近日,厦门大学媒体分析与计算实验室八篇论文被计算机视觉和模式识别领域国际顶级会议CVPR2021录用。CVPR(IEEE Conference on Computer Vision and Pattern Recognition,即IEEE国际计算机视觉与模式识别会议)是由IEEE举办的计算机视觉和模式识别领域的顶级会议,是计算机视觉方向的三大顶级会议之一。目前在中国计算机学会(CCF)推荐国际学术会议的排名中,CVPR为人工智能领域的A类会议。CVPR2021于2021年3月1日公布接收结果,一共有1663篇论文被接收,接收率为23.7%。
被录取的8篇论文分别如下:
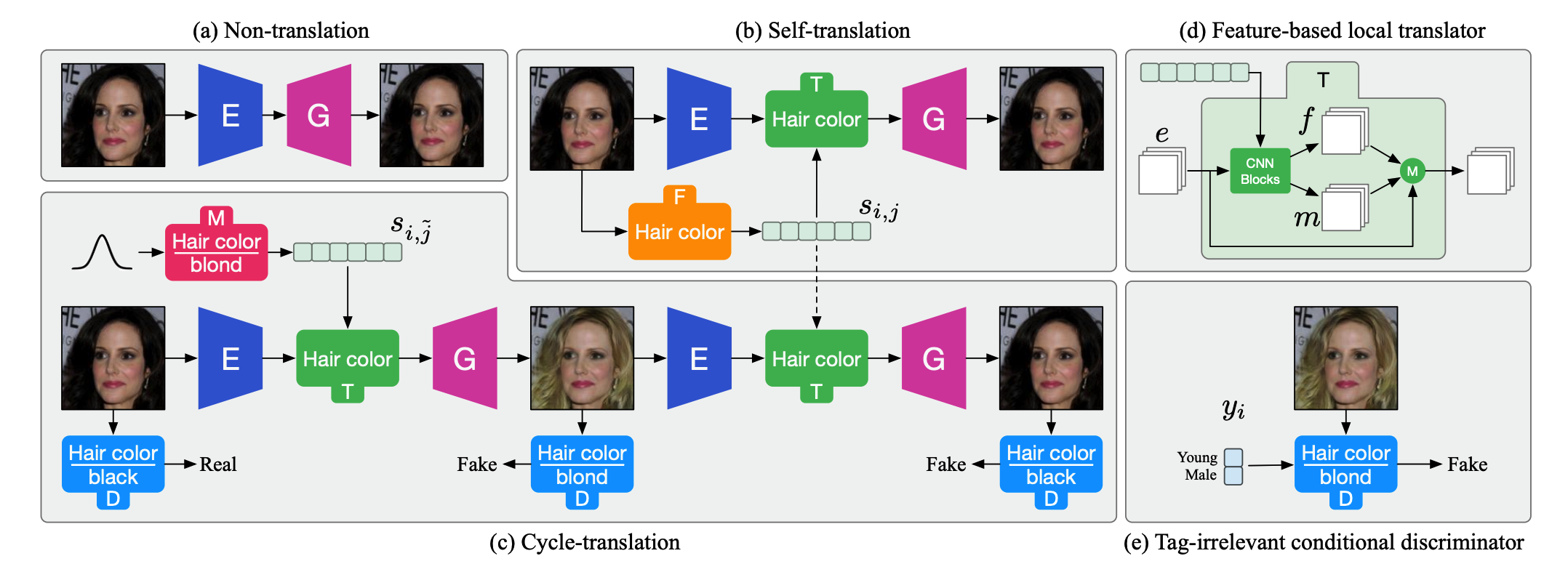
1. Image-to-image Translation via Hierarchical Style Disentanglement(Oral)
该论文由信息学院计算机系2019级硕士李新阳,张声传助理教授(通讯作者),2019级博士胡杰,曹刘娟副教授,西安交通大学教授洪晓鹏,毛旭东副教授,纪荣嵘教授和腾讯优图实验室等合作完成。本文提出了一种层级风格解耦的办法,来解决图像到图像翻译领域多样性不可控的问题。其中,原本的标注被组织成为自顶向下依次是独立标签,互斥属性和解耦风格的层次结构。论文为此重新设计了相应的结构模块和翻译流程。在人脸属性编辑的定性定量比较中均获得了最先进的效果。代码已经开源。
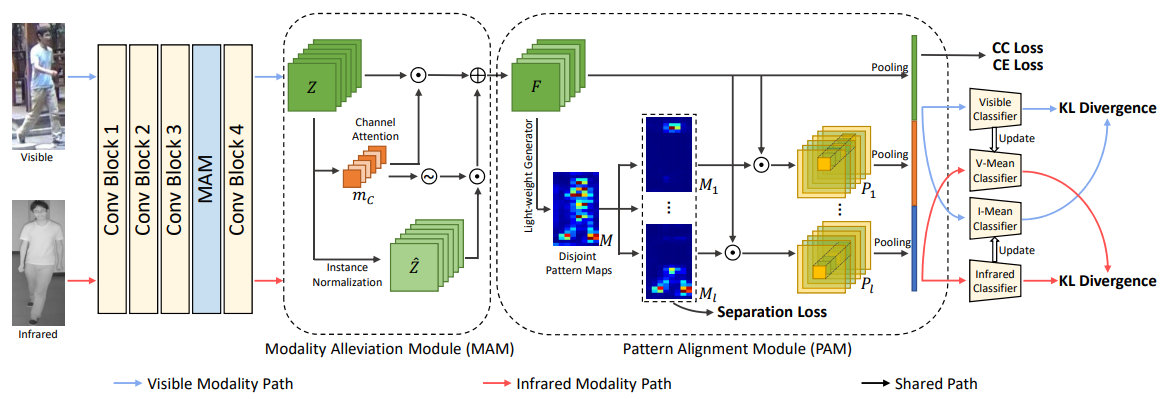
2. Discover Cross-Modality Nuances for Visible-Infrared Person Re-Identification (Oral)
该论文由信息学院人工智能系2020级硕士生吴穹与其导师纪荣嵘教授,戴平阳高级工程师(通讯作者)等合作完成。论文针对跨模态行人重识别问题,提出一个基于注意力机制的模态和人物细节双层面对齐网络。本文的核心思路在于通过Modality Alleviation Module和 Pattern Alignment Module两个模块,分别实现模态差异的消除和行人细微差异的挖掘,使模型能够抽取具有跨模态检索能力的特征。本模型在该任务的常用公开数据集上均取得了最优性能。
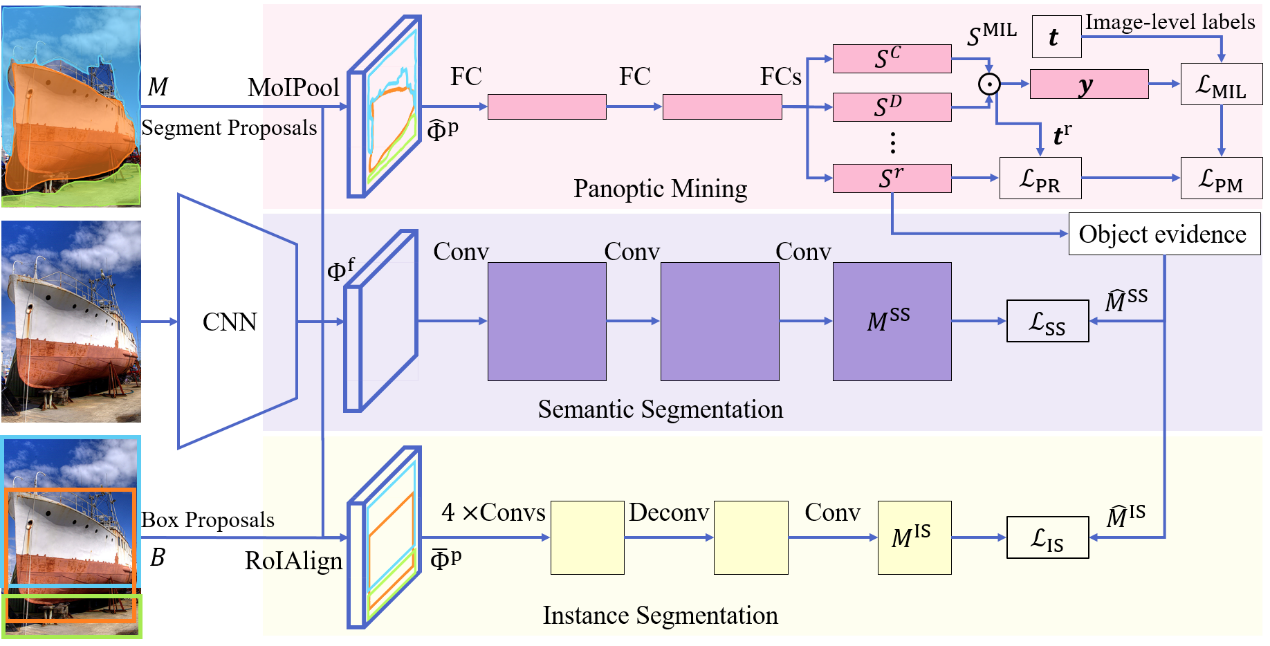
3. Toward Joint Thing-and-Stuff Mining for Weakly Supervised Panoptic Segmentation (Poster)
本文的第一作者是信息学院人工智能系2017级博士沈云航,通讯作者是信息学院人工智能系纪荣嵘教授。本文为弱监督全景分割提出了一个有效的联合物体与物质挖掘(Jointly Thing-and-Stuff Mining, JTSM)框架,该框架明确地推理了目标前景和物质背景之间的语义和共现关系。为此,算法设计了一种新颖的感兴趣掩模池化(Mask of Interest Pooling, MoIPool),用于提取任意形状分割的固定尺寸的像素精确特征图。MoIPool使全景挖掘分支能够利用多示例学习(Multiple Instance Learning, MIL),并以统一的方式识别物体和物质。算法引入并行实例和语义分割分支,通过自训练进一步修正的分割掩模,其让从全景挖掘中挖掘的掩模和以自底向上的目标线索协作生成伪真实标签,以提高空间一致性和轮廓定位。
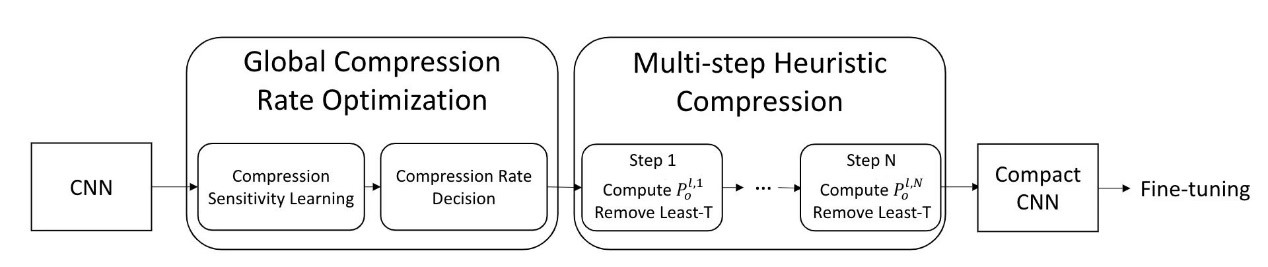
4. Towards Compact CNNs via Collaborative Compression (Poster)
该论文由信息学院人工智能系2017级硕士李与超和2015级博士林绍辉,与其导师纪荣嵘教授(通讯作者)等合作完成。本文提出了一种模型协同压缩方法,通过探索模型的稀疏性与低秩性,以同时使用剪枝和低秩分解压缩网络。该方法分为两个阶段,全局的压缩敏感性分析以决定各层的压缩率,局部的启发式多步压缩算法以同时进行剪枝和分解操作。本算法在多个数据集和模型上验证了其有效性。
5. RSTNet:Captioning with Adaptive Attention on Visual and Non-Visual Words (Poster)
该论文由信息学院人工智能系2019级硕士生张旭迎与其导师孙晓帅副教授(通讯作者),纪荣嵘教授等合作完成。本文提出了一个视觉信息增强和多模态信息敏感的Transformer结构,利用网格与网格之间相对位置的几何关系解决了特征展平操作造成的空间信息损失的问题,并且利用一个额外的注意力层度量视觉特征与语义特征的贡献,从而动态引导图像描述中视觉词和非视觉词的生成,在该任务的线上线下公开数据集上均证明了此模型的优势。
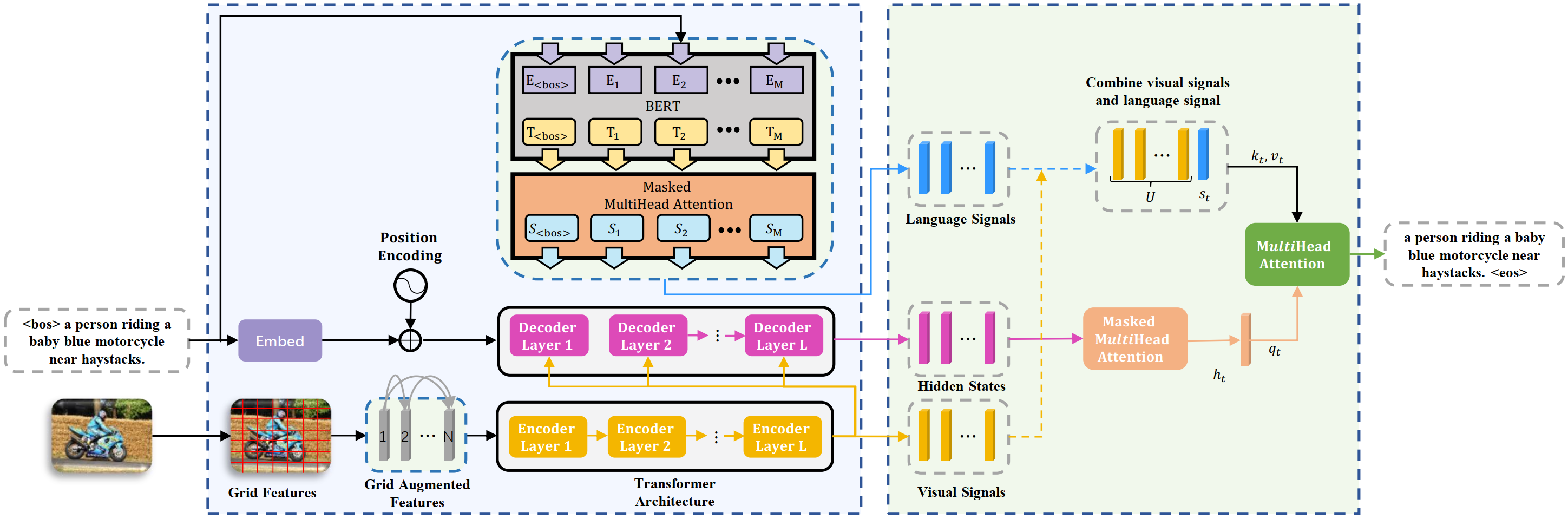
6. SDD-FIQA: Unsupervised Face Image Quality Assessment with Similarity Distribution Distance (Poster)
本文由腾讯优图实验室、广州大学、南京理工大学和曹刘娟副教授共同完成。 本文提出了一种新的无监督人脸质量评估算法SDD-FIQA,通过类内和类间的人脸相似度分布间的Wasserstein距离定义人脸质量。该方法生成的人脸质量伪标签可以更好的反映识别性能,在LFW、Adience、IJB-C等数据集上均取得了SOTA的效果。
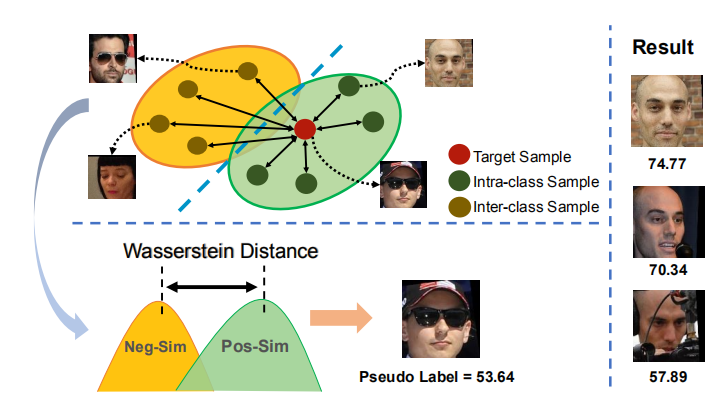
7. Beyond Max-Margin: Class Margin Equilibrium for Few-shot Object Detection (Poster)
本文由中国科学院大学和信息学院人工智能系纪荣嵘教授共同完成。本文提出了一种类间距平衡(CME)的方法,旨在以系统的方式同时进行特征空间划分的优化以及新颖类重建。 CME首先通过使用完全连接层将特征进行解耦,将小样本目标检测问题转换为小样本分类问题。 然后,CME通过在特征学习过程中引入简单有效的最大间距损失,为新颖类保留足够的余量空间。最后,CME通过以对抗性最小-最大的方式扰乱新颖类实例的特征来追求间距平衡。 在Pascal VOC和MS-COCO数据集上进行的实验表明,与使用两个基线目标检测器相比,CME可以显着提高性能(平均可达3~5%),达到了最先进的水平。
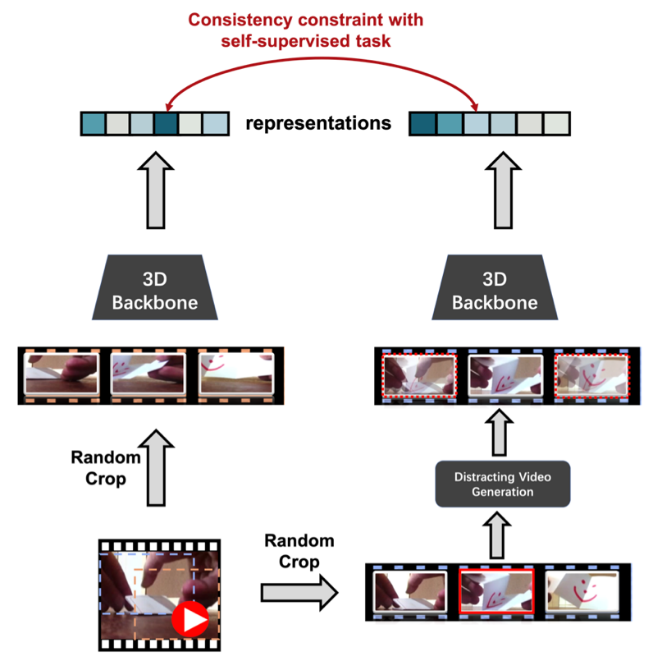
8. Removing the Background by Adding the Background: Towards Background Robust Self-supervised Video Representation Learning (Poster)
本文由腾讯优图实验室和信息学院人工智能系纪荣嵘教授共同完成。怎么平衡Spatial和Temporal一直以来是video understanding里至关重要的一个任务。在这篇工作中,我们希望通过自监督学习的方法来弥补主流3D CNN容易受场景干扰的问题。受到semi-supervised learning中关于denoise和consistency regularization的启发,我们的思路是合成一些background当作噪声,想办法让网络能弱化对background的依赖。在尝试了五种噪声生成方法之后,我们发现当采用Intra-video Frame 作为Noise的时候,运动模式得到了保留并且得到的图像和视频中其它图像的背景有相同的像素分布,进而可以让模型更加关注运动本身避免对背景的过渡依赖。该方法仅需几行代码就可以扩展到任意视频自监督的方法,同时在UCF101和HMDB51等多个数据集上均达到了SOTA的效果。目前代码已开源。