribution Alignment for Post-Training Quantization
本文提出了一种基于生成数据的后训练量化方法。传统的后训练方法只利用了一个数据量很有限的矫正数据集,这些方法的性能也受限于数据量少的问题。本文利用无数据量化中生成合成数据的方法来生成假数据,从而来补充数据不足的问题,从而提高后训练量化网络的性能。具体来说,本文提出了一种细粒度数据分布对齐(FDDA)方法来提高假数据的质量,该方法基于两个批量归一化统计(BNS)的重要性质:即类间分离和类内融合。为了保存这个细粒度分布信息:1)我们并提出一个BNS集中损失,该损失强制不同类别的合成数据分布接近他们自己的对应的BNS中心。2) 我们提出BNS失真损耗,该损失强制同一类的合成数据分布靠近加入了噪声的BNS中心。通过引入这两种细粒度损耗,我们的后训练量化方法在ImageNet上显示了最先进的性能,尤其是在网络的第一层和最后一层时也被量化到低位的时候。该论文由2021级博士钟云山,2018级博士林明宝,2021级硕士陈猛钊,纪荣嵘教授(通讯作者)等合作完成。
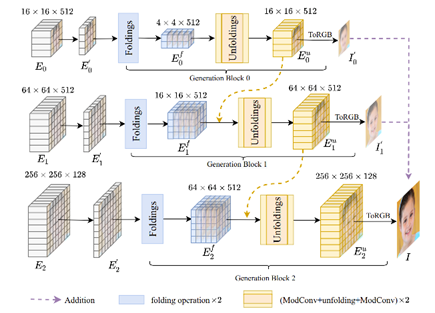
6. PixelFolder: An Efficient Progressive Pixel Synthesis Network for Image Generation
像素合成是一种极具潜力的图像生成范式,其可以很好地利用像素级别的先验知识以促进图像生成的质量。然而现有的像素合成方法仍然存在着显存占用和计算开销过大的问题。该论文提出一种渐进式像素合成方法用于高效的图像生成任务,称为PixelFolder。PixelFolder将图像生成任务定义为一个渐进式像素回归问题,其通过多阶段结构合成图像,从而极大地降低了由于较大张量变换带来的计算开销问题。除此之外,该论文还引入一种像素折叠操作用于进一步提升模型效率并保证所有像素在端到端回归中的独立性。基于以上极具创新的设计,该论文极大的减少了像素合成的计算开销。相比于目前最优的像素合成方法CIPS,该论文降低了90%的计算量和57%的参数量。为了验证模型性能,该论文进一步在两个基准数据集FFHQ、LSUN Church上进行一系列实验。实验结果显示,在更少的模型开销的基础上,PixelFolder在这两个数据集上均取得超越SOTA的性能。同时相较于目前主流的图像生成模型StyleGAN2,该论文同样降低了约74%的计算量和36%的参数量。这些结果都强有力的验证了该论文所提出的PixelFolder的有效性。
该论文由2020级硕士生何晶,周奕毅副教授(通讯作者),孙晓帅副教授,纪荣嵘教授,腾讯优图实验室张琪等合作完成。
7. An Information Theoretic Approach for Attention-Driven Face Forgery Detection
该论文旨在解决伪造人脸检测中,基于CNN的启发式方法对细微高信息量区域的忽略问题。论文将自信息作为一种度量引入伪造脸检测任务中。该度量和注意力机制结合后可以增强检测网络对高信息量伪造区域的特征提取,以提升检测性能和泛化性。同时提出了一种跨层间的自信息聚合机制用于缓解卷积神经网络下采样操作对细微伪造区域的擦除问题,进一步加强对伪造区域特征的保留和提取。
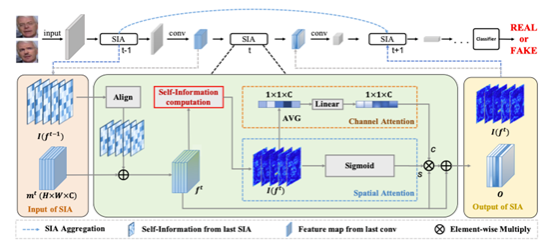
本方法被归结为一个即插即用的注意力模块。具体来说,输入特征图首先计算自信息,用于将所有候选的高频伪造信息增强,之后我们将自信息与双流注意力机制结合,分别在通道维度和空间维度计算注意力值。该注意力值和原特真图相乘后可以将潜在的高信息量区域增强,让网络可以挖掘出更多易被忽略的伪造信息。于此同时,当前层的自信息特征图将会跨层连接到下一个层注意力模块,这样浅层细微伪造信息将被保留。我们在多个伪造脸检测数据集上验证了我们的方法,实验表明我们的方法在增加少量参数的情况下可以提升骨架网络的检测性能和泛化性。
该论文由2021级博士生孙可,孙晓帅副教授(通讯作者),纪荣嵘教授,日本国立信息学研究所的刘弘,腾讯优图的姚太平等合作完成。
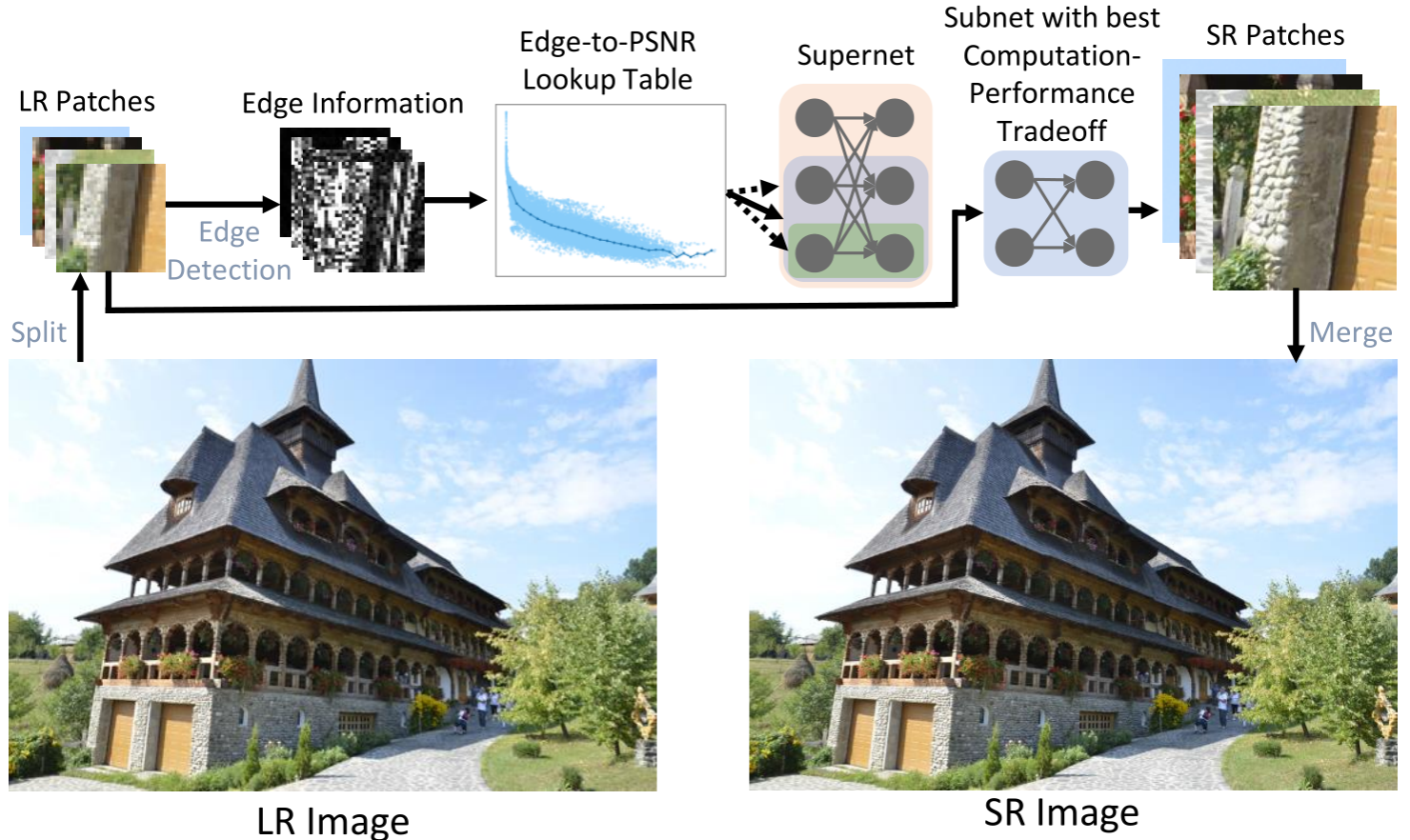
8. ARM: Any-Time Super-Resolution Method
该论文由信息学院计算机科学系2020级硕士陈柏宏、2018级博士林明宝、曹刘娟副教授(通讯作者)、纪荣嵘教授等合作完成。本文提出了一种任意时间超分方法(ARM)来解决传统超分模型无法在推理时根据推理样本和可用计算资源动态调整计算开销的问题。该算法训练了一个包含不同大小子网的ARM超网,并构建了一个Edge-to-PSNR查找表和一个子网选择函数。在推理时,不同复杂度的图像patch根据查找表预测的PSNR和子网选择函数,被分配到不同大小的子网中,以获得更好的计算量-性能的权衡。在主流的超分数据集上进行了广泛的实验,验证了该算法的有效性。
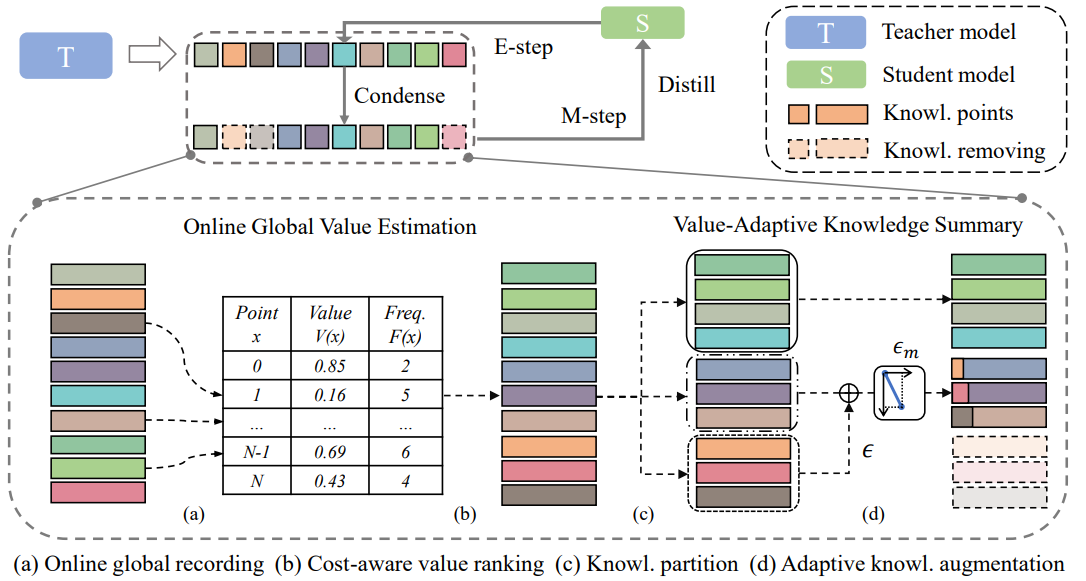
9. Knowledge Condensation Distillation
本文中,从两个新颖的视角出发,我们提出了一种基于知识浓缩蒸馏的高效蒸馏方法:1)学生的学习进展向教师反馈以动态地影响教师的知识传递。2)学生主动识别出对自身学习更有价值的知识点并逐步总结出紧凑的核心知识集以提升学习效率。具体地,我们将每个样本上的知识价值编码为一个隐变量,并以此建立一个期望最大化(EM)框架交替地执行教师知识集的浓缩和学生模型的蒸馏。本文的方法可作为一个即插即用的方案广泛地建立在当前的蒸馏方法上,提升它们性能的同时几乎不带来额外的训练参数和计算开销。在基准数据集上的实验结果表明,本文方法在精度和效率方面都超过当前最优的蒸馏方案。该论文由厦门大学智能数据分析与处理实验室同MAC实验室2018级博士林明宝,曹刘娟副教授共同合作完成
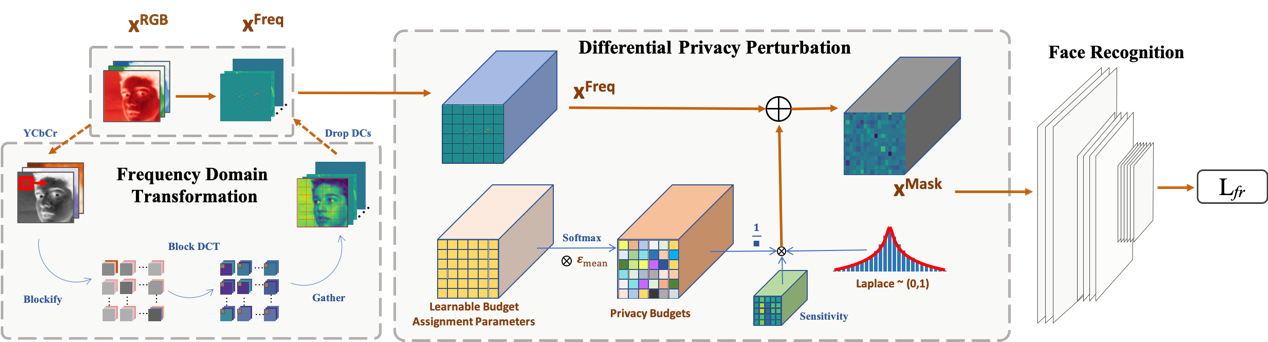
10.Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
人脸识别技术在很多领域得到了应用,然而人脸图像往往需要传输到具有高计算能力的第三方服务器进行推理,一方面所传输的人脸图像在视觉上揭示了用户的身份信息,另一方面不受信任的服务提供商和恶意用户都可能增加个人隐私泄露的风险。为了解决这个问题,本文首先将原始图像转换到频域并去除可视化信息较多但对识别任务影响较小的直流分量。之后针对传统的差分隐私方法对于每一个像素点的隐私分配预算相同从而忽视了像素重要性这一个问题,提出了一个具有可学习的频域隐私预算分配模块,通过该模块可以最大化每个特征像素点对于识别任务的作用从而减少一定的精度损失,并且由于差分隐私理论的保障可以防止频率特征被复原。本文在多个常用的人脸识别数据集上进行了广泛的实验,实验结果表明,本文的方法相比于其他隐私保护方法隐私保护能力更强且人脸识别精度更高。
该论文由腾讯优图实验室季家桢和2019级硕士生王欢,张声传助理教授、曹刘娟副教授、纪荣嵘教授等合作完成。