近日,国际顶级学术期刊 《IEEE Transactions on Pattern Analysis and Machine Intelligence》(TPAMI)和《IEEE Transactions On Image Processing》(TIP)接收了厦门大学信息学院纪荣嵘教授团队的多项最新研究成果。
1. “HGNN+: Towards General Hypergraph Neural Networks”。(发表于TPAMI 2022)
该论文提出了一种通用的超图神经网络设计架构的范式,系统性地将超图神经网络框架划分成超图建模和超图卷积两个部分,并提出了一种自适应超边组融合的策略来平衡不同类型的高阶关联对下游任务的影响。论文充分对比了图与超图的关系、图卷积与超图卷积的关系,并从理论上证明了超图拥有远比图强大的建模和表达能力,以及在超图中的超边退化成图中的边的时候超图卷积也能自然的退化成经典的图卷积。
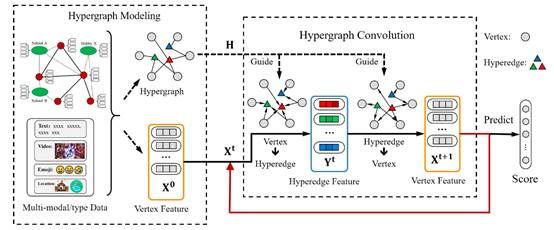
论文首先将超边组的建立归纳成四种:基于成对关联、基于数据属性、基于多跳关联以及基于特征的K近邻,并对每种超边组的构建方式进行了详细的说明。接下来从谱域和空域分别提出了两种超图卷积。其中空域的超图卷积受经典的信息通路启发被定义成了一种两阶段的消息聚合架构。这种两阶段的消息聚合架构可以很容易去解决更多类型的超图,极大地拓展了超图神经网络方法的应用场景。在7个数据集(包括论文引用网络、社交网络、3D模型、电影关联及美食数据集)上的实验结果证明了论文提出方法的有效性。
该论文第一作者为清华大学高跃副教授,通信作者是厦门大学信息学院纪荣嵘教授。
2.“Knowing What to Learn: A Metric-oriented Focal Mechanism for Image Captioning”。(发表于TIP 2022)
该论文旨在解决图像描述在训练过程中样本学习难度不均衡的问题。传统方法在训练过程将所有样本同等对待,导致模型在难例样本上表现不佳,而这种现象随着模型的容量和复杂度增加,有增无减。这大大阻碍了图像描述模型的应用。因此,本文提出一种新的训练策略,在训练过程中,自适应增加难例样本的权重,鼓励模型适当的给予难例样本更多的关注,以提升在难例样本上的表现。
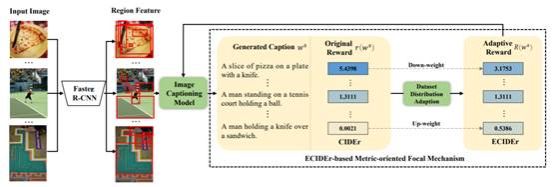
论文首先提出了基于度量导向的聚焦机制(Metric-oriented Focal Mechanism, MFM),用于图像描述任务中的难例样本挖掘。与现有的分类任务策略不同,MFM可以采用图像描述任务的生成性度量(如CIDEr, BLEU-N)来衡量样本的难度,然后在训练过程中提高难例样本的奖励权重。为了使MFM适用于不同的数据集和模型,并且无需繁琐的调参操作,我们进一步引入了一种称为有效CIDEr(ECIDEr)的自适应奖励指标,该指标在奖励估计过程中考虑了简单和困难示例的数据分布。我们在MS COCO数据集上进行了大量实验,结果表明,MFM在保持简单样本性能的同时,可以显著提高难例样本描述的生成质量。将基于ECIDEr的MFM应用在当前的SOTA方法上时,其性能优于所有现有方法,并在离线和在线测试中获得了最佳性能。
该论文由实验室2018级博士生纪家沂,2020级硕士生马祎炜,孙晓帅副教授(通讯作者),周奕毅副教授,纪荣嵘教授,腾讯优图实验室总监吴永坚等合作完成。
3. Oriented Representations for Unsupervised Domain Adaptation (发表于TIP 2022)
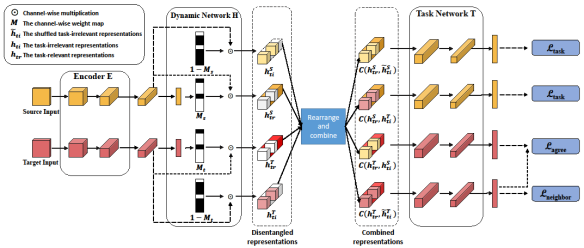
该论文旨在解决无监督领域适应中动态特征解耦表示问题。论文首先提出了无监督领域适应问题中“面向任务”的概念,接着提出了一个面向任务的动态特征解耦网络(DTDN)可以根据与任务的相关性概念,将特征解耦成“任务相关”和“任务无关”。其中,任务相关部分的特征同时具有任务有效性和领域无关性,而任务无关部分的特征则与之相反。通过该方法可以准确的将特征解耦,并利用同时具有有效性和领域无关性的任务相关特征完成无监督领域适应任务。该方法避免了手动设置参数的复杂度,在不需要生成模型或者解码器的情况下可以保留完整且有意义的信息,大大降低了训练成本。在多个领域适应数据集(行人重识别、车辆重识别、手写数字、办公图像数据集)上的实验结果证明了论文提出方法的有效性。
该论文由实验室戴平阳高级工程师,2018级硕士生陈珮娴,2020级硕士生吴穹,哈工大洪晓鹏教授,中科院叶齐祥教授,华为田齐教授,台湾清华大学林嘉文教授,纪荣嵘教授等合作完成。
4. Towards Lightweight Transformer via Group-wise Transformation for Vision-and-Language Tasks (发表于TIP 2022)
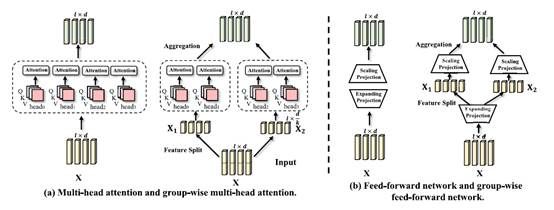
该论文提出了一种基于视觉——语言任务的轻量级Transformer模型,称为LWTransformer。本文为LW-Transformer 中分别设计了分组多头注意力(G-MHA) 以及分组前馈网络(G-FFN)。除了提高模型紧凑性外,LW-Transformer 还可以很好地保持原始Transformer 的工作机制。具体来说,Transformer 通过多头注意力设计在不同的特征子空间来捕捉多样化的特征依赖关系,从而保证了网络学习的有效性。 这些子空间是通过线性映射后对输入特征分组得到的。而分组变换也通过类似的方式来通过更多样化的特征空间来学习更有效的特征表示。因此,多头注意力机制和分组变换在原理上是一致的。而不同之处在于,G-MHA更进一步地在线性映射之前就降特征进行分组。这样做的好处在于既不会改变特征维度,也不会改变注意力建模的方式,从而保证了模型的学习能力。同时,G-FFN 通过相同的方式在很大程度上减少了计算量和参数的同时,也保持了前馈网络的维度。本文对LWTransformer在多个多模态数据集和任务上进行了验证。实验结果表明,在减少了高达45% 的参数和28% 的计算量的情况下,LW-Transformer 仍然在六个数据集以及三个视觉语言任务上上取得了与原始Transformer 非常接近的性能,甚至在某些数据集上超越了原始的Transformer。
该论文由实验室2021级博士生罗根,孙晓帅副教授,周奕毅副教授(通讯作者),纪荣嵘教授,腾讯优图实验室总监吴永坚等合作完成。