近日,ACM International Conference on Multimedia (简称ACM MM)公布了2022年论文的收录结果,厦门大学媒体分析与计算实验室共四篇论文被接收。ACM MM是计算机学科领域的顶级会议,被中国计算机学会(CCF)列为A类会议。本次会议共收到有效稿件2473篇,最终录用690篇,录用率为27.9%,会议将于2022年10月10-14日在葡萄牙里斯本召开。
1. X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval
该论文旨在解决视频-文本检索任务中,基于粗粒度的特征对比方法无法挖掘细粒度交互的问题。论文提出了一种后交互形式的多粒度对比框架X-CLIP,该方法充分考虑了视频-句子(粗粒度)、视频-单词(跨粒度)、帧-句子(跨粒度)、帧-单词(细粒度)级别的对比,这种多粒度的对比方式能够最大程度的挖掘不同级别特征之间的交互,从而过滤掉视频和句子中的无效信息,进行更加有效的跨模态对比。首先采用CLIP的文本编码器和视觉编码器提取句子级别、单词级别和帧级别的特征。为了使帧级别特征具有时间维度上的交互,它们被进一步送入时间编码器中得到新的帧级别和视频级别特征。四种级别的特征进行跨模态的多粒度对比,可以得到视频-句子相似度、视频-单词相似度(向量)、帧-句子相似度(向量)、帧-单词相似度(矩阵)。相似度向量和矩阵被进一步送入到AOSM模块进行相似度的聚合,得到实例级别相似度。最后,综合考虑四种级别的相似度得到最终的实例级别相似度。该方法通过轻量级的多粒度对比,在五个视频-文本检索数据集(MSRVTT,MSVD,LSMDC,DiDeMo和ActivityNet)上实现了最佳的性能。

该论文由2020级硕士生马祎炜,孙晓帅副教授(通讯作者),纪荣嵘教授,阿里巴巴达摩院徐国海,严明等合作完成。
2. Towards Open-Ended Text-to-Face Generation, Combination and Manipulation
现有的基于预训练生成器的人脸图像生成、编辑方法推理速度慢、生成效率低,并且编辑只能局限于某些特定的属性。为了解决这些问题,本文提出了一种开放式的端到端文本到人脸图像的生成、组合和编辑方法。通过跨模态的对比学习训练一组文本、图像编码器,构建一个多模态隐空间,拉近图像与其描述文本的隐码表示在隐空间中的距离。文本的隐码经过MLP后得到多个风格编码,并将其分别送入基于风格的生成器的不同分辨率层,生成与文本描述匹配的人脸图像。通过对不同文本描述的隐码进行加权组合,可以实现图像组合,生成人脸图像同时具备不同文本中描述的属性,且权重越高其描述的属性体现得越明显。对于人脸图像编辑,提出的OpenEditor模块可以过滤原图或者原描述隐码中与编辑属性无关的信息,并根据生成器不同分辨率层控制不同属性的特性调整隐码,实现人脸图像的编辑。在MMCelebA数据集上,论文方法取得了最佳性能,生成质量高、泛化能力强,同时与基于隐码优化的方法相比,推理速度提高了三个数量级。

该论文由2019级博士生彭军,周奕毅副教授(通讯作者),孙晓帅副教授,纪荣嵘教授,Pinterest(拼趣)王言,腾讯优图实验室吴永坚等合作完成。
3. Dynamic Prototype Mask for Occluded Person Re-Identification (发表于ACM MM 2022)
该论文针对遮挡行人重识别问题提出了一种动态原型掩码(Dynamic Prototype Mask)的策略,将遮挡行人重识别问题转化为是对完整特征原型在通道上的进行的筛选和对齐问题。通过这种策略,该模型不需要像以往的方法一样依赖于额外的网络来提供身体信息就能够实现针对遮挡行人自动化的对齐训练,大大降低了模型训练的难度和复杂度。在多个公开的遮挡行人重识别数据集的测试中,所提出的模型都取得了最佳的性能。

该论文由2020级博士生谭磊,戴平阳高级工程师(通讯作者)、纪荣嵘教授、腾讯优图实验室总监吴永坚等合作完成。
4. Searching Lightweight Neural Network for Image Signal Processing
本文提出一种针对图像信号处理的神经网络自动搜索框架(Neural Architecture Search for Image Signal Processing,简称NAS-ISP )。NAS-ISP采用权重共享策略,将架构搜索解耦为超级网络训练和硬感知进化搜索两个阶段。只需要对ISP模型进行一次训练,NAS-ISP就可以在多个设备上快速导出高性能但低计算量的模型。实验表明,搜索到的神经网络在图像质量和模型复杂性之间有很好的权衡,即与最先进的网络相比,在减少90%以上的计算量的同时保持了优异的重建质量。
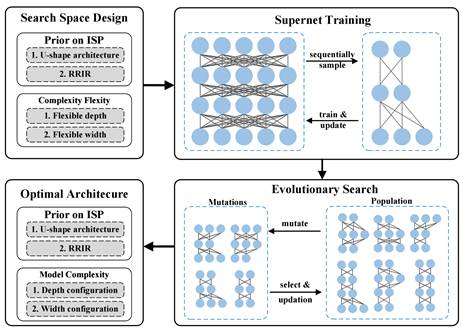
本文的第一作者是信息学院人工智能系2021级博士生林豪佳,2022级硕士生李漓江为共同一作。 通讯作者是信息学院纪荣嵘教授。
5.Learning Dynamic Prior Knowledge for Text-to-Face Pixel Synthesis
该论文旨在解决文本到人脸图像生成任务中忽视先验知识的问题。论文提出了一种动态利用文本中先验知识的端到端像素生成网络PixelFace。给定一个文本描述,该方法充分挖掘描述中属性语义及其位置的先验知识,并根据先验进行像素回归,生成与描述语义对齐的人像。PixelFace首先利用正弦函数获得傅里叶特征作为初始的图像特征,并采用文本编码器获取单词级别的文本特征;其次经过基于跨模态注意力机制与残差连接的动态知识生成模块获取先验特征;傅里叶特征、先验特征与可学习的坐标特征融合得到像素嵌入;然后将其与从随机噪声采样的隐码一起送入像素回归网络。像素回归网络采用三阶段框架,以像素嵌入为输入,不同阶段的输出相加得到最终的生成人像。实验表明,本文提出的方法不仅可以实现高质量、语义对齐的文本到人脸生成,并且生成图像中的语义属性及其位置与动态知识生成模块挖掘到的先验知识相吻合,证明了该模块的有效性。
该论文由2019级博士生彭军,周奕毅副教授(通讯作者),孙晓帅副教授,纪荣嵘教授,腾讯优图实验室沈云航等合作完成。
